
K8s Crane和VPA的资源推荐算法
vpa介绍vpa全称Vertical Pod Autoscaler ,它是google论文Autopilot: Workload Autoscaling at Google Scale的开源实现。它根据pod里的container的历史监控数据来推荐container的request资源,即vpa扩容是直接修改pod里的resource的request、limit(可以在vpa资源里配置只修改re
vpa介绍
vpa全称Vertical Pod Autoscaler ,它是google论文Autopilot: Workload Autoscaling at Google Scale的开源实现。它根据pod里的container的历史监控数据来推荐container的request资源,即vpa扩容是直接修改pod里的resource的request、limit(可以在vpa资源里配置只修改request或limit和request都修改)。
功能益处:
可以提高节点的资源利用率
适合长时间运行的同质化的应用
限制:
目前版本的kubernetes不支持原地升级(原地升级预计1.27版本支持),需要重启应用来应用来使用资源推荐值
由于目前需要重启才能应用资源推荐值,不太适合有状态的服务(因为一般有状态的服务有先后启动顺序)
不适合任务型应用(大部分时间资源使用很低,短暂时间很高)或job类型应用(短时间运行,由于缺少监控数据导致推荐值过大相关issue)
不适合与hpa一起使用,可以让hpa使用custom metric或external metric,还可以借鉴Google cloud的解决方案multidimensional Pod autoscaling(memory使用vpa,cpu使用hpa)
crane介绍
Crane( Cloud Resource Analytics and Economics ) 是腾讯开源的基于 Kubernetes 的降本增效项目。Crane 遵循 FinOps 标准,旨在为云原生用户提供云成本优化一站式解决方案。具备了资源推荐,弹性推荐,智能弹性和稳定性增强等核心能力。
crane功能众多,本文只研究crane的资源推荐功能
功能优点:
一个推荐资源cr就能控制部分或全部命名空间的所有workload类型的资源推荐
相对于vpa的推荐值会比较保守(比较大),意味着更保障应用性能
