

深入浅出Python量化交易实战--第3章-机器学习在交易中的简单应用(下)
虽然这里使用的KNN 分类模型的准确率并不高,但是使用该模型进行涨跌预测后,进行交易 的收益还是高于该股票的基准收益的。在本章中,小瓦提出一个非常不错的想法——使用机器学习算法来 预测股票的涨跌,并据此创建交易策略来执行订单,因此我们和小瓦一 起学习了机器学习的基本概念,并以KNN算法为例,展示了机器学习工 具的使用方法。接下来,我们就使用上一步中定义的函数来处理下载好的股票数 据,生成训练集与验
3.3 基于机器学习的简单交易策略
至此,小瓦已经对KNN分类和回归模型有了基本的了解。当然除了 KNN之外,还有很多算法可以供我们进行选择,如决策树、支持向量 机、线性回归、逻辑回归等。接下来我们就使用最简单的KNN算法,基 于真实的股票数据集来制订交易策略,并计算它所带来的收益。
首先我们使用之前学过的tushare来获取股票数据,这里需要导入 一些必要的库,输入代码如下:
#导入Pandas
import pandas as pd
#导入金融数据获取模块tushare
import tushare as ts
#导入numpy,一会儿会用到
import numpy as np
#首先导入鸢尾花数据载入工具
from sklearn.datasets import load_iris
#导入KNN分类模型
from sklearn.neighbors import KNeighborsClassifier
#为了方便可视化,我们再导入matplotlib和seaborn
import matplotlib.pyplot as plt
import seaborn as sns
# 导入数据集拆分工具
from sklearn.model_selection import train_test_split
pd.set_option('expand_frame_repr', False) # True就是可以换行显示。设置成False的时候不允许换行
pd.set_option('display.max_columns', None) # 显示所有列
pd.set_option('display.max_rows', None) # 显示所有行
pd.set_option('colheader_justify', 'centre') # 显示居中
运行代码,如果程序没有报错,就说明导入成功。接下来,我们可 以定义一个获取股票数据的函数,以便未来还可以复用。输入代码如 下:
# 首先我们来定义一个函数,用来获取数据
# 传入的参数分别是股票代码,开始时间、结束时间
def load_stock(ts_code, start, end):
ts.set_token('你的token')
pro = ts.pro_api()
df = pro.daily(ts_code=ts_code, start_date=start, end_date=end)
df.sort_values('trade_date', inplace=True)
df.set_index('trade_date', inplace=True)
return df
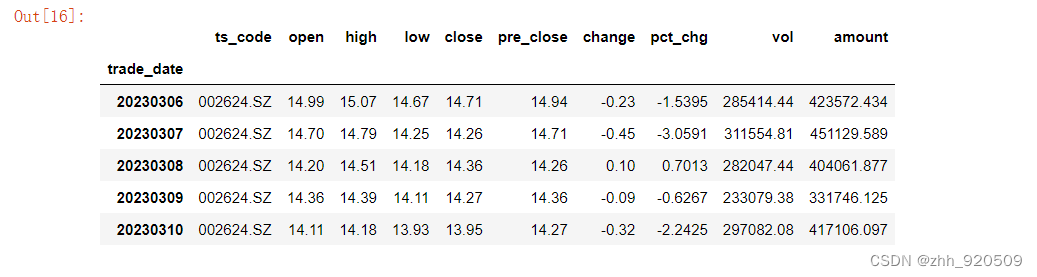
zgpa = load_stock(ts_code='002624.SZ', start='19900101', end='20230310')
