
你真的懂Transformer了吗?超全分析模型的参数量、计算量!
作者 | 丰臣英俊 编辑 | 野马逐星
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
本文只做学术分享,如有侵权,联系删文
前言
最近,OpenAI推出的ChatGPT展现出了卓越的性能,引发了大规模语言模型(Large Language Model, LLM)的研究热潮。大规模语言模型的“大”体现在两个方面:模型参数规模大,训练数据规模大。以GPT3为例,GPT3的参数量为1750亿,训练数据量达到了570GB。进而,训练大规模语言模型面临两个主要挑战:显存效率和计算效率。
现在业界的大语言模型都是基于transformer模型的,模型结构主要有两大类:encoder-decoder(代表模型是T5)和decoder-only,具体的,decoder-only结构又可以分为Causal LM(代表模型是GPT系列)和Prefix LM(代表模型是GLM)。归因于GPT系列取得的巨大成功,大多数的主流大语言模型都采用Causal LM结构。因此,针对decoder-only框架,为了更好地理解训练训练大语言模型的显存效率和计算效率,本文分析采用decoder-only框架transformer模型的模型参数量、计算量、中间激活值、KV cache。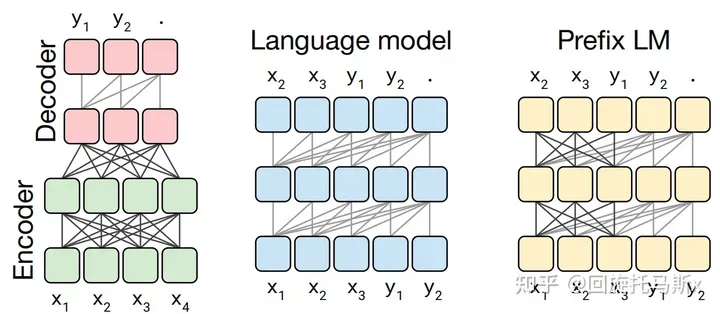 为了方便分析,先定义好一些数学符号。记transformer模型的层数为 ,隐藏层维度为 ,注意力头数为 。词表大小为 ,训练数据的批次大小为,序列长度为。
为了方便分析,先定义好一些数学符号。记transformer模型的层数为 ,隐藏层维度为 ,注意力头数为 。词表大小为 ,训练数据的批次大小为,序列长度为。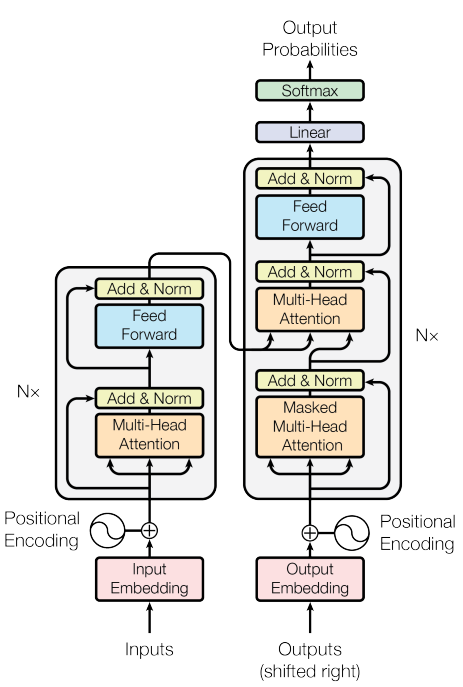
模型参数量
transformer模型由个相同的层组成,每个层分为两个部分:self-attention和MLP(各层包含layer normalization层)
Self-attention
Self-attention模块参数包含、、的权重矩阵、、、输出及偏置Bias,4个权重矩阵形状为,4个偏置形状为, Self-attention参数量为。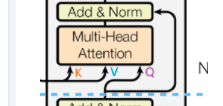
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask): # input_Q: [batch_size, len_q, d_model]
# input_K: [batch_size, len_k, d_model]
# input_V: [batch_size, len_v(=len_k), d_model]
# attn_mask: [batch_size, seq_len, seq_len]
residual, batch_size = input_Q, input_Q.size(0)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # Q: [batch_size, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # K: [batch_size, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask) # context: [batch_size, n_heads, len_q, d_v]
