

LeetCode专题:滑动窗口(持续更新,已更17题)
持续更新LeetCode的滑动窗口专题刷题总结,实际少于24道,题目分类参考了宫水三叶https://github.com/SharingSource/LogicStack-LeetCode/wiki。
目录
LeetCode713.乘积小于K的子数组:
问题描述:
给你一个整数数组
nums和一个整数k,请你返回子数组内所有元素的乘积严格小于k的连续子数组的数目。
示例 1:
输入:nums = [10,5,2,6], k = 100 输出:8 解释:8 个乘积小于 100 的子数组分别为:[10]、[5]、[2],、[6]、[10,5]、[5,2]、[2,6]、[5,2,6]。 需要注意的是 [10,5,2] 并不是乘积小于 100 的子数组。
代码分析:
本题与 剑指 Offer II 009. 乘积小于 K 的子数组 相同。
然后这题跟209. 长度最小的子数组是一个方法,理解这题后可以用209这题巩固巩固。 (209这题是维护窗口最小长度,本题是维护窗口最大长度)
本题力扣官解法一学有余力再看一看,重点学习滑窗。
解法一:双指针滑窗
滑窗算是双指针中的特殊情况。要理解滑窗很重要的是理解两个滑窗边界有什么意义。滑窗可能分为固定窗口大小和变长窗口大小,这题便是变长窗口,我们要理解为什么窗口是变长的。
- 我们要维护一个滑窗。窗口不断向右滑动,窗口右边界(r)为固定轴,左边界(l)则是一个变动轴。
此窗口代表的意义为:以窗口右边界为结束点的区间,其满足乘积小于k所能维持的最大窗口。因此,本题最重要的是求窗口在每个位置时,窗口的最大长度。(最大长度是重点)
最终的答案便是窗口在每个位置的最大长度的累计和。
为什么呢?这个就需要我们找规律了。因为针对上一位置的窗口,移动一次后相对增加出来的个数便是r-l+1。
我们可以从前往后处理所有的 nums[i],使用一个变量 cur 记录当前窗口的乘积,使用两个变量 j 和 i 分别代表当前窗口的左右端点。当 cur>=k 时,我们考虑将左端点 j 右移,同时消除原来左端点元素 nums[j] 对 cur 的贡献,直到 cur>=k 不再满足,这样我们就可以得到每个右端点 nums[i] 的最远左端点 nums[j]。
做完本题后我们来总结一下相关的模板。
class Solution {
public int numSubarrayProductLessThanK(int[] nums, int k) {
int n = nums.length, ans = 0;
if (k <= 1) return 0;
for (int i = 0, j = 0, cur = 1; i < n; i++) {
cur *= nums[i];
while (cur >= k) cur /= nums[j++];
ans += i - j + 1;
}
return ans;
}
}
作者:宫水三叶扩展部分:滑动窗口解题模板
- 滑动窗口 + 变量计数模板:例如 1004.最大连续1的个数 III(此处不再贴出请自行练习)
class Solution { public int slidingWindow(int[