zgpa.tail()
备注:
#设置token
s.set_token('你的token')
需要去tushare官网注册账户,就有了你的token,登录后个人主页中找
3.3.2 创建交易条件
接下来我们做一点简单的特征工程,以便进行后面的工作。这里用 每日开盘价减去收盘价,并保存为一个新的特征;用最高价减去最低 价,保存成另外一个特征。同时,如果股票次日收盘价高于当日收盘 价,则标记为1,代表次日股票价格上涨;反之,如果次日收盘价低于 当日收盘价,则标记为-1,代表股票次日价格下跌或者不变。这个过程 可以称为创建股票的交易条件(trading condition)。
输入代码如下:
# 下面我们来定义一个用于分类的函数,给数据表增加三个字段
# 首先是开盘价减去收盘价,命名为open-close
# 其次是最高价减去最低价,命名为high-low
def classification_tc(df):
df['open-close'] = df['open'] - df['close']
df['high-low'] = df['high'] - df['low']
# 添加一个target字段,如果次日收盘价高于当日收盘价,则标记为1,反之为-1
df['target'] = np.where(df['close'].shift(-1)>df['close'], 1, -1)
# 去掉有空值的行
df =df.dropna()
# print(df.tail(9))
# 将open-close和high-low作为数据集的特征
X = df[['open-close', 'high-low']]
# 将target值给y
y = df['target']
return(X, y)
# x,y=classification_tc(zgpa)
# print(x.tail())
# print(y.tail()) 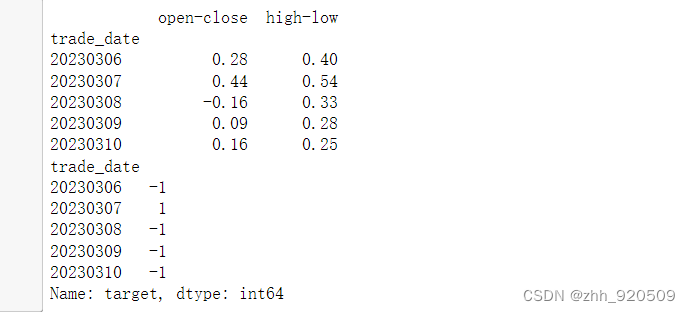
运行代码,就完成了这个函数的定义。由于我们通过股票价格变化 的情况对数据进行了分类,即1代表价格上涨,–1代表价格下跌或不 变,这个交易条件可以用来训练分类模型。让模型预测某只股票在下一 个交易日价格上涨与否。
如果要创建用于回归模型的交易条件,则可以对代码稍做调整,将 次日收盘价减去当日收盘价的差作为预测的目标。这样就可以训练回归 模型,使其预测次日股价上涨(或下跌)的幅度。输入代码如下:
# 下面定义一个用于回归的函数
# 特征的添加与分类函数类似
# 只不过target字段改为次日收盘价减去当日收盘价
def regression_tc(df):
df['open-close'] = df['open'] - df['close']
df['high-low'] = df['high'] - df['low']
# 添加一个target字段,如果次日收盘价高于当日收盘价,则标记为1,反之为-1
df['target'] = df['close'].shift(-1) - df['close']
# 去掉有空值的行
df =df.dropna()
# print(df.tail(9))
# 将open-close和high-low作为数据集的特征
X = df[['open-close', 'high-low']]
