
机器学习之数学建模---01初始机器学习
数据的维度(上面的代码)查看数据自身(上面的代码)统计描述数据分类的情况# 描述性统计 print(dateset . describe()) # 数据分布情况 print(dateset . groupby("class") . size())
初始机器学习
初识机器学习——什么是机器学习?
西瓜数据集
| 编号 | 色泽 | 根蒂 | 敲声 | 好瓜 |
| 1 | 青绿 | 蜷缩 | 浊响 | 是 |
| 2 | 乌黑 | 蜷缩 | 浊响 | 是 |
| 3 | 青绿 | 硬挺 | 清脆 | 否 |
| 4 | 乌黑 | 稍蜷 | 沉闷 | 否 |
数据集:这组记录的集合
样本:其中每条记录是关于一个事件或对象(这里是一个西瓜)的描述
特征:反映对象在某方面的性质的事项,例如“色泽”“根蒂”“敲声”
特征值:属性上的取值,例如“青绿”“乌黑”
样本空间:由特征张成的空间,例如我们把“色泽”“根蒂”“敲声”作为三
个坐标轴,每个西瓜都可在这个空间中找到自己的坐标位置。
特征向量:空间中的每个点都对应一个坐标向量
初识机器学习
💡 1.模型
模型这一词语将会贯穿整个教程的始末,它是机器学习中的核心概念。你可以把它看做一个“魔法盒”,你向它许愿(输入数据),它就会帮你实现愿望(输出预测结果)。整个机器学习的过程都将围绕模型展开,训练出一个最优质的“魔法盒”,它可以尽量精准的实现你许“愿望”,这就是机器学习的目标。
💡 2.数据集 数据集,从字面意思很容易理解,它表示一个承载数据的集合,如果说“模型”是“魔法盒”的话,
那么数据集就是负责给它充能的“能量电池”,简单地说,如果缺少了数据集,那么模型就没有存
在的意义了。数据集可划分为“训练集”和“测试集”,它们分别在机器学习的“训练阶段”和“预测输出阶段”起着重要的作用
💡 3.训练集&假设
从数据中学得的模型,称为“学习”或“训练”。这个过程通过执行某个学习算法完成,训练过程中使用的数据称为“训练数据”,其中每一个样本称为“训练样本”,由“训练样本”组成的集合称为“训练集”。学得模型对应了关于数据的某种潜在的规律,因此亦称“假设”,假设可以理解成“模型”;这种潜在的规律自身,则称为“真相”。学习的过程就是为了找出或逼近真相。
💡 4.测试集
在获得“训练模型”后,我们还需要知道用该模型来预测其他情况的结果的效果好不好,所以需要引入“测试集”,如果该模型也能够很好的预测出“测试集”的结果,那么我们可以认为“训练模型”非常接近“真相”
💡 5.标记信息
如上表,例如,其中一个样本为“((色泽=青绿;根蒂=蜷缩;敲声=浊响),好瓜)”,这里关于样本结果的信息,例如“好瓜”,称为“标记”;拥有标记信息的示例,则称为“样例”。注意:分类和回归问题需要使用带“标记”的数据,聚类使用的数据集一般不拥有标记信息。
💡 6.分类&回归 若我们欲预测的结果是离散值(即标记是离散的) 例如“好瓜”“坏瓜”,此类学习任务称为“分类”;
若欲预测的是连续值(即标记是连续的) 例如西瓜的成熟度0.95,0.37.此类学习任务称为“回归”。
💡 7.聚类 我们还可以对西瓜做“聚类”,相关算法将自动将训练集中的西瓜分成若干组,每组称为一个
“簇”。这些自动形成的簇可能对应一些潜在的划分,比如“本地瓜”“外地瓜”。需注意的是,
在聚类学习中,像“本地瓜”“外地瓜”这些概念我们事先是不知道的,“簇”是计算机自动识别
数据进行的划分,而且学习过程中使用的训练集样本不拥有标记信息
机器学习分类
-
机器学习的算法分为两大类:监督学习、无监督学习
-
监督学习:在机器学习过程中提供对错指示。比如数据的结果部分为(0,1),通过算法让机器
自己减少误差。这一类主要应用于分类和回归(Regression&Classify)。监督学习从给定的训
练集中学习一个目标函数,当新的数据到来时,可以根据这个函数预测结果。监督学习要求包括
输入和输出,也就是特征和目标。 -
非监督学习:归纳行学习,利用K方式建立中心,通过循环和递减运算减小误差达到分类的目的。


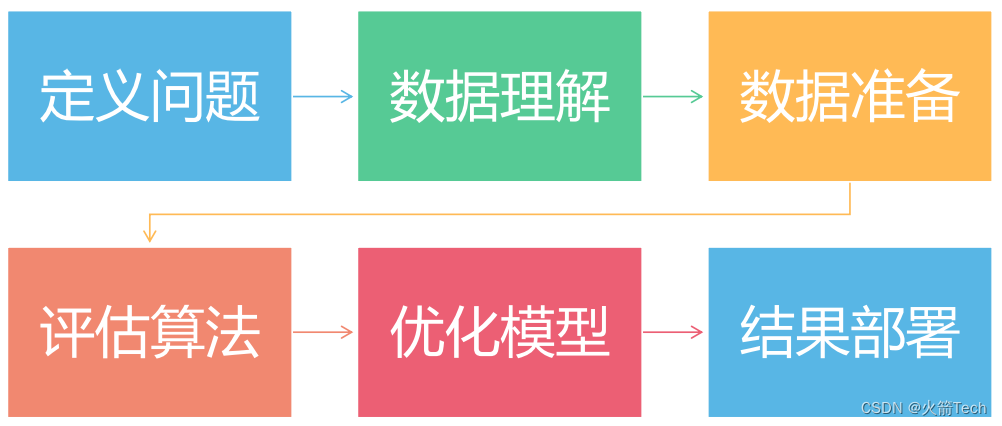
数学建模Python机器学习五大步骤

第一个机器学习项目
一、导入类库
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
这些代码是将库类导入编译器中,如果库标红,win+R→cmd—→pip install 库类名
二、导入数据集(导入的数据集,评论1可领取)
# 导入数据集
file_name = "E:/机器学习--数学建模/第一个项目/iris.data.csv" #用自己的文件路径
names = "separ-length", "separ-wider", "petal-lengyh", "petal-wider", "class"
dateset = read_csv(file_name, names=names)
print("数据维度:行 %s,列 %s" % dateset.shape)
# 如果拿到新的数据,我只需要修改file_name文件路径,和names数据的名字
三、概述数据
- 数据的维度(上面的代码)
- 查看数据自身(上面的代码)
- 统计描述
- 数据分类的情况
# 描述性统计
print(dateset.describe())
# 数据分布情况
print(dateset.groupby("class").size())
四、数据可视化
- 单变量图表
- 多变量图表
# 数据可视化
dateset.plot(kind="box", subplots=True, layout=(2,2),sharex=False,sharey=False)
# plot--画图
pyplot.show()
dateset.hist() # hist--直方图
pyplot.show()
# 我们需要的正态分布,两边低中间高,本次数据也是标准的正态分布数据
scatter_matrix(dateset)
