【经典卷积神经网络-LeNet-5、AlexNet、VGG-16、ResNet、Inception、MobileNet学习记录】
经典卷积神经网络-LeNet-5、AlexNet、VGG-16、ResNet、Inception学习记录
经典卷积神经网络-Classic networks
本文作为学习记录,记录学习部分经典卷积神经网络的笔记
LeNet-5
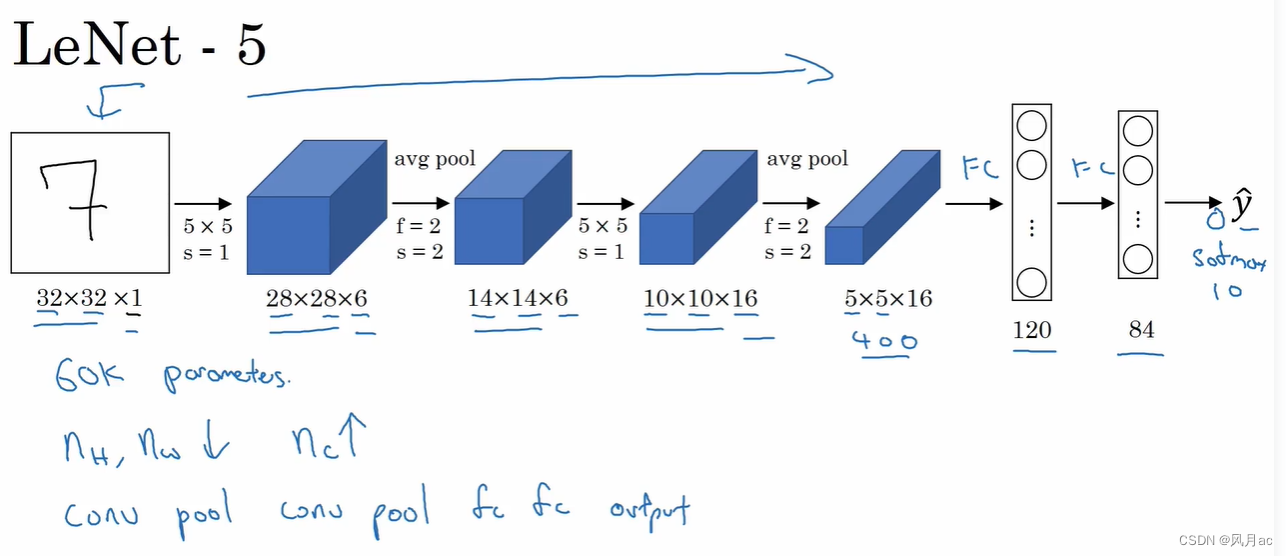
LeNet-5是入门深度学习网络的基础网络,包含了深度学习的基本模块:卷积层、池化层、全连接层。LeNet5共有七层,不包含输入,每层都包含可训练参数,每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每Feature Map有多个神经元。LeNet-5的具体实例是手写数字识别,具体的计算细节如图所示。
LeNet-5出自论文:Gradient-Based Learning Applied to Document Recognition
AlexNet
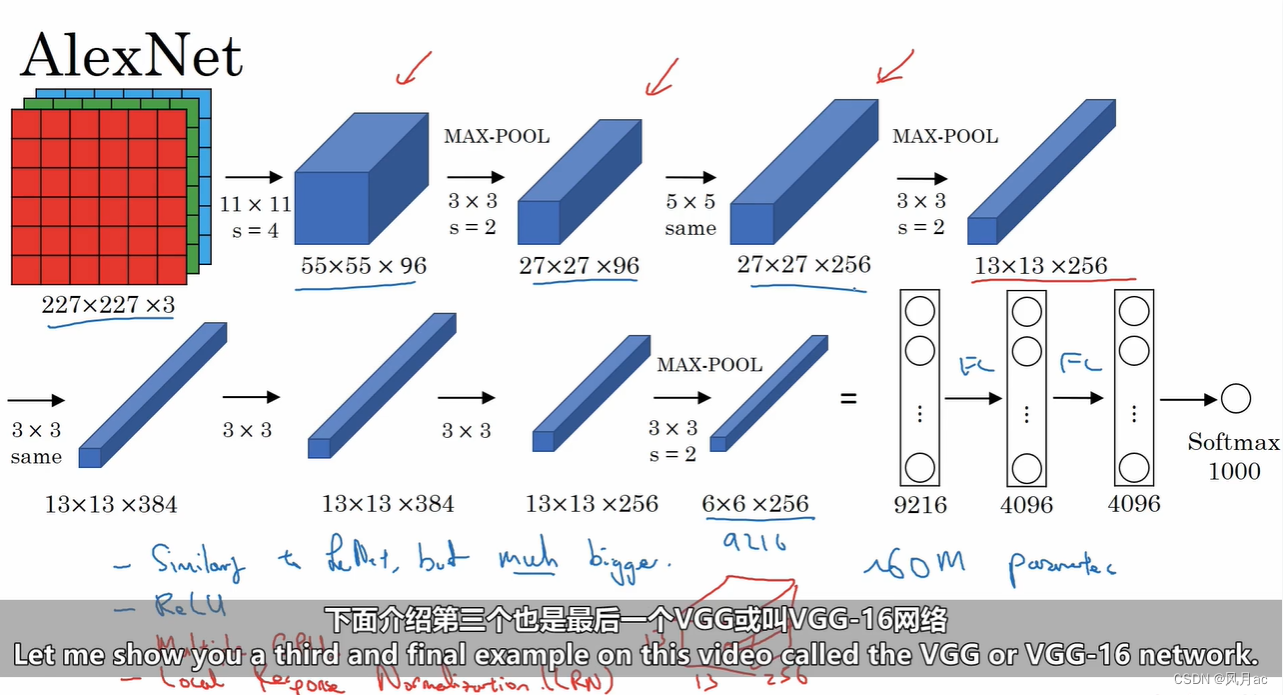
AlexNet出自论文:Krizhevsky et al.,2012.ImageNet classification with deep convolutional neural networks
由于当时GPU内存的限制引起的,作者还对网络结构进行的复杂的设计,但是,以目前GPU的处理能力,单GPU足够了,不作为重点。
VGG-16