# 将target值给y
y = df['target']
return(X, y)
x,y=regression_tc(zgpa)
print(x.tail())
print(y.tail()) 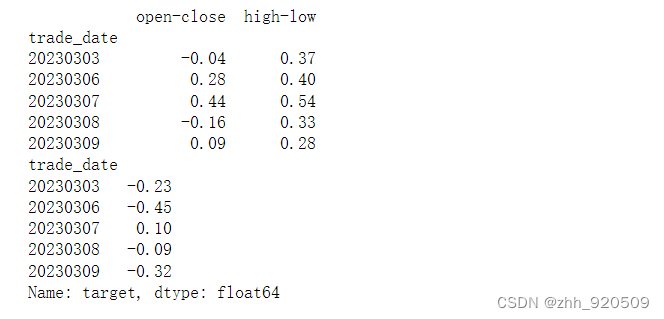
运行代码即可完成回归交易条件函数的定义。与分类交易条件一 样,我们同样是把股票当日的开盘价和收盘价的差,与最高价和最低价 的差作为样本的特征。不同的是,预测目标变成了次日收盘价与当日收 盘价的差。
接下来,我们就使用上一步中定义的函数来处理下载好的股票数 据,生成训练集与验证集,并训练一个简单的模型,以执行我们的交易 策略。输入代码如下:
#使用classification_tc函数生成数据集的特征与目标
X, y = classification_tc(zgpa)
#将数据集拆分为训练集与验证集
X_train, X_test, y_train, y_test =\
train_test_split(X, y, train_size=0.8)
运行代码后,我们会得到训练集与预测集。现在就使用KNN算法来 进行模型的训练,并查看模型的性能。输入代码如下:
#创建一个KNN实例,n_neighbors取95
knn_clf = KNeighborsClassifier(n_neighbors=95)
#使用KNN拟合训练集
knn_clf.fit(X_train, y_train)
#输出模型在训练集中的准确率
print(knn_clf.score(X_train, y_train))
#输出模型在验证集中的准确率
print(knn_clf.score(X_test, y_test)) 
【结果分析】从代码运行结果可以看到,使用经处理的数据集训练 的KNN模型,在训练集中的准确率是54%左右,在验证集中的准确率也 是51%左右。这个准确率远谈不上理想,相当于只有一半时间里模型对 股价的涨跌预测正确。原因是我们训练模型的样本特征确实太少了,无 法支撑模型做出正确的判断。不过大家也不要担心,我们只是初步做一 个演示而已。
既然模型已经可以做出预测(先不论准确率如何),接下来我们就 可以来验证一下,使用模型预测作为交易信号(trading signal)来进行 交易,并且与基准收益进行对比。首先我们要计算出基准收益和基于模 型预测的策略所带来的收益。输入代码如下:
#使用KNN模型预测每日股票的涨跌,保存为Predict_Signal
zgpa['predict_signal'] = knn_clf.predict(X)
#在数据集中添加一个字段,用当日收盘价除以前一日收盘价,并取其自然对数
zgpa['return'] = np.log(zgpa['close']/zgpa['close'].shift(1))
#查看一下
zgpa.tail()
【结果分析】从输出中可以看到,数据表中的Predict_Signal存储 的是KNN模型对股票涨跌的预测,而Return是指当日股票价格变动所带 来的收益。 下面我们定义一个函数,计算一下累计的基准收益。输入代码如 下:
# 定义一个计算累计基准收益的函数
def cum_return(df, split_value):
# 该股票基准收益的总和乘以100,这里只计算预测集的结果
cum_returns = df[split_value:]['return'].cumsum()*100
