
yolov5 pose 图片和视频推理脚本
有兴趣的小伙伴可以研究一下。
·
yolov5pose 人体关键点识别 图片和视频推理脚本
最近在弄一个和人体关键点识别相关的项目,编写了一个yolopose项目中利用onnx来进行图片和视频推理的脚本,记录一下
YOLO-Pose 相关简介

论文:YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
项目链接:TexasInstruments/edgeai-yolov5
有兴趣的小伙伴可以研究一下
推理流程
这个项目本身就是基于yolov5的,推理流程也和yolov5一样,只需要在后处理的时候对关键点数据进行处理即可
推理需要的onnx模型可以在官网下载:官网yolopose onnx模型
这里也可以从我的网盘链接下载:pose onnx模型
大概推理步骤
读取模型,传入图片或视频 - 图片预处理 - 模型推理 - 置信度过滤 - 坐标变换,将检测框、关键点坐标还原到原图上- 遍历检测数据,开始画框、画点、画骨架
脚本说明
原项目中有一个onnx推理的脚本,但是功能不完整,我在原来的基础上,改了一点点。脚本需要设置onnx路径,设置了两种模式一种是图片检测,记得设置图片路径,另一种是视频检测,并显示推理的FPS,视频检测只需要注意一下自己的摄像头编号