监控数据源支持metrics-server和Prometheus
限制:
没有自动应用推荐值的功能,需要自己定义如何变更应用这些推荐值,意味着需要自己开发应用推荐值功能
没有推荐质量的监控指标
版本:vpa 0.13.0 crane v0.9.0
算法原理
crane和vpa都是基于历史监控数据的百分位值来计算推荐值,再对百分位的推荐值进行放大后得到最终推荐值。它们都利用histogram来计算百分位,所以先来看百分位计算方法。
利用histogram计算百分位算法
crane使用的histogram计算百分位算法
以24小时cpu监控数据,一分钟一个数据点,数值在0-100,计算95分位的数值为例子。
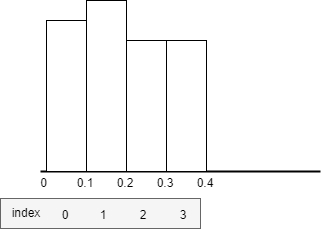
每个桶大小为0.1,桶的下标从0开始,下标为0的桶-能容纳范围
[0,0.1),最小边界值为0。下标为1桶的容纳范围为[0.1,0.2),最小边界值为0.1。将每个数据点,按照数值大小丢到对应的桶中,比如某一时刻的监控数据值为1.02,则它会丢到编号为10的桶里。
当某个桶里增加了一数据点,则这个桶的重量增加这个数据点的值,所有桶的重量增加这个数据点的值。
计算出
W(95)=95%*所有桶的总重量从最小的桶到最大桶开始累加桶的重量,这个重量记为S,当S>=W(95)时候,这个时候桶的下标为N,那么下标为N+1桶的最小边界值就是95百分位值
vpa使用的histogram计算百分位算法
以24小时cpu监控数据,一分钟一个数据点,数值在0-1000.0,计算95分位的数值为例子。
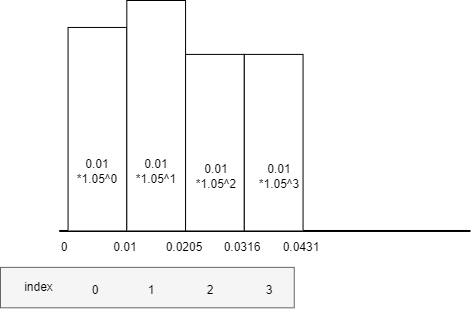
桶的下标为N,桶的大小是指数增加的
bucketSize=0.01*(1.05^N),下标为0的桶的大小为0.01,容纳范围为[0,0.01),下标为1的桶的大小为0.01*1.05^1=0.0105,容纳范围[0.01-0.0205)将每个数据点,按照数值大小丢到对应的桶中,比如某一时刻的监控数据值为0.032,则它会丢到编号为3的桶里
当某个桶里增加了一数据点,则这个桶的重量增加
固定重量*衰减系数(固定重量值和衰减系数算法后面有讲解),所有桶的重量增加固定重量*衰减系数。计算出