# attn: [batch_size, n_heads, len_q, len_k]
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v]
output = self.fc(context) # [batch_size, len_q, d_model]
return nn.LayerNorm(d_model).cuda()(output + residual), attn
MLP
MLP模块由2个线性层组成,一般地,第一个线性层先将维度从映射到,第二个线性层再将维度从映射到。第一个线性层权重的权重矩阵的形状为,偏置的形状为,第二个线性层权重矩阵的形状为,偏置形状为,MLP模块参数量为。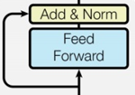
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False))
def forward(self, inputs): # inputs: [batch_size, seq_len, d_model]
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model).cuda()(output + residual) # [batch_size, seq_len, d_model]
LayerNorm
Self-attention和MLP各有一个layer normalization,包含2个可训练参数:缩放参数和平移参数,形状都是,2个layer normalization的参数量为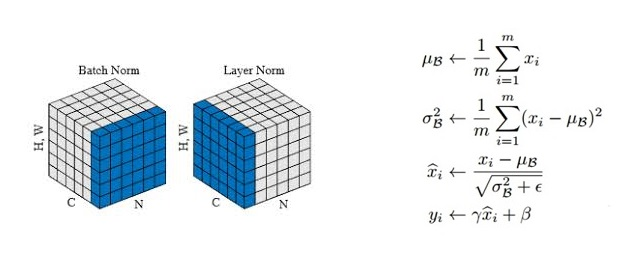
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-12):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
var = x.var(-1, unbiased=False, keepdim=True)
# '-1' means last dimension.
out = (x - mean) / torch.sqrt(var + self.eps)
out = self.gamma * out + self.beta
return out
总之,每个transformer层的参数量为,除此之外,词嵌入矩阵的参数量也较多,词向量维度通常等于隐藏层维度,词嵌入矩阵的参数量为;关于位置编码,如果采用可训练式的位置编码,会有一些可训练模型参数,数量比较少。如果采用相对位置编码,例如RoPE和ALiBi,则不包含可训练的模型参数。我们忽略这部分参数。
综上所述,层transformer模型可训练参数量为,当隐藏层维度较大时,可忽略一次项,模型参数量近似为。
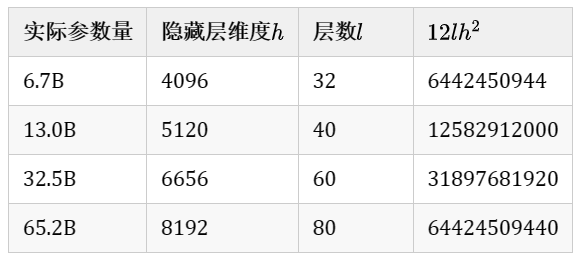
因此可估算不同版本LLama模型参数量,如下表所示:
计算量FLOPs估计
FLOPs,floating point operations,表示浮点数运算次数,衡量了计算量的大小。如何计算矩阵乘法的FLOPs呢?对于,计算AB需要进行n乘法运算和n次假发运算,共计2n次浮点运算,需要2n的FLOPS;对于,计算AB需要的浮点运算次数为2mnk
