

迁移学习
此外,迁移学习和模型微调都是将已有的知识和经验应用到新的任务或数据集中进行训练,而模型蒸馏则是将大模型中的知识和经验传递到小模型中。而模型蒸馏则是在已有的知识和经验的基础上,将大模型中的一些信息压缩到小模型中,来提高小模型的性能。迁移学习是一种从一个领域迁移到另一个领域的技术,通过将一个任务中学习到的知识和经验迁移到另一个相关领域中,来加速和改进新领域的学习和解决问题的能力。模型蒸馏是一种将一个大
迁移学习
迁移学习(Transfer Learning)是一种机器学习方法,它通过将一个领域中的知识和经验迁移到另一个相关领域中,来加速和改进新领域的学习和解决问题的能力。简而言之,就是将在一个任务中训练好的模型应用到另一个任务中。
迁移学习可以通过以下几种方式实现:
-
基于预训练模型的迁移:将已经在大规模数据集上预训练好的模型(如BERT、GPT等)作为一个通用的特征提取器,然后在新领域的任务上进行微调。
-
网络结构迁移:将在一个领域中训练好的模型的网络结构应用到另一个领域中,并在此基础上进行微调。
-
特征迁移:将在一个领域中训练好的某些特征应用到另一个领域中,并在此基础上进行微调。
-
参数迁移:将在一个领域中训练好的模型的参数应用到另一个领域中,并在此基础上进行微调。
迁移学习的优点在于可以在新领域中使用较少的数据进行训练,从而减少训练时间和成本。此外,还可以通过利用已有的知识和经验,改进模型的泛化能力和鲁棒性,提高模型的性能和效果。
迁移学习在自然语言处理、计算机视觉等领域中得到了广泛的应用,例如在文本分类、图像识别、目标检测、语义分割等任务中,都可以通过迁移学习来提高模型的性能。
ppt课件https://www.jianguoyun.com/p/Dedc5O0QjKnsBRi-gcIEIAA


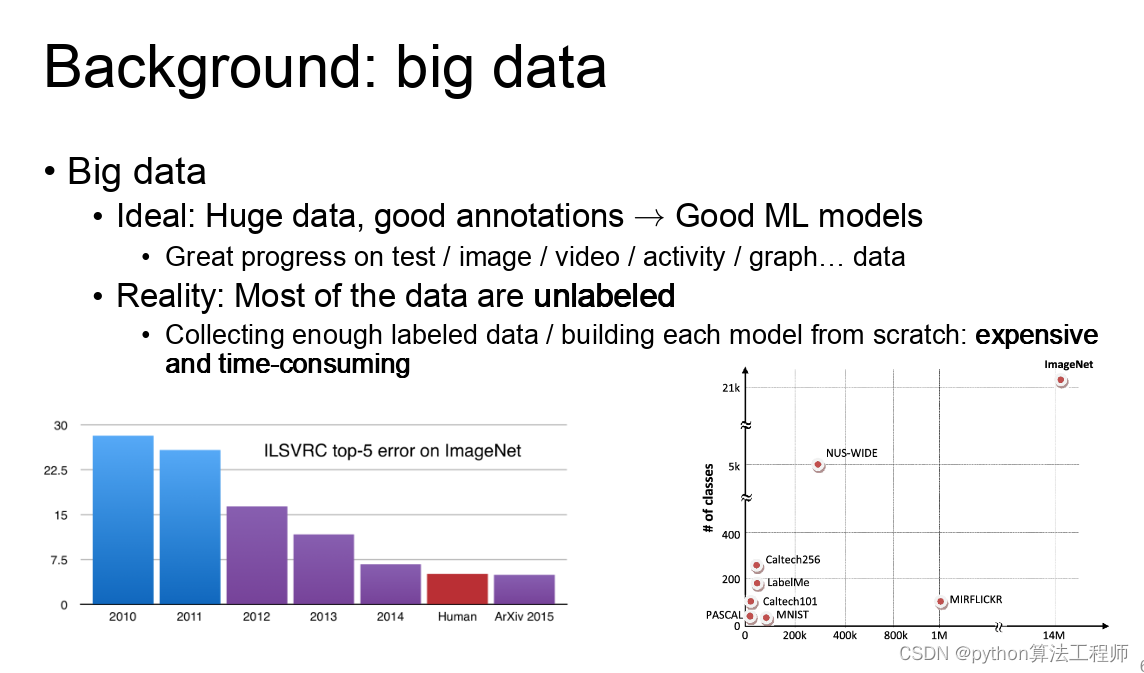





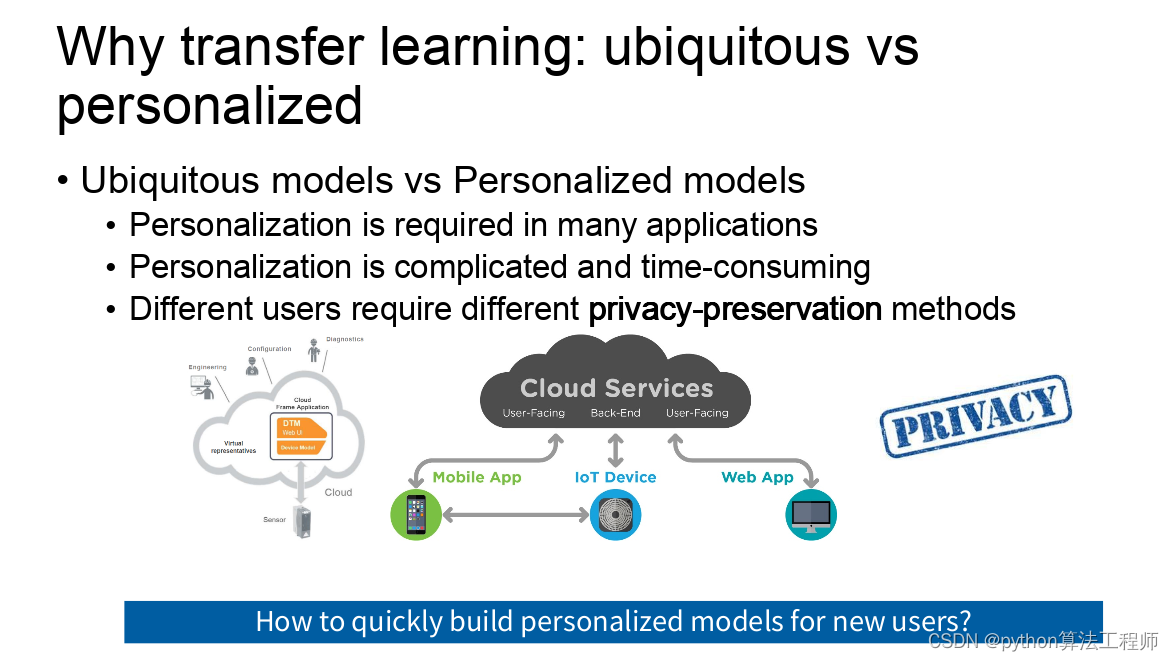