W(95)=95%*所有桶的总重量从最小的桶到最大桶开始累加桶的重量,这个重量记为S,当S>=W(95)时候,这个时候桶的下标为N,那么下标为N+1桶的最小边界值就是95百分位值
衰减系数和固定重量
半衰期halfLife:经过时间halfLife后,权重值降低到一半。默认的halfLife为24小时,比如现在的数据点的权重为1,那么24小时之前的监控数据点的权重为0.5,48小时前的数据点的权重为0.25,48小时后的数据权重为4。
数据点的时间timestamp:监控数据的时间戳
参考时间referenceTimestamp:监控数据上的某个时间(一般是监控时间最近的零点00:00)
核心理念:在参考时间点之前的数据点,离的越远权重越低。在参考时间点之后的数据点权重越高。
cpu资源的固定重量:0.1
memory资源的固定重量:1
衰减系数decayFactor:2^((timestamp-referenceTimestamp)/halfLife)
vpa推荐值计算过程:
vpa有4个推荐值:

vpa内部有4个Estimator推荐器和两个Processor后处理器:
percentileEstimator:利用直方桶百分位值来计算推荐值
marginEstimator:对之前的推荐值进行放大
minResourcesEstimator:应用命令行–pod-recommendation-min-cpu-millicores、–pod-recommendation-min-memory-mb的策略,推荐值不能小于这些值
confidenceMultiplier:对之前lowerBound和upperBound推荐值进行缩小和放大
IntegerCPUPostProcessor:进行cpu推荐值进行向上取整
CappingPostProcessor:应用vpa资源里container对应的最小值和最大值策略
| |
说明:
以target推荐值为例
首先进行percentileEstimator推荐得到百分位推荐值。然后将百分位推荐值传给marginEstimator,进行推荐得到marginEstimator推荐值。
再将marginEstimator推荐值传给minResourcesEstimator,进行推荐得到minResourcesEstimator推荐值。
然后如果开启了整数cpu推荐器,将minResourcesEstimator推荐值传给IntegerCPUPostProcessor进行处理,处理之后的推荐结果传给CappingPostProcessor进行处理,处理完成之后就是最终的推荐结果。