Input
在一次训练迭代中,假设输入数据的形状为,经embedding层得,矩阵乘法的输入和输出形状为,计算量为。
Self-attention
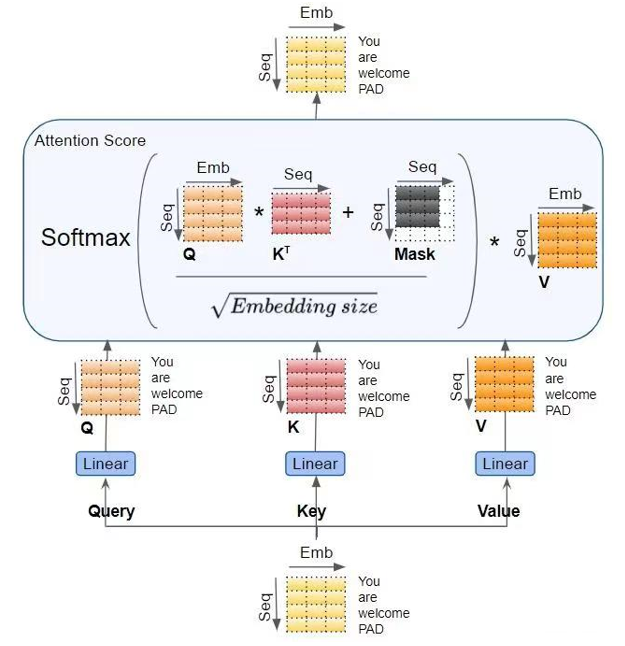
-
计算、、,矩阵乘法的输入和输出形状为,计算量为。
-
矩阵乘法的输入和输出形状为,计算量为。
-
计算在V上的加权,矩阵乘法的输入和输出形状为,计算量为。
-
attention后的线性映射,矩阵乘法的输入和输出形状为,计算量为。
MLP
MLP计算公式如下
。
2. 第二个线性层,矩阵乘法的输入和输出形状为,计算量为
将Self-attention和MLP计算量相加,得到每个transformer层的计算量大约为。
Output
另一个计算量的大头是logits的计算,将隐藏向量映射为词表大小,矩阵乘法的输入和输出形状为,计算量为。
因此,对于一个层的transformer模型,输入数据形状为的情况下,一次训练迭代计算量为
计算量与参数量关系
当隐藏维度比较大,且远大于序列长度时,我们可以忽略一次项,计算量可以近似为;前面提到当模型参数量为,输入的tokens数为,存在等式。我们可近似认为在一次前向传递中,对于每个token,每个模型参数,需要进行2次浮点数运算,即一次乘法匀运算和一次加法运算。
一次训练迭代包含了前向传递和后向传递,后向传递的计算量近似是前向传递的2倍(后向传播除了计算梯度之外,还需要存储梯度并进行参数更新)。因此,前向传递 + 后向传递的系数 =1+2=3 。一次训练迭代中,对于每个token,每个模型参数,需要进行 2∗3=6 次浮点数运算。
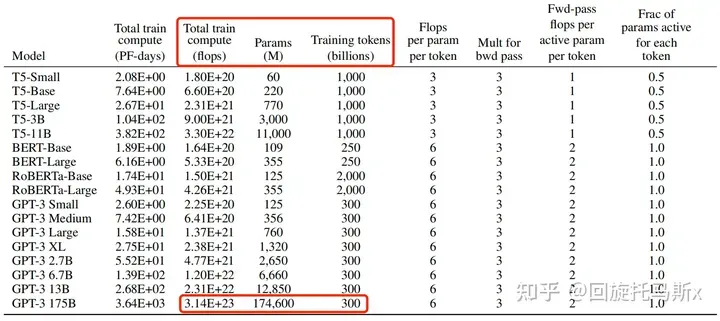
接下来,我们可以估计训练GPT3-175B所需要的计算量。对于GPT3,每个token,每个参数进行了6次浮点数运算,再乘以参数量和总tokens数就得到了总的计算量。GPT3的模型参数量为 174600M,训练数据量为 300B tokens。
训练时间估计
模型参数量和训练总tokens数决定了训练transformer模型需要的计算量。给定硬件GPU类型的情况下,可以估计所需要的训练时间。给定计算量,训练时间(也就是GPU算完这么多flops的计算时间)不仅跟GPU类型有关,还与GPU利用率有关。计算端到端训练的GPU利用率时,不仅要考虑前向传递和后向传递的计算时间,还要考虑CPU加载数据、优化器更新、多卡通信和记录日志的时间。一般来讲,GPU利用率一般在 0.3∼0.55 之间。
上文讲到一次前向传递中,对于每个token,每个模型参数,进行2次浮点数计算。使用激活重计算技术来减少中间激活显存(下文会详细介绍)需要进行一次额外的前向传递,因此前向传递 + 后向传递 + 激活重计算的系数=1+2+1=4。使用激活重计算的一次训练迭代中,对于每个token,每个模型参数,需要进行 2∗4=8 次浮点数运算。在给定训练tokens数、硬件环境配置的情况下,训练transformer模型的计算时间为:

 以GPT3-175B为例,在1024张40GB显存的A100上,在300B tokens的数据上训练175B参数量的GPT3。40GB显存A100的峰值性能为312TFLOPS,设GPU利用率为0.45,则所需要的训练时间为34天,
以GPT3-175B为例,在1024张40GB显存的A100上,在300B tokens的数据上训练175B参数量的GPT3。40GB显存A100的峰值性能为312TFLOPS,设GPU利用率为0.45,则所需要的训练时间为34天,