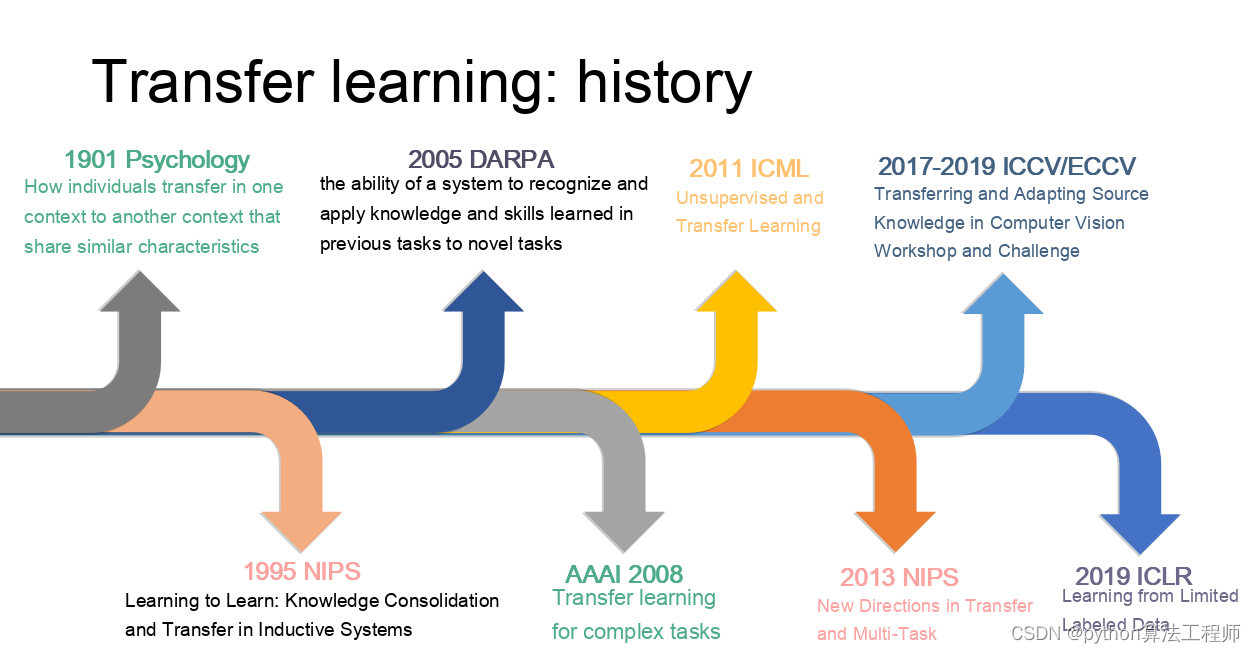












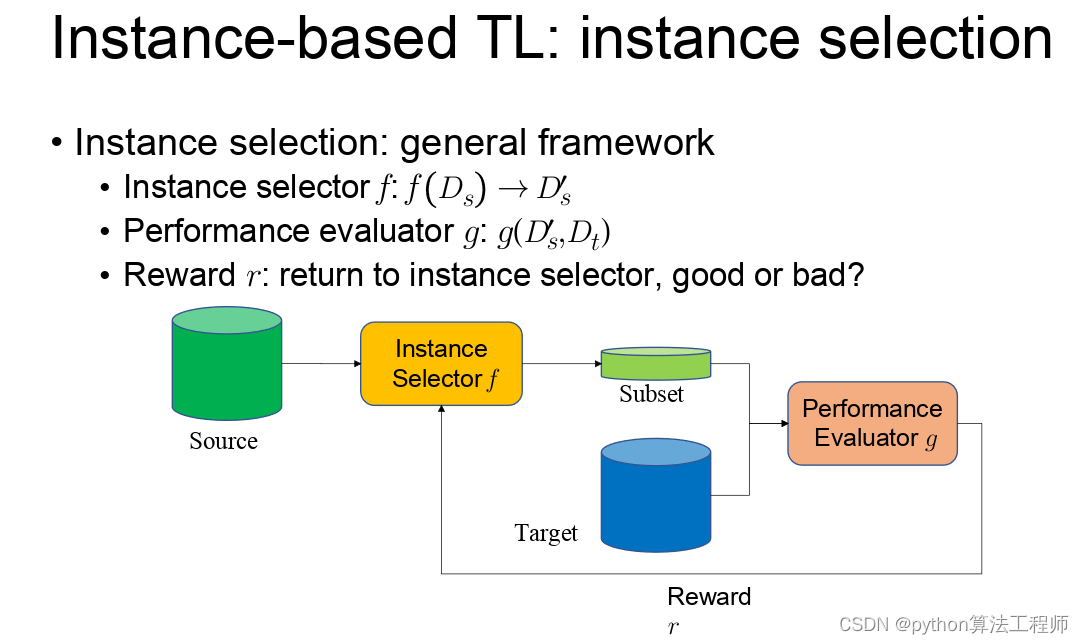
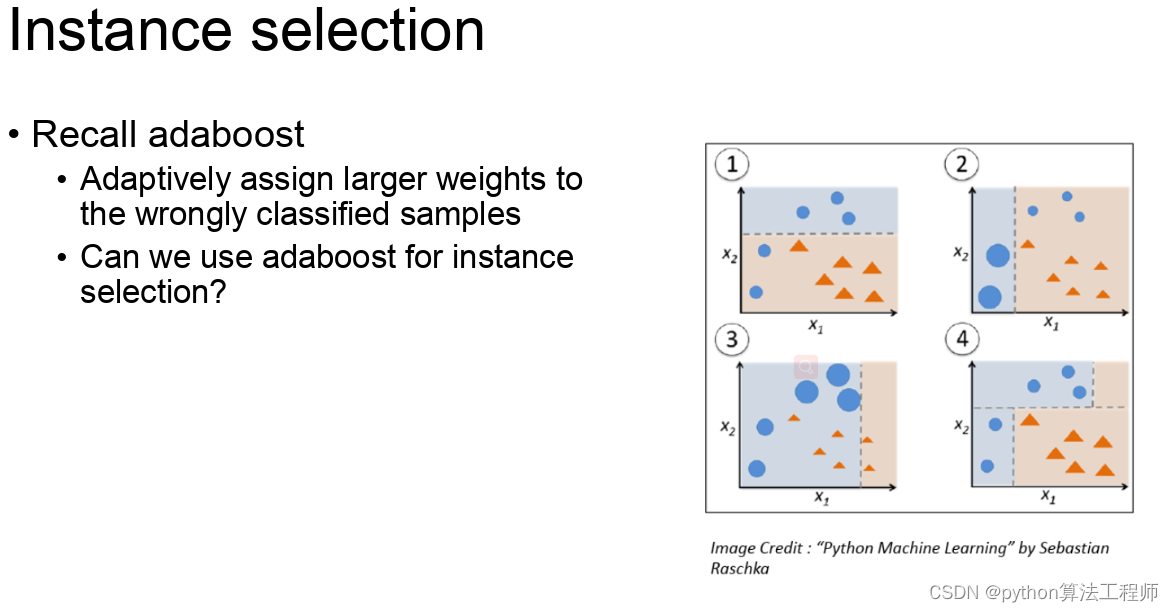





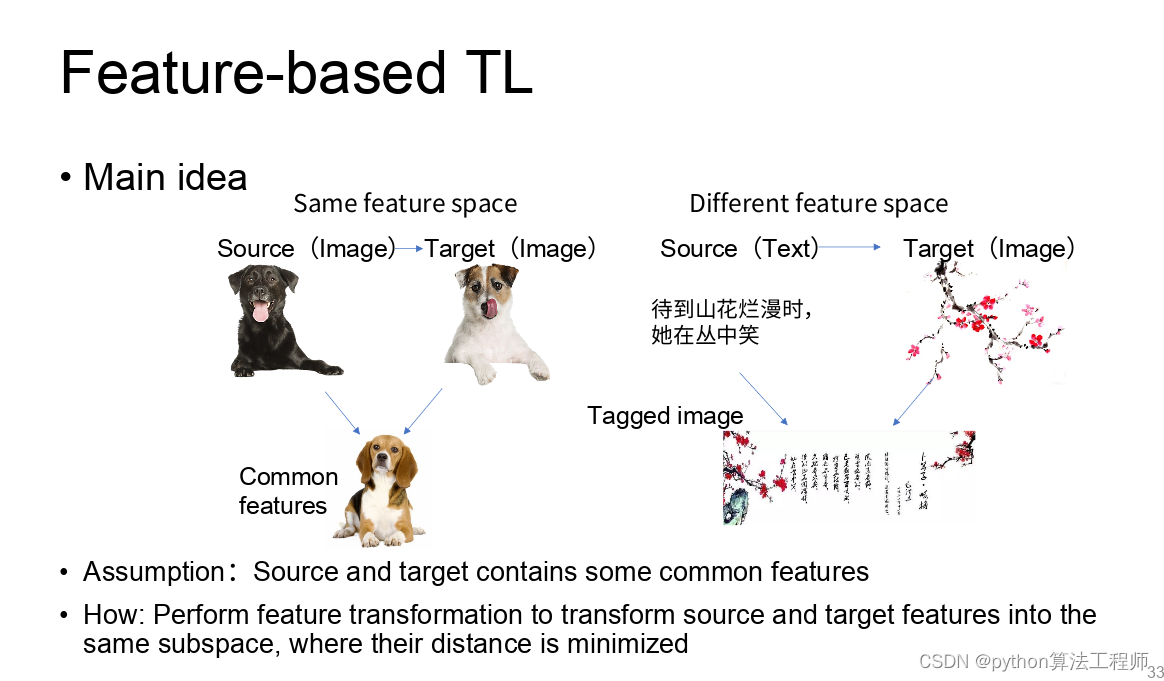






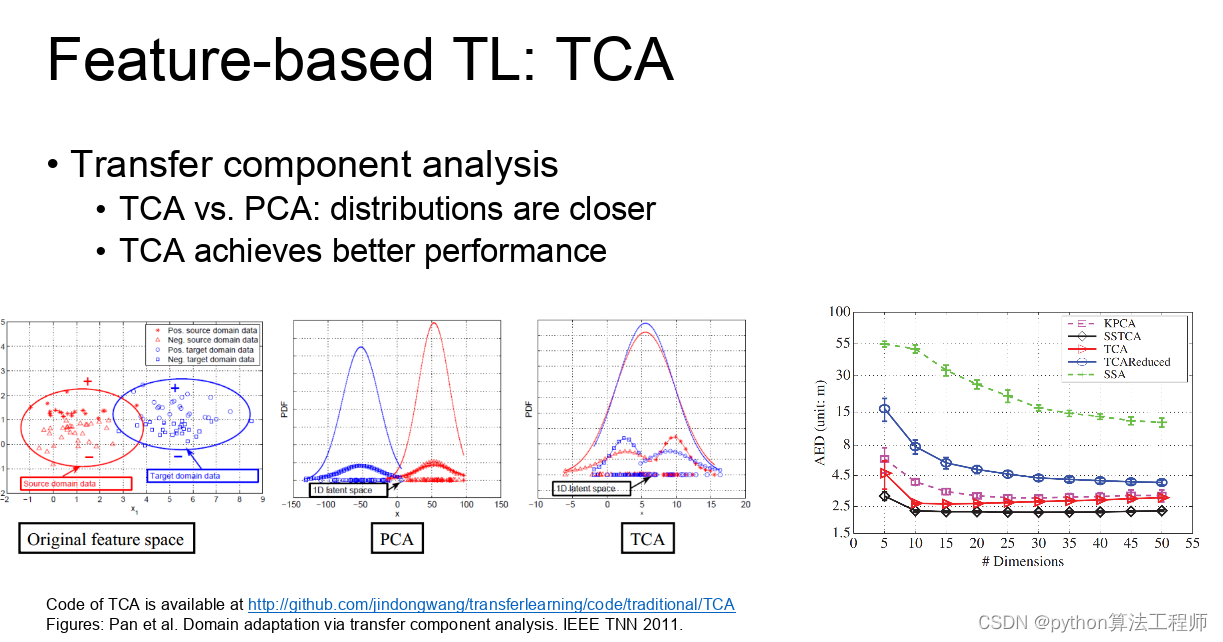

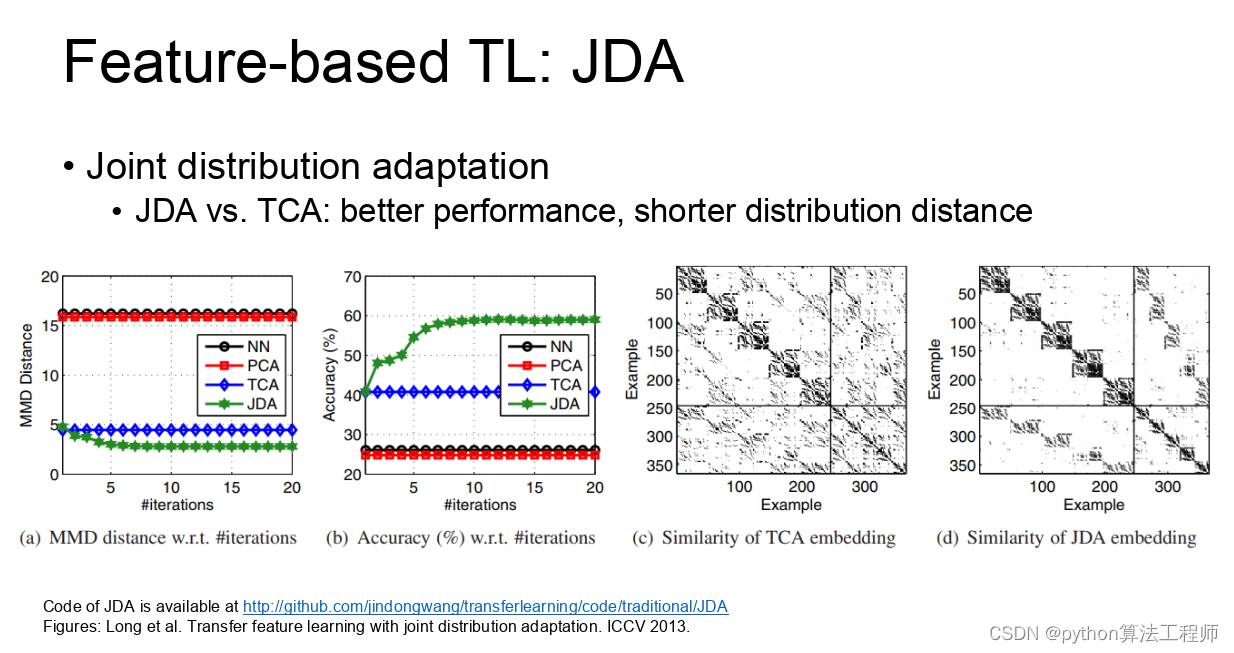
























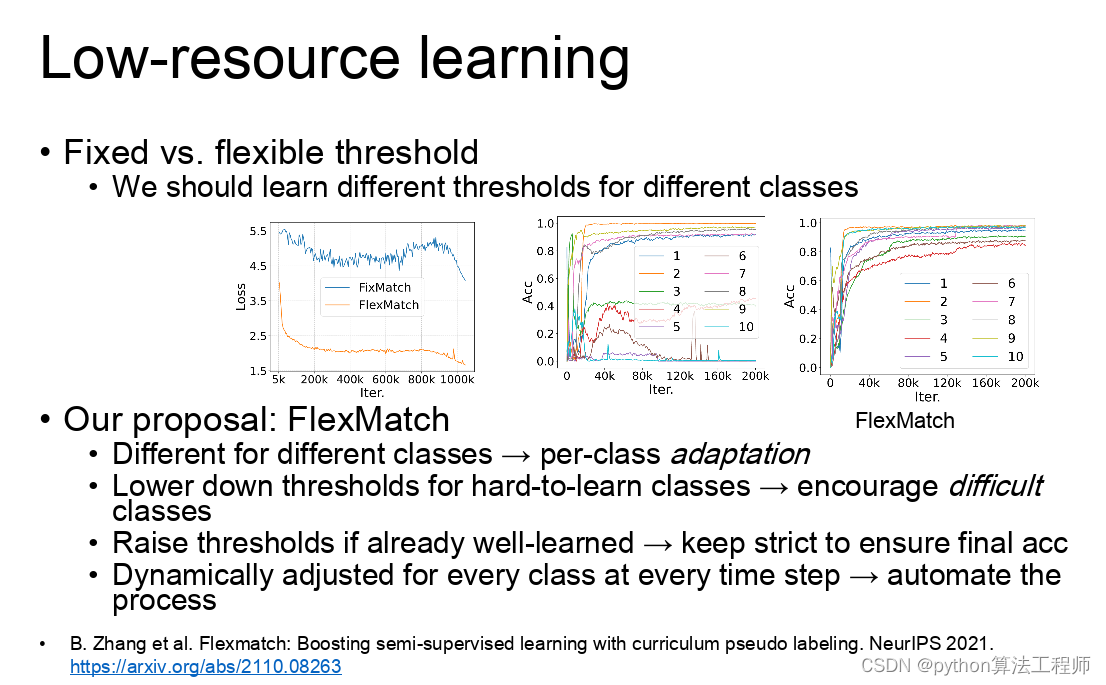

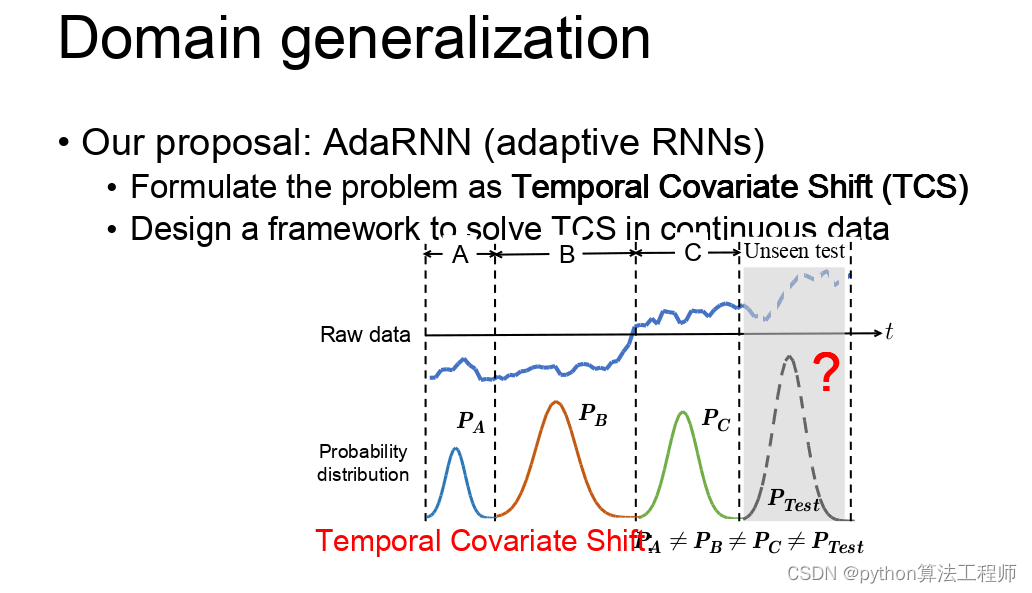
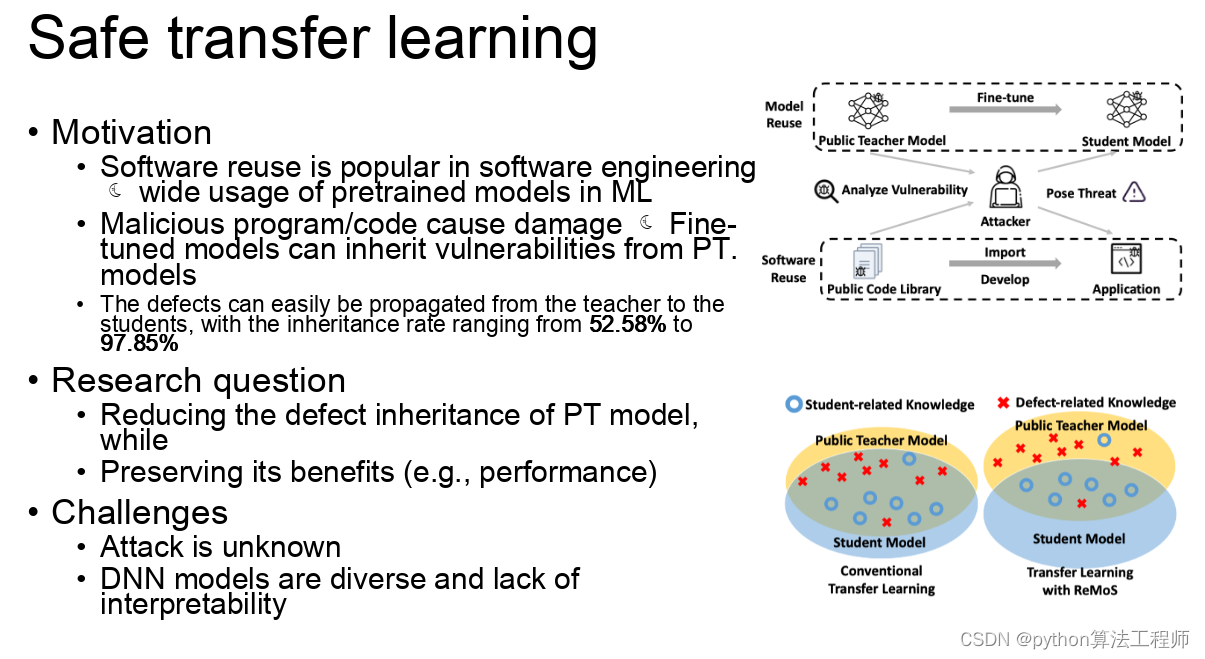