完整代码如下:
import time
import numpy as np
import cv2
import onnxruntime
_CLASS_COLOR_MAP = [ (0, 0, 255) , # Person (blue).
(255, 0, 0) , # Bear (red).
(0, 255, 0) , # Tree (lime).
(255, 0, 255) , # Bird (fuchsia).
(0, 255, 255) , # Sky (aqua).
(255, 255, 0) , # Cat (yellow).
]
palette = np.array([[255, 128, 0], [255, 153, 51], [255, 178, 102],
[230, 230, 0], [255, 153, 255], [153, 204, 255],
[255, 102, 255], [255, 51, 255], [102, 178, 255],
[51, 153, 255], [255, 153, 153], [255, 102, 102],
[255, 51, 51], [153, 255, 153], [102, 255, 102],
[51, 255, 51], [0, 255, 0], [0, 0, 255], [255, 0, 0],
[255, 255, 255]])
skeleton = [[16, 14], [14, 12], [17, 15], [15, 13], [12, 13], [6, 12],
[7, 13], [6, 7], [6, 8], [7, 9], [8, 10], [9, 11], [2, 3],
[1, 2], [1, 3], [2, 4], [3, 5], [4, 6], [5, 7]]
pose_limb_color = palette[[9, 9, 9, 9, 7, 7, 7, 0, 0, 0, 0, 0, 16, 16, 16, 16, 16, 16, 16]]
pose_kpt_color = palette[[16, 16, 16, 16, 16, 0, 0, 0, 0, 0, 0, 9, 9, 9, 9, 9, 9]]
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), scaleup=True):
''' 调整图像大小和两边灰条填充 '''
shape = im.shape[:2]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# 缩放比例 (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# 只进行下采样 因为上采样会让图片模糊
if not scaleup:
r = min(r, 1.0)
# 计算pad长宽
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) # 保证缩放后图像比例不变
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
# 在较小边的两侧进行pad, 而不是在一侧pad
dw /= 2
dh /= 2
# 将原图resize到new_unpad(长边相同,比例相同的新图)
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
# 计算上下两侧的padding
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
# 计算左右两侧的padding
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
# 添加灰条
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color)
return im
def xyxy2xywh(x):
# 将box从(左上点,右下点)———>>> (左上点, w, h)
y = np.copy(x)
y[:, 2] = x[:, 2] - x[:, 0] # w
y[:, 3] = x[:, 3] - x[:, 1] # h
return y
def scale_boxes(img1_shape, boxes, img0_shape):
''' 将预测的坐标信息转换回原图尺度
:param img1_shape: 缩放后的图像尺度
:param boxes: 预测的box信息
:param img0_shape: 原始图像尺度
'''
# 将检测框(x y w h)从img1_shape(预测图) 缩放到 img0_shape(原图)
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
boxes[:, 0] -= pad[0]
boxes[:, 1] -= pad[1]
boxes[:, :4] /= gain # 检测框坐标点还原到原图上
num_kpts = boxes.shape[1] // 3 # 57 // 3 = 19
# 关键点坐标还原到原图上
for kid in range(2,num_kpts):
boxes[:, kid * 3] = ( boxes[:, kid * 3] - pad[0] ) / gain
boxes[:, kid * 3 +1] = ( boxes[:, kid * 3 +1] - pad[1] ) / gain
clip_boxes(boxes, img0_shape)
return boxes
def clip_boxes(boxes, shape):
# 进行一个边界截断,以免溢出
# 并且将检测框的坐标(左上角x,左上角y,宽度,高度)--->>>(左上角x,左上角y,右下角x,右下角y)
top_left_x = boxes[:, 0].clip(0, shape[1])
top_left_y = boxes[:, 1].clip(0, shape[0])
bottom_right_x = (boxes[:, 0] + boxes[:, 2]).clip(0, shape[1])
bottom_right_y = (boxes[:, 1] + boxes[:, 3]).clip(0, shape[0])
boxes[:, 0] = top_left_x #左上
boxes[:, 1] = top_left_y
boxes[:, 2] = bottom_right_x #右下
boxes[:, 3] = bottom_right_y
def read_img(img, img_mean=127.5, img_scale=1/127.5):
# 预处理
img = (img - img_mean) * img_scale
img = np.asarray(img, dtype=np.float32)
img = np.expand_dims(img,0)
img = img.transpose(0,3,1,2)
return img
def plot_skeleton_kpts(im, kpts, steps=3):
num_kpts = len(kpts) // steps
for kid in range(num_kpts):
r, g, b = pose_kpt_color[kid]
x_coord, y_coord = kpts[steps * kid], kpts[steps * kid + 1]
conf = kpts[steps * kid + 2]
if conf > 0.5: # 关键点的置信度必须大于 0.5
cv2.circle(im, (int(x_coord), int(y_coord)), 10, (int(r), int(g), int(b)), -1)
# plot skeleton
for sk_id, sk in enumerate(skeleton):
r, g, b = pose_limb_color[sk_id]
pos1 = (int(kpts[(sk[0]-1)*steps]), int(kpts[(sk[0]-1)*steps+1]))
pos2 = (int(kpts[(sk[1]-1)*steps]), int(kpts[(sk[1]-1)*steps+1]))
conf1 = kpts[(sk[0]-1)*steps+2]
conf2 = kpts[(sk[1]-1)*steps+2]
if conf1 >0.5 and conf2 >0.5: # For a limb, both the keypoint confidence must be greater than 0.5
cv2.line(im, pos1, pos2, (int(r), int(g), int(b)), thickness=2)
def inference(model_path, img, mean=None, scale=None,conf_thres=0.3):
# 图像读取,预处理
image1 = letterbox(img)
input = read_img(image1, mean, scale)
# 推理
# session = onnxruntime.InferenceSession(model_path, provider = ['CUDAExecutionProvider', 'CPUExecutionProvider'])
session = onnxruntime.InferenceSession(model_path, providers=['CPUExecutionProvider'])
input_name = session.get_inputs()[0].name
output = session.run([], {input_name: input})
output = output[0]
# 置信度阈值过滤
output = output[output[..., 4] > conf_thres]
if len(output) == 0:
print("没有检测到任何关键点")
return image
else:
# 坐标变换
det_box = xyxy2xywh(output)
# 坐标点还原到原图上
output = scale_boxes(image1.shape, det_box, img.shape)
# 依次为 人体检测框(左上点,右下点)、置信度、标签、17个关键点
det_bboxes, det_scores, det_labels, kpts = output[:, 0:4], output[:, 4], output[:, 5], output[:, 6:]
""" 在图上画框、画点、连线 """
for idx in range(len(det_bboxes)):
det_bbox = det_bboxes[idx]
kpt = kpts[idx]
color_map = _CLASS_COLOR_MAP[int(det_labels[idx])]
# 画框
img = cv2.rectangle(img, (int(det_bbox[0]), int(det_bbox[1])), (int(det_bbox[2]), int(det_bbox[3])),
color_map[::-1], 2)
# 类别
# cv2.putText(img, "id:{}".format(int(det_labels[idx])), (int(det_bbox[0]+5),int(det_bbox[1])+15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color_map[::-1], 2)
# 在图上写置信度
if int(det_bbox[1]) < 30 :
cv2.putText(img, "score:{:2.1f}".format(det_scores[idx]), (int(det_bbox[0]+5), int(det_bbox[1]) + 28),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 2)
else :
cv2.putText(img, "conf:{:2.1f}".format(det_scores[idx]), (int(det_bbox[0])+5, int(det_bbox[1]) - 5),
cv2.FONT_HERSHEY_SIMPLEX, 1,(0,0,255), 2)
# 画点 连线
plot_skeleton_kpts(img, kpt)
return img
if __name__== "__main__":
model_path = r"yolov5s6_pose_640_ti_lite_54p9_82p2.onnx"
# 两种模式 1为图片预测,并显示结果图片;2为摄像头检测,并实时显示FPS
mode = 1
if mode == 1:
# 输入图片路径
imgpath = r"1.jpg"
img = cv2.imread(imgpath)
start = time.time()
image = inference(model_path=model_path, img=img,
mean=0.0, scale=0.00392156862745098)
end = time.time()
det_time = (end - start) * 1000
print("推理时间为:{:.2f} ms".format(det_time))
print("图片完成检测")
cv2.namedWindow("keypoint",cv2.WINDOW_NORMAL)
cv2.imshow("keypoint",image)
cv2.waitKey(0)
cv2.destroyAllWindows()
elif mode == 2 :
# 摄像头人体关键点检测
cap = cv2.VideoCapture(0)
# 返回当前时间戳
start_time = time.time()
counter = 0
while True:
# 从摄像头中读取一帧图像
ret, frame = cap.read()
image = inference(model_path=model_path, img=frame,
mean=0.0, scale=0.00392156862745098)
counter += 1 # 计算帧数
# 实时显示帧数
if (time.time() - start_time) != 0:
cv2.putText(image, "FPS:{0}".format(float('%.1f' % (counter / (time.time() - start_time)))), (5, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 1)
# 显示图像
cv2.imshow('keypoint', image)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
else:
print("\033[1;91m 输入错误,请检查mode的赋值 \033[0m")
图片检测效果