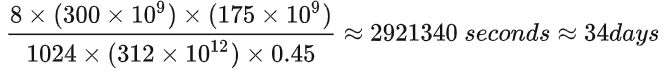 这与相关文献中的训练时间吻合,
这与相关文献中的训练时间吻合, (ref: https://arxiv.org/pdf/2104.04473.pdf)
(ref: https://arxiv.org/pdf/2104.04473.pdf)
以LLaMA-65B为例,在2048张80GB显存的A100上,在1.4TB tokens的数据上训练了65B参数量的模型。80GB显存A100的峰值性能为624TFLOPS,设GPU利用率为0.3,则所需要的训练时间为21天,
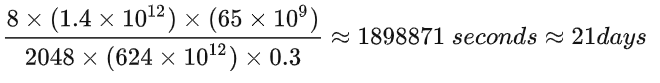 这与相关文献中的训练时间吻合,
这与相关文献中的训练时间吻合, (ref: https://arxiv.org/pdf/2302.13971.pdf)
(ref: https://arxiv.org/pdf/2302.13971.pdf)
不同阶段显存占用
训练阶段
在训练神经网络的过程中,占用显存的大头主要分为四部分:模型参数、前向计算过程中产生的中间激活、后向传递计算得到的梯度、优化器状态。这里着重分析参数、梯度和优化器状态的显存占用,中间激活的显存占用后面会详细介绍。训练大模型时通常会采用AdamW优化器,并用混合精度训练来加速训练,基于这个前提分析显存占用。
在一次训练迭代中,每个可训练模型参数都会对应1个梯度,并对应2个优化器状态(Adam优化器梯度的一阶动量和二阶动量)。设模型参数量为 ,那么梯度的元素数量为 ,AdamW优化器的元素数量为 。float16数据类型的元素占2个bytes,float32数据类型的元素占4个bytes。在混合精度训练中,会使用float16的模型参数进行前向传递和后向传递,计算得到float16的梯度;在优化器更新模型参数时,会使用float32的优化器状态、float32的梯度、float32的模型参数来更新模型参数。因此,对于每个可训练模型参数,占用了(2+4)+(2+4)+(4+4) = 24bytes,使用AdamW优化器和混合精度训练来训练参数量为的大模型,模型参数、梯度和优化器状态占用的显存大小为bytes。
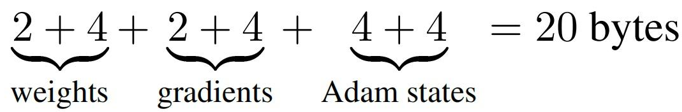 (ref: https://arxiv.org/pdf/2201.11990.pdf)
(ref: https://arxiv.org/pdf/2201.11990.pdf)
推理阶段
在神经网络的推理阶段,没有优化器状态和梯度,也不需要保存中间激活。少了梯度、优化器状态、中间激活,模型推理阶段占用的显存要远小于训练阶段。模型推理阶段,占用显存的大头主要是模型参数,如果使用float16来进行推理,推理阶段模型参数占用的显存大概是bytes 。如果使用KV cache来加速推理过程,KV cache也需要占用显存,KV cache占用的显存下文会详细介绍。此外,输入数据也需要放到GPU上,还有一些中间结果(推理过程中的中间结果用完会尽快释放掉),不过这部分占用的显存是很小的,可以忽略。
中间激活值显存分析