pyplot.show()
正态分布:正态分布的图像呈钟形曲线,左右对称,中心位于均值处。
五、评估算法
- 分离出评估数据集
- 采用10折交叉验证来评估
- 生产6种模型来预测新数据
- 选择最优模型
# 分离数据集
array = dateset.values
X = array[:,0:4]
Y = array[:,4]
validation_size = 0.2
seed = 7
X_train,X_validation,Y_train,Y_validation = train_test_split(X,Y,test_size=validation_size,random_state=seed)
# 算法
models = {}
models['LR'] = LogisticRegression()
models['KNN'] = KNeighborsClassifier()
models['LDA'] = LinearDiscriminantAnalysis()
models['CART'] = DecisionTreeClassifier()
models['SVM'] = SVC()
models['NB'] = GaussianNB()
results = []
for key in models:
kflod = KFold(n_splits=10, random_state=seed, shuffle=True)
cv_results = cross_val_score(models[key], X_train, Y_train, cv=kflod, scoring='accuracy')
results.append(cv_results)
print('%s: %f (%f)' %(key, cv_results.mean(), cv_results.std()))
svm = SVC()
svm.fit(X=X_train, y=Y_train)
predictions = svm.predict(X_validation)
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))
七、实施预测(代码如上)
八、总结(代码如上)
全部代码
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
# 导入数据集
file_name = "E:/机器学习--数学建模/第一个项目/iris.data.csv"
names = "separ-length", "separ-wider", "petal-lengyh", "petal-wider", "class"
dateset = read_csv(file_name, names=names)
print("数据维度:行 %s,列 %s" % dateset.shape)
# 如果拿到新的数据,我只需要修改file_name文件路径,和names数据的名字
# 查看数据集
print(dateset.head(10)) # 查看前10行的数据,索引从0开始,默认从0开始
# 目的是为了查看数据是否导入
# 描述性统计
print(dateset.describe())
# 数据分布情况
print(dateset.groupby("class").size())
# 数据可视化
dateset.plot(kind="box", subplots=True, layout=(2,2),sharex=False,sharey=False)
# plot--画图
pyplot.show()
dateset.hist() # hist--直方图
pyplot.show()
# 我们需要的正态分布,两边低中间高,本次数据也是标准的正态分布数据
scatter_matrix(dateset)
pyplot.show()
# 分离数据集
array = dateset.values
X = array[:,0:4]
Y = array[:,4]
validation_size = 0.2
seed = 7
X_train,X_validation,Y_train,Y_validation = train_test_split(X,Y,test_size=validation_size,random_state=seed)
# 算法
models = {}
models['LR'] = LogisticRegression()
models['KNN'] = KNeighborsClassifier()
models['LDA'] = LinearDiscriminantAnalysis()
models['CART'] = DecisionTreeClassifier()
models['SVM'] = SVC()
models['NB'] = GaussianNB()
results = []
for key in models:
kflod = KFold(n_splits=10, random_state=seed, shuffle=True)
cv_results = cross_val_score(models[key], X_train, Y_train, cv=kflod, scoring='accuracy')
results.append(cv_results)
print('%s: %f (%f)' %(key, cv_results.mean(), cv_results.std()))
svm = SVC()
svm.fit(X=X_train, y=Y_train)
predictions = svm.predict(X_validation)
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))
date命名写错了,上面代码仅供参考
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)