VGG出自论文:Simonvan & Zisserman 2015.Very deep convolutional networks for large-scale image recognitionl
VGG-16网络结构
(1)维度
以VGG16进行网络结构介绍,其他组类型大同小异。整个模型结构可分为两大部分:提取特征网络结构与分类网络结构
卷积层默认kernel_size=3,padding=1;池化层默认size=2,strider=2。下面进行结构分析:
输入图像尺寸为2242243
经过2层的6433卷积核,即卷积两次,再经过ReLU激活,输出尺寸大小为22422464
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为11211264
经过2层的12833卷积核,即卷积两次,再经过ReLU激活,输出尺寸大小为112112128
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为5656128
经过3层的25633卷积核,即卷积三次,再经过ReLU激活,输出尺寸大小为5656256
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为282825
经过3层的51233卷积核,即卷积三次,再经过ReLU激活,输出尺寸大小为2828512
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为1414512
经过3层的51233卷积核,即卷积三次,再经过ReLU激活,输出尺寸大小为1414512
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为77512
然后将feature map展平,输出一维尺寸为77512=25088
经过2层的114096全连接层,经过ReLU激活,输出尺寸为114096
经过1层的111000全连接层(1000由最终分类数量决定,当年比赛需要分1000类)输出尺寸为111000,最后通过softmax输出1000个预测结果
(2)权重参数(不考虑偏置)
输入层为2142243,没有参数为0,存储容量为2242243=150k
第一层卷积,输入层有3个channels,卷积核数量为64,所以参数为64333=1728,存储容量为22422464=3.2m
第二层卷积,输入有64个channels,卷积核数量为64,所以参数为643364=36864,存储容量为22422464=3.2m
第一层池化,输入为64个channels,高宽减半,所以参数为0,存储容量为11211264=800k
第三层卷积,输入有64个channels,卷积核数量为128,所以参数为6433128=73728,存储容量为112112128=1.6m
第四层卷积,输入有128个channels,卷积核数量为128,所以参数为12833128=147456,存储容量为112112128=1.6m
第二层池化,输入为128个channels,高宽减半,所以参数为0,存储容量为5656128=400k
第五层卷积,输入有128个channels,卷积核数量为256,所以参数为25633128=294912,存储容量为112112128=800k
第六层卷积,输入有256个channels,卷积核数量为256,所以参数为25633256=589824,存储容量为112112128=800k
…
全连接层权重参数为:前一层节点数×本层的节点数
FC1(1×1×4096)参数:7×7×512×4096=102760448,存储容量为4096
FC2(1×1×4096)参数:4096×4096=16777216,存储容量为4096
FC3(1×1×1000)参数:4096×1000=4096000,存储容量为1000