推荐器:
percentileEstimator推荐算法
其中memory的index为0桶大小为10000000,index为N的桶的大小为10000000*1.05^N,数值范围在0-1e12,总的桶数量为176
如果container发生了oom,会将oom的内存数值进行放大,oom的内存数值=max(oom时候的内存*oomBumpUpRatio, oom时候的内存+oomMinBumpUp),默认oomBumpUpRatio为1.2,oomMinBumpUp为100m。oom时间不在聚合周期且oom的内存数值大于最近的oom值和最近内存使用值、或oom时间在聚合周期内,则向histogram添加这个oom数据点。
cpu的编号为0桶大小为0.01,编号为N的桶的大小为0.01*(1.05^N),数值范围在0-1000,总的桶数量为176
推荐值=使用histogram计算百分位值–这个是最基本的推荐值
marginEstimator推荐算法
推荐值 =原先推荐值 *(1+safetyMarginFraction)
confidenceMultiplier推荐算法
相关参数
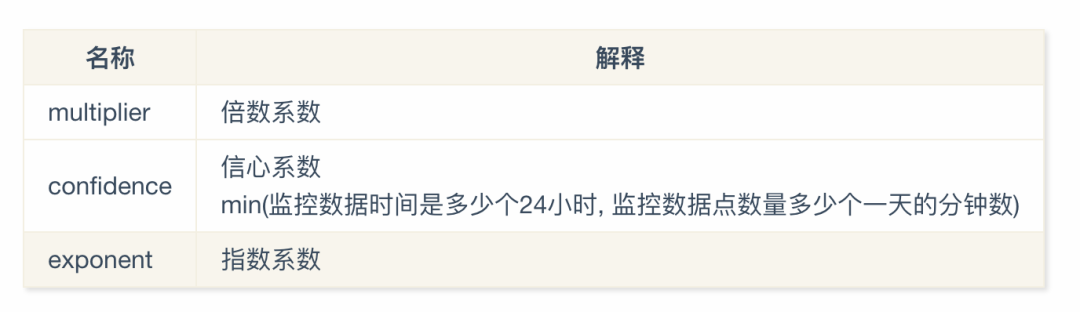
推荐值=原先推荐值*(1 + multiplier/confidence)^exponent
minResourcesEstimator推荐算法
参数

推荐值小于minResources,则推荐值设置为minResources
推荐值=max(minResources, 原先推荐值)
后处理器
IntegerCPUPostProcessor处理逻辑
只对target、lowerBound、upperBound、uncappedTarget的cpu的推荐值进行处理,对cpu推荐值进行向上取整,比如cpu推荐值为的1100m,则处理之后推荐值为2
CappingPostProcessor处理逻辑
对container的target、lowerBound、upperBound推荐值,应用container的PodResourcePolicy最小推荐值策略、应用最大值推荐值策略
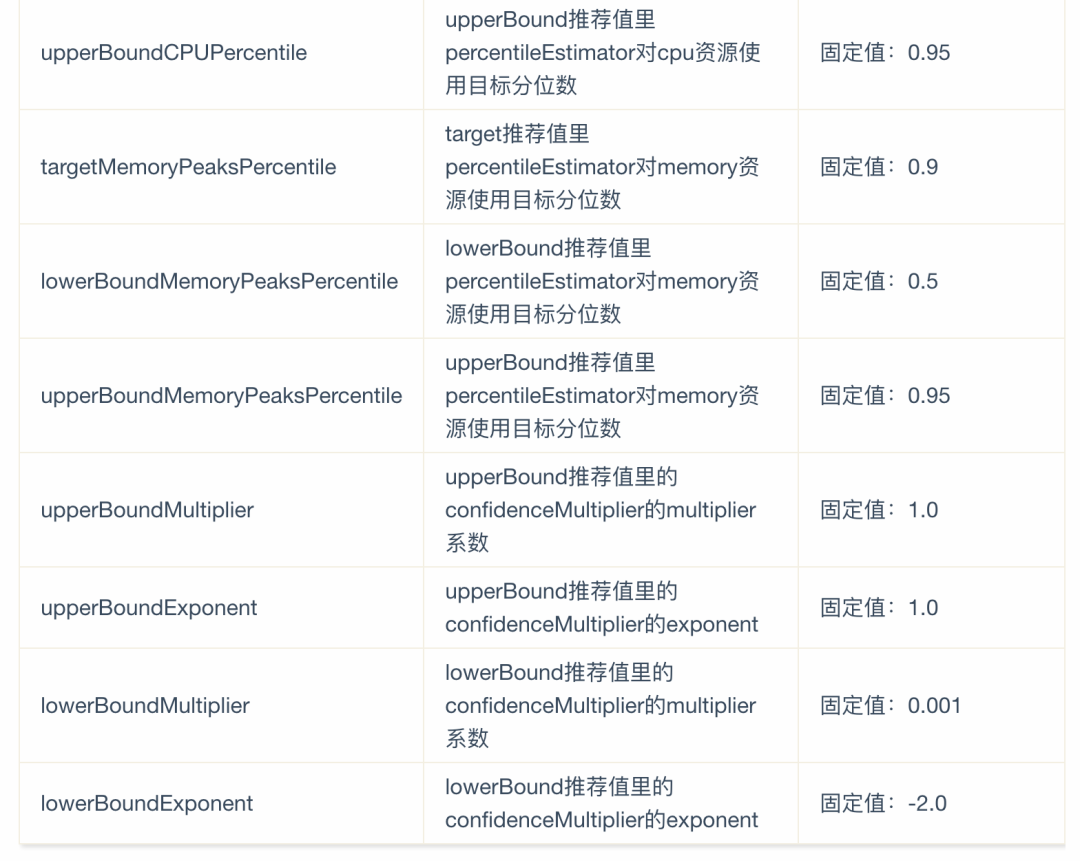
vpa的推荐相关参数