迁移学习 模型蒸馏 模型微调的区别与联系
迁移学习、模型蒸馏和模型微调都是机器学习中常用的技术,它们可以在不同的情境下被使用,有一些联系和区别,下面逐一介绍:
-
迁移学习是一种从一个领域迁移到另一个领域的技术,通过将一个任务中学习到的知识和经验迁移到另一个相关领域中,来加速和改进新领域的学习和解决问题的能力。
-
模型蒸馏是一种将一个大模型蒸馏成一个小模型的技术,通过将大模型的知识和经验转移到小模型中,来提高小模型的性能和效率。
-
模型微调是一种在一个预训练模型的基础上,通过在新的数据集上进行有监督训练,来进一步提高模型性能的技术。
联系:
迁移学习和模型微调都是将已有的知识和经验应用到新的任务或数据集中来提高性能的技术。而模型蒸馏则是在已有的知识和经验的基础上,将大模型中的一些信息压缩到小模型中,来提高小模型的性能。
区别:
迁移学习和模型微调是在不同领域或数据集之间进行迁移和调整,而模型蒸馏是在同一个领域或数据集中进行模型压缩。此外,迁移学习和模型微调都是将已有的知识和经验应用到新的任务或数据集中进行训练,而模型蒸馏则是将大模型中的知识和经验传递到小模型中。
总之,这三种技术都有其独特的优势和应用场景,可以根据具体的任务和数据集来选择合适的技术来提高模型的性能和效率。
Pre-train and fine-tune:预训练-微调
预训练-微调(Pre-train and fine-tune)是一种机器学习中常用的技术,主要应用于自然语言处理和计算机视觉领域。以下将分别具体讲解这两个领域中的预训练-微调流程。
自然语言处理领域:
在自然语言处理领域中,预训练-微调通常是指先在大规模的语料库上进行无监督的预训练,得到一个通用的语言模型,然后在特定的任务上进行有监督的微调,以适应特定的任务。具体的流程如下:
-
预训练阶段:使用无监督的方法在大规模语料库上训练一个通用的语言模型。例如,BERT模型就是使用掩码语言模型和下一句预测任务在大规模的文本数据上进行预训练的。