(3)全连接变卷积

ResNet
(1)从plain block 到 Residual block
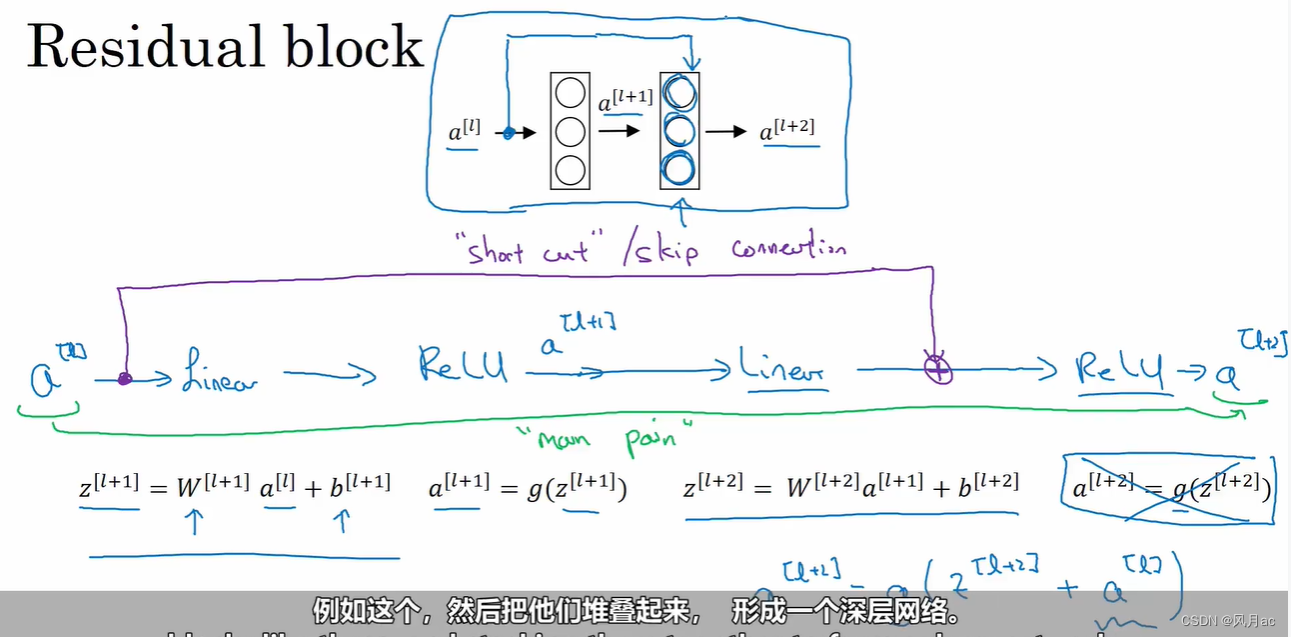

从数学角度出发,随着神经网络深度的增加,会发生梯度消失和梯度爆炸的可能,由于神经网络深度增加,Residual block将a[l]复制到深层网络中去实际上并不会造成太大的变化,因为本身随着深度增加,权重的更新也变得微乎其微。
a[l] 通过快捷路径叠加到更深层的神经网络中去,这样a[l+2]就变成g(z[l+2]) ,其中g为Relu函数。

残差块的合理解释:如果后两项能够学习到合适的权重,结合原来的恒等式,将发生有效的学习,如果后两项在训练上效果比较差,那么w[l+2]a[l+1]+b[l+2]将接近0,则a[l+2]将保持原来的水平a[l],这也是残差块为什么能够解决梯度消失和梯度爆炸的原因之一。
(2)1×1卷积层:改变通道数