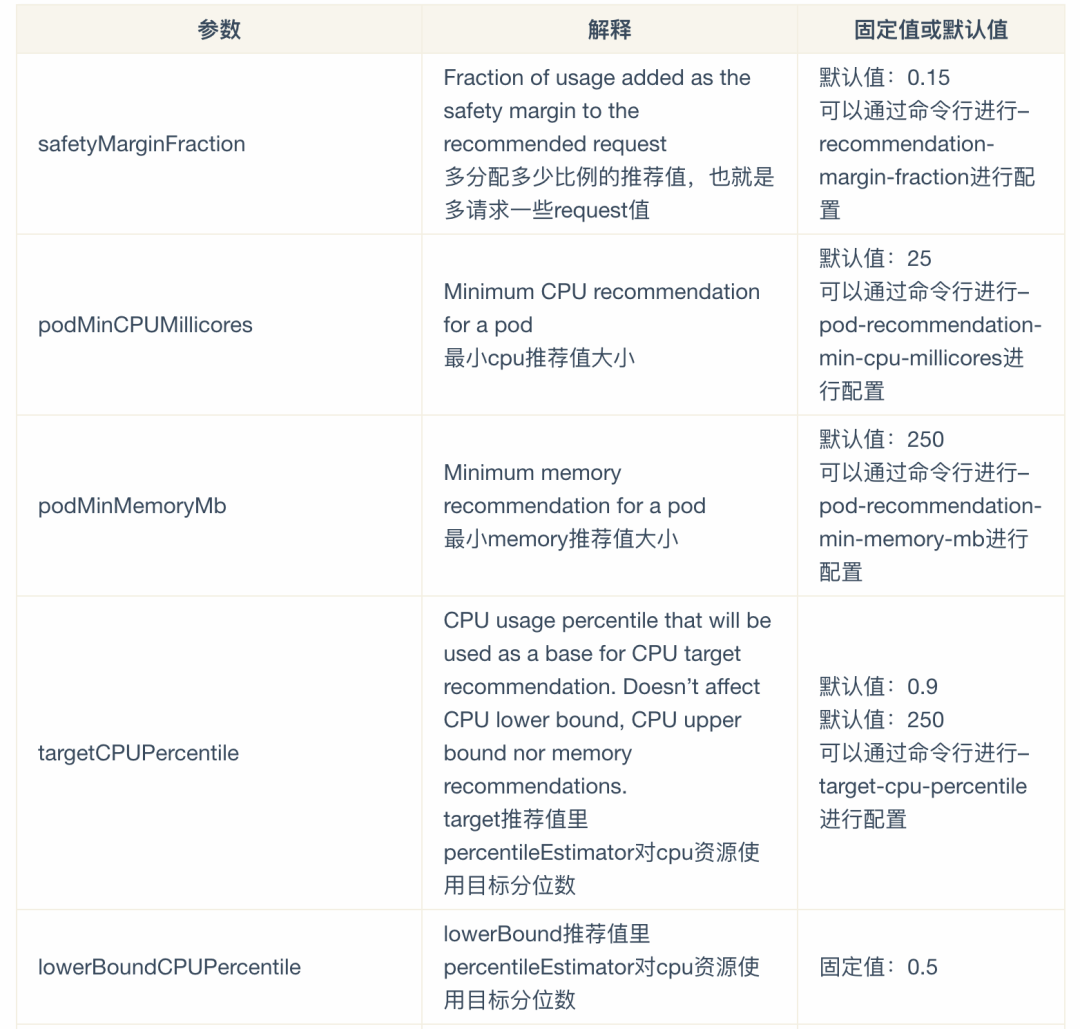
crane资源推荐
crane有5个推荐步骤:
**percentileEstimator:**利用直方桶百分位值来计算推荐值
marginEstimator:对之前的推荐值进行放大
**targetUtilizationEstimator:**对之前的推荐值进行放大,让之前推荐值占放大后的推荐值targetUtilization百分比
**NormalizedResource:**对之前的推荐值转成最适合的套餐
**MemoryOOMProtection:**内存推荐值进行放大
crane的推荐处理过程
| |
说明:
以cpu推荐值为例
首先进行percentileEstimator推荐得到百分位推荐值。然后将百分位推荐值传给marginEstimator,进行推荐得到marginEstimator推荐值。
再将marginEstimator推荐值传给targetUtilizationEstimator,进行推荐得到targetUtilizationEstimator推荐值。
然后如果开启了specification,将targetUtilizationEstimator推荐值传给NormalizedResource,进行查找specification-config里最合适的套餐,返回最终推荐值
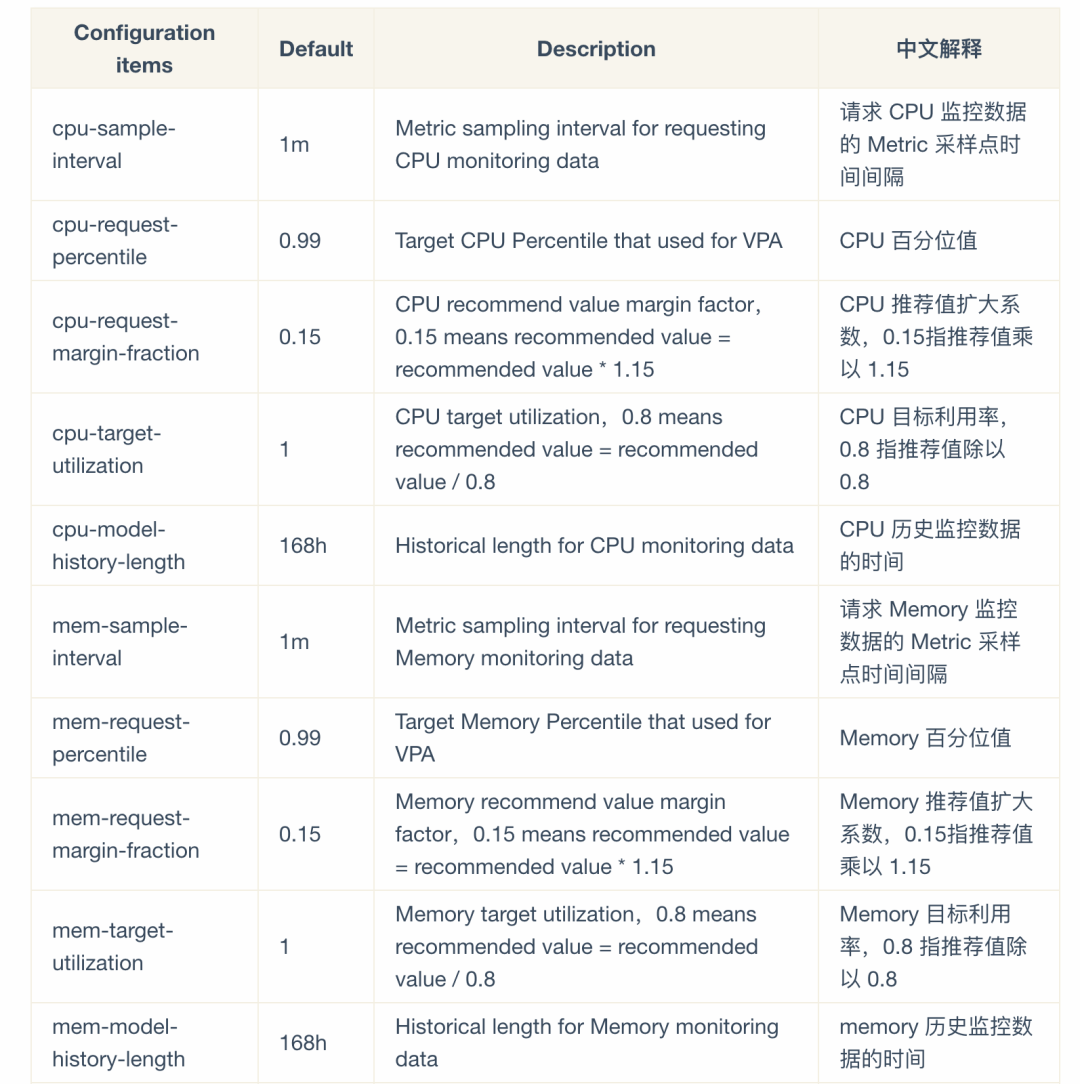
crane资源推荐相关参数

推荐器:
percentileEstimator推荐算法
其中memory桶大小104857600,数值范围为0-104857600000
cpu桶大小为0.1,数值范围0-100
推荐值=使用histogram计算百分位值–这个是最基本的推荐值
marginEstimator推荐算法
推荐值 =原先推荐值 *(1+marginFraction)
其中memory的marginFraction为mem-request-margin-fraction,cpu的marginFraction为cpu-request-margin-fraction
targetUtilizationEstimator推荐算法
推荐值=原先的推荐值/targetUtilization