除了模型参数、梯度、优化器状态外,占用显存的大头就是前向传递过程中计算得到的中间激活值了,需要保存中间激活以便在后向传递计算梯度时使用。这里的激活(activations)指的是:前向传递过程中计算得到的,并在后向传递过程中需要用到的所有张量。这里的激活不包含模型参数和优化器状态,但包含了dropout操作需要用到的mask矩阵 在分析中间激活的显存占用时,只考虑激活占用显存的大头,忽略掉一些小的buffers。比如,对于layer normalization,计算梯度时需要用到层的输入、输入的均值和方差,输入包含了 个元素,而输入的均值和方差分别包含了个元素。由于 ℎ 通常是比较大的(千数量级),有 ,因此,对于layer normalization,中间激活近似估计为,而不是。
在分析中间激活的显存占用时,只考虑激活占用显存的大头,忽略掉一些小的buffers。比如,对于layer normalization,计算梯度时需要用到层的输入、输入的均值和方差,输入包含了 个元素,而输入的均值和方差分别包含了个元素。由于 ℎ 通常是比较大的(千数量级),有 ,因此,对于layer normalization,中间激活近似估计为,而不是。
大模型在训练过程中通常采用混合精度训练,中间激活值一般是float16或者bfloat16数据类型的。在分析中间激活的显存占用时,假设中间激活值是以float16或bfloat16数据格式来保存的,每个元素占了2个bytes。唯一例外的是,dropout操作的mask矩阵,每个元素只占1个bytes。在下面的分析中,单位是bytes,而不是元素个数。每个transformer层包含了一个self-attention块和MLP块,并分别对应了一个layer normalization连接。
Self-attention的中间激活
-
对于、、,需要保存它们共同的输入,这就是中间激活。输入的形状为 ,元素个数为 ,占用显存大小为。
-
对于矩阵乘法,需要保存中间激活、,两个张量的形状都是,占用显存大小合计为。
-
对于函数,需要保存函数的输入,占用显存大小为,其中为注意力头数
的形状:的形状:
Q的形状:,元素个数,占用显存大小。
-
计算完后,会进行dropout操作。需要保存一个mask矩阵,mask矩阵的形状与相同,占用显存大小。
-
计算在V上的attention,即,需要保存,显存大小为;以及V的显存大小为,共占用显存为。
-
计算输出映射以及一个dropout操作。输入映射需要保存其输入,大小为;dropout需要保存mask矩阵,大小为,二者占用显存大小合计为。
因此,将上述中间激活相加得到,self-attention块的中间激活占用显存大小为。
MLP的中间激活
-
第一个线性层需要保存其输入,占用显存大小为
-
激活函数需要保存其输入,占用显存大小为
-
第二个线性层需要保存其输入,占用显存大小为
-
最后有一个dropout操作,需要保存mask矩阵,占用显存大小为
因此,对于MLP块,需要保存的中间激活值为另外,self-attention块和MLP块分别对应了一个layer normalization。每个layer norm需要保存其输入,大小为,2个layer norm需要保存的中间激活为。
综上,每个transformer层需要保存的中间激活占用显存大小为,对于层transformer模型,还有embedding层、最后的输出层。embedding层不需要中间激活。总的而言,当隐藏维度较大,层数较深时,这部分的中间激活是很少的,可以忽略。因此,对于层transformer模型,中间激活占用的显存大小可以近似为。
中间激活与模型参数的显存占用对比
为什么可通过减小批次大小效缓解模型训练中显存不足(OOM)的问题?