-
微调阶段:在预训练之后,将预训练的模型在特定的任务上进行微调,以适应特定的任务。例如,在情感分类任务中,可以在情感分类数据集上对预训练的BERT模型进行微调,以使其更好地适应情感分类任务。
计算机视觉领域:
在计算机视觉领域中,预训练-微调通常是指先在大规模的图像数据集上进行无监督的预训练,得到一个通用的特征提取器,然后在特定的任务上进行有监督的微调,以适应特定的任务。具体的流程如下:
-
预训练阶段:使用无监督的方法在大规模的图像数据集上训练一个通用的特征提取器。例如,ResNet、Inception等模型就是使用图像分类任务在ImageNet数据集上进行预训练的。
-
微调阶段:在预训练之后,将预训练的模型在特定的任务上进行微调,以适应特定的任务。例如,在目标检测任务中,可以在目标检测数据集上对预训练的特征提取器进行微调,以使其更好地适应目标检测任务。
总之,预训练-微调技术在自然语言处理和计算机视觉领域中得到了广泛的应用,是一种非常有效的机器学习技术,可以帮助我们快速构建高性能的模型。



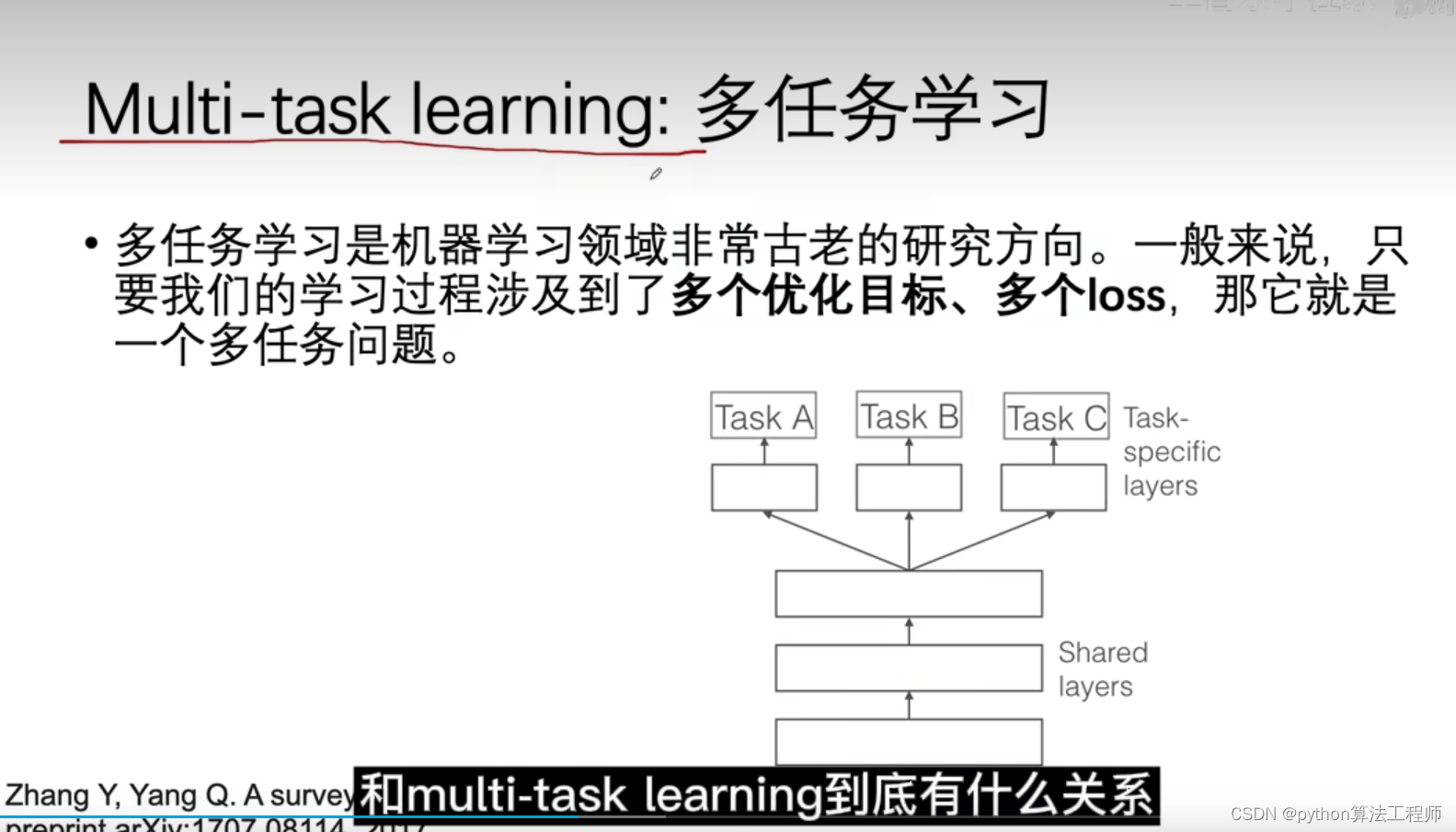
Multi-task learning:多任务学习
多任务学习(multi-task learning)是一种机器学习方法,旨在同时学习多个相关任务,以提高模型的泛化能力和性能。
在传统的单任务学习中,模型只能学习一种特定的任务,而在多任务学习中,模型可以同时学习多个相关任务,共享底层的特征表示,从而可以更好地捕捉任务之间的关联性和共性。
多任务学习的优点在于可以提高模型的泛化能力,尤其是在数据量较小的情况下,可以通过共享底层的特征表示来提高模型的表现。此外,多任务学习还可以节省训练时间和成本,提高模型训练的效率。
在多任务学习中,通常有两种方法来训练模型:联合训练和分层训练。
-
联合训练:将多个任务的数据混合在一起,共同训练一个模型。在每个训练步骤中,从每个任务的数据集中随机抽取一定比例的样本,进行训练。这种方法可以充分利用不同任务之间的相互作用,从而提高模型性能。
-
分层训练:将模型分为多层,每层对应一个任务。底层的模型参数被所有任务共享,而顶层的模型参数则是每个任务独有的。在训练过程中,先训练底层参数,然后逐层往上更新参数。这种方法适用于任务之间存在明显的层次结构的情况。
多任务学习的应用非常广泛,例如自然语言处理中的句子关系分类、命名实体识别和情感分析等任务,以及计算机视觉中的目标检测、姿态估计和分割等任务。







文章链接:https://zhuanlan.zhihu.com/p/428097044
迁移学习代码、论文仓库集合:https://github.com/jindongwang/transferlearning
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)