其中memory的targetUtilization为mem-target-utilization,cpu的targetUtilization为cpu-target-utilization
NormalizedResource
当启用specification,从specification-config中匹配一个最小满足(大于等于)推荐值的配置套餐
MemoryOOMProtection
如果container有最近7小时内的oom事件,oom时候的内存值为oomMemory,没有oom事件则oomMemory为0
推荐值 =max( max(oomMemory+100M, oomMemory*oom-bump-ratio), 原先的推荐值)
没有提及的
vpa里histogram的referenceTimestamp相对时间的超过100个半衰期后移动,histogram数据进行scale。
相关链接
vpa不适合任务型应用原因
https://github.com/kubernetes/design-proposals-archive/blob/main/autoscaling/vertical-pod-autoscaler.md#batch-workloads
https://access.redhat.com/documentation/en-us/openshift_container_platform/4.5/html/nodes/working-with-pods#automatically-adjust-pod-resource-levels-with-the-vertical-pod-autoscaler
https://www.kubecost.com/kubernetes-autoscaling/kubernetes-vpa/
https://cloud.google.com/kubernetes-engine/docs/concepts/verticalpodautoscaler
https://www.densify.com/kubernetes-autoscaling/kubernetes-vpa/
https://povilasv.me/vertical-Pod-autoscaling-the-definitive-guide/#
推荐
随手关注或者”在看“,诚挚感谢!

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)