在一次训练迭代中,模型参数或梯度占用显存大小只与模型参数量和参数数据类型有关,与输入数据的大小是没有关系的;优化器状态占用的显存大小与优化器类型有关,与模型参数量有关,但与输入数据的大小无关。而中间激活值与输入数据的大小(批次大小 和序列长度)是成正相关的,随着批次大小 和序列长度的增大,中间激活占用的显存会同步增大。当我们训练神经网络遇到显存不足OOM(Out Of Memory)问题时,通常会尝试减小批次大小来避免显存不足的问题,这种方式减少的其实是中间激活占用的显存,而不是模型参数、梯度和优化器的显存。
以GPT3-175B为例,我们来直观地对比下模型参数与中间激活的显存大小。GPT3的模型配置如下。我们假设采用混合精度训练,模型参数和中间激活都采用float16数据类型,每个元素占2个bytes。 GPT3的序列长度为2048,对比下不同批次大小中间激活层的显存占用:
GPT3的序列长度为2048,对比下不同批次大小中间激活层的显存占用:
-
大约是模型参数显存的0.79倍。
-
大约是模型参数显存的50倍。
-
大约是模型参数显存的101倍。
可以看到随着批次大小的增大,中间激活占用的显存远远超过了模型参数显存。通常会采用激活重计算技术来减少中间激活,理论上可以将中间激活显存从 减少到,代价是增加了一次额外前向计算的时间,本质上是“时间换空间”。
KV cache
在LLM推断阶段,需要认识到:
-
推理性能的最大瓶颈在于显存;
-
自回归模型的 keys 和 values 通常被称为 KV cache,这些 tensors 会存在 GPU 的显存中,用于生成下一个 token;
-
这些 KV cache 都很大,并且大小是动态变化难以预测,已有系统中,由于显存碎片和过度预留,浪费了60%-80%的显存。transformer模型推理加速的一个常用策略就是优化 KV cache,一个典型的大模型生成式推断包含了两个阶段:
-
预填充阶段:输入一个prompt序列,为每个transformer层生成 key cache和value cache,即KV cache。
-
解码阶段:使用并更新KV cache, 一个接一个地生成词,当前生成的词依赖于之前已经生成的词。
第个transformer层的权重矩阵为,其中self-attention的4个权重矩阵,MLP的2个权重矩阵。
预填充阶段
假设第个transformer层的输入为,self-attention块的key、value、query和output表示为,key cache和value cache计算过程:
第个transformer层剩余的计算过程:
解码阶段
给定当前生成词在第个transformer层的向量表示为,推断计算分两部分,更新KV cache 和 计算第个transformer层的输出。更新key cache和value cache的计算过程如下:
第个transformer层剩余的计算过程为:
KV cache 显存占用分析
假设输入序列长度为,输出序列长度为,以float16来保存KV cache,那么KV cache的峰值显存占用大小为,其中第一个2表示K/V cache,第二个2表示float16占2个bytes。
以GPT3为例,对比KV cache与模型参数占用显存的大小。GPT3模型占用显存大小为350GB。假设批次大小 ,输入序列长度,输出序列长度 ,则KV cache占用显存为
大约是模型参数显存的0.5倍。
总结
本文首先介绍了如何计算transformer模型的参数量,基于参数量可以进一步估计模型参数、梯度和优化器状态占用的显存大小。接着,本文估计了训练迭代中,在给定训练tokens数的情况下transformer模型的计算量,给予计算量和显卡性能可以进一步估计训练迭代的计算耗时。然后,本文分析了transformer模型前向计算过程中产生的中间激活值的显存大小,中间激活的显存大小与输入数据大小正相关,甚至会远超过模型参数占用的显存。最后,本文介绍了transformer模型推理过程常用的加速策略:使用KV cache。总的来说,分析transformer模型的参数量、计算量、中间激活和KV cache,有助于理解大模型训练和推断过程中的显存效率和计算效率。
特此声明,此文主体参考知乎文章https://zhuanlan.zhihu.com/p/624740065(在此感该作者“回旋托马斯x”的辛苦付出),本文重点对该文章进行计算验证、计算量FLOPs估计的逻辑修正、部分符号和表述修正、部分内容代码增加及重新排版。
参考
[1] https://arxiv.org/pdf/1706.03762.pdf
[2] https://arxiv.org/pdf/2302.13971.pdf
[3] https://arxiv.org/pdf/2104.04473.pdf
[4] https://zhuanlan.zhihu.com/p/624740065
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 4
4 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容



 开源友的聊-中美AI对决
开源友的聊-中美AI对决






所有评论(0)