# 将计算结果进行返回
return cum_returns
运行代码,就完成了这个函数的定义。接下来我们再定义一个函 数,计算基于KNN模型预测的交易信号所进行的策略交易带来的收益。 输入代码如下:
# 定义一个计算使用策略交易的收益
def stratrgy_return(df, split_value):
# 使用策略交易的收益为模型乘以模型预测的涨跌幅
df['stratrgy_return'] = df['return'] * df['predict_signal'].shift(1)
# 将每日策略交易的收益加和并乘以100
cum_strategy_return = df[split_value:]['stratrgy_return'].cumsum()*100
return cum_strategy_return
定义完上面的函数之后,我们就可以很快计算出算法模型所带来的 累计收益了。为了方便对比,我们再来定义一个进行可视化的函数,输 入代码如下:
# 定义一个绘图函数,用于对比基准收益和算法交易的收益
def plot_chart(cum_return, cum_strategy_return, symbol):
plt.figure(figsize=(9,6))
plt.plot(cum_return, '--', label='%s Returns'%symbol)
plt.plot(cum_strategy_return, label='StrategyReturns')
plt.legend()
plt.show()
绘图函数定义好之后,我们就可以对KNN模型带来的策略收益和基 准收益进行对比了。输入代码如下:
cum_return = cum_return(zgpa, split_value=len(X_train))
cum_strategy_return = stratrgy_return(zgpa, split_value=len(X_train))
plot_chart(cum_return, cum_strategy_return, 'zgpa') 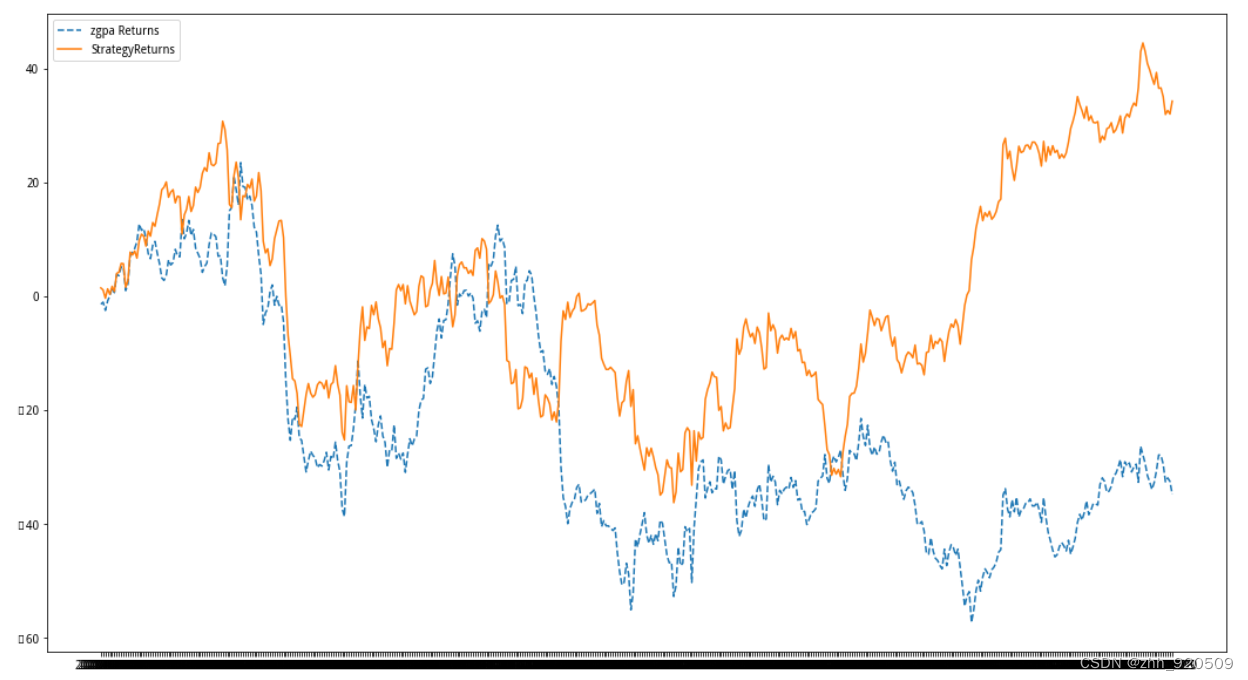
【结果分析】从输出图中可以看到,虚线部分是该股票的累积基准 收益,实线部分是使用算法进行交易的累计收益。虽然这里使用的KNN 分类模型的准确率并不高,但是使用该模型进行涨跌预测后,进行交易 的收益还是高于该股票的基准收益的。如果我们通过补充因子(或者说 数据集的特征)的方法来进一步提高模型的准确率的话,则算法交易带 来的收益还会显著提高。 注意:与第2章所使用的回测方式不同,这里我们通过对算法交易 收益与基准收益的对比来评估策略的业绩,而这种方法在实际应用中 更加普遍。
3.4 小结
在本章中,小瓦提出一个非常不错的想法——使用机器学习算法来 预测股票的涨跌,并据此创建交易策略来执行订单,因此我们和小瓦一 起学习了机器学习的基本概念,并以KNN算法为例,展示了机器学习工 具的使用方法。当然,由于本章中用来训练模型的样本数据维度比较 少,模型的性能表现也就谈不上出色。即便如此,基于KNN算法设计的 交易策略,收益率仍然明显领先基准收益。在第4章中,我们就要研究 如何补充数据维度,进一步提升模型的性能。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)