视频就不展示了,FPS才4帧,这个模型确实比较吃配置
显示效果可以再优化一下,有兴趣的小伙伴可以整一整


欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐

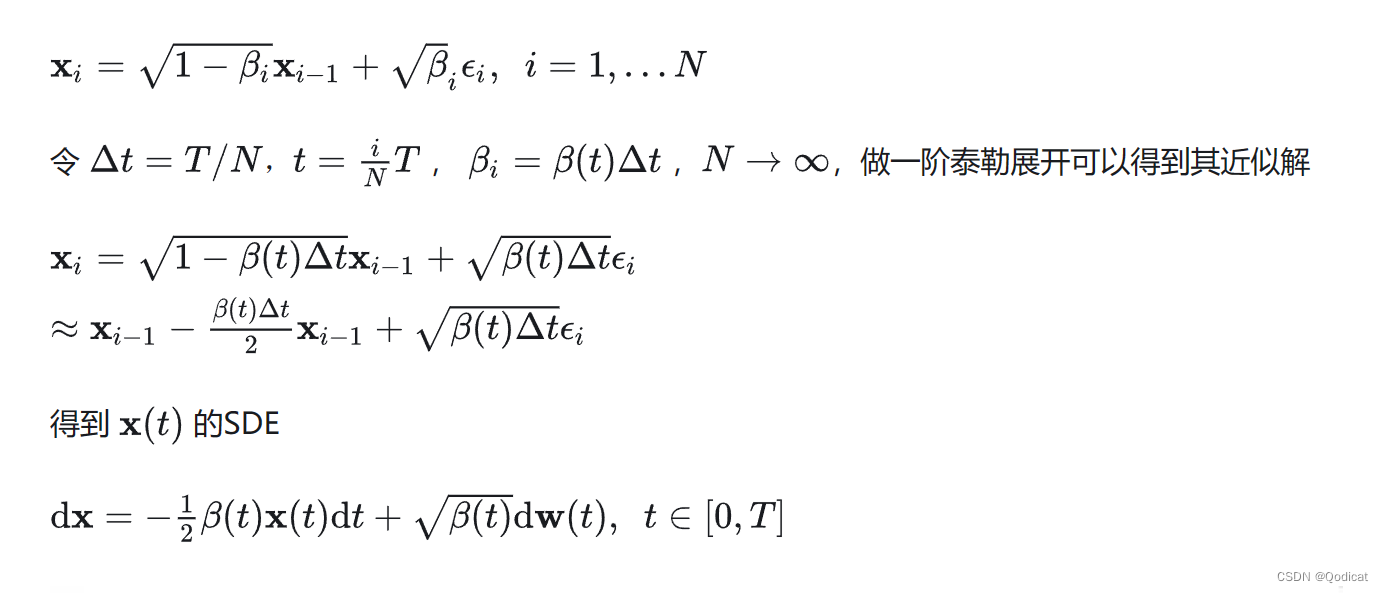
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)