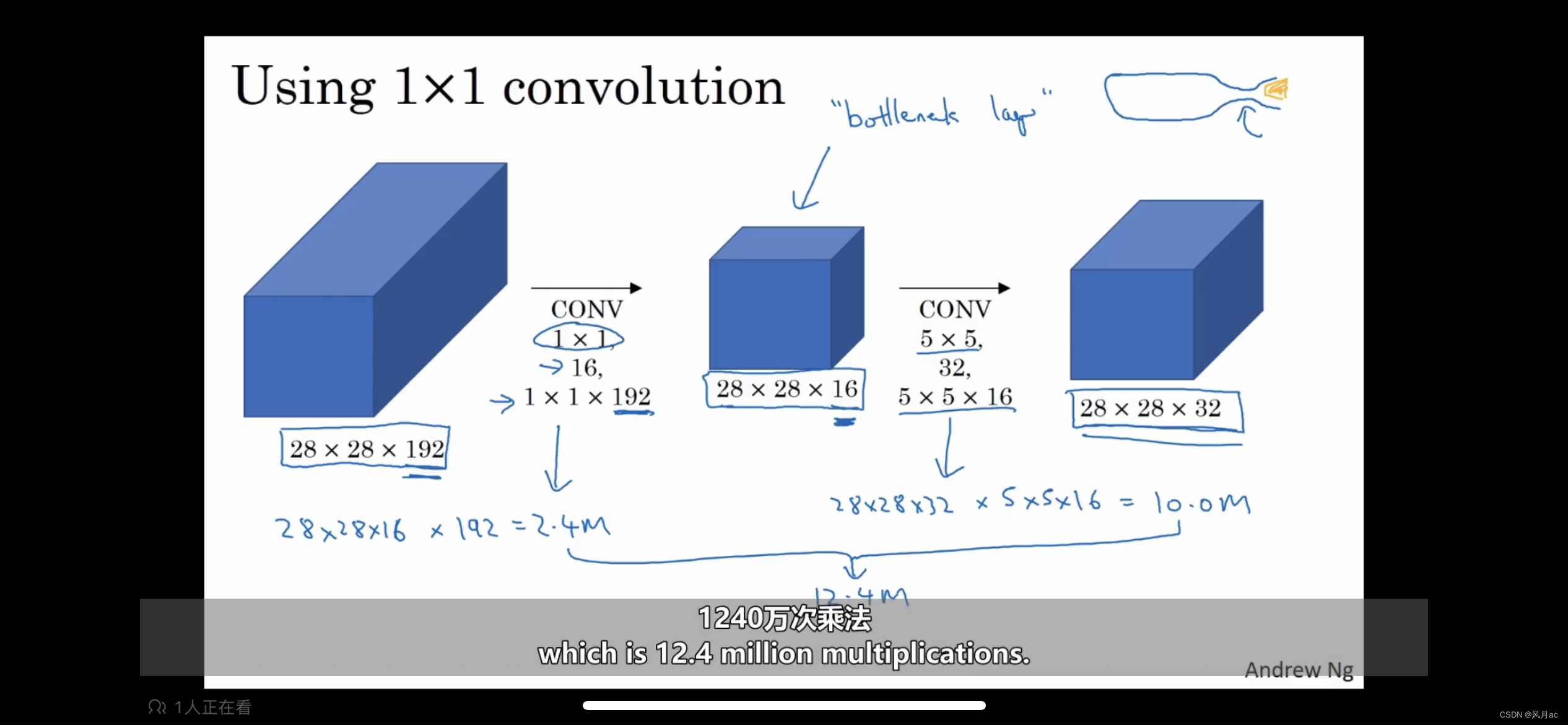
(1)通道数是怎么改变的?
比如图1,是拿着16个不同的卷积核(滤波器),对左边每一片(共192片)进行卷积再叠加,每192片在不同的滤波器(16个滤波器)下会出现新的16层,这就减少了通道数。
(2)观察上述的卷积,结果都是变为28×28×32,但参数量有什么区别?
图1直接进行5×5卷积运算需要保持图片长宽不变的前提,(通过公式N2 = (N1 - F + 2P) / S + 1,我们需要进行Padding=2的填充),参数量为:28×28×5×5×192×32=120M。
①图2先进行1×1卷积运算,降低通道数为16,参数量为:28×28×192×32=2.4M。
②再进行5×5×32的卷积运算,扩张通道数为32,参数量为:28×28×5×5×16×32=10M。
总的需要10M+2.4M=12.4M,在参数计算上省了非常多参数量。
(3)代价
视频里说只要权衡好通道数的变换,就不太影响精度,这方面没有仔细研究。
inception block与深度可分离卷积


MobileNet中的深度可分离卷积。
个人理解,区别深度可分离卷积就是将filter中的层对层计算,再经过一个1×1的通道转换,而普通卷积是每一层对前面图片所有通道卷积的叠加,nc个滤波器的每层计算所有通道的叠加的再叠加。
参考
https://blog.csdn.net/panghuzhenbang/article/details/124431562
吴恩达deeplearning.ai
学习时间:
2023.7.26
做个记录——2023.7.25,有什么问题直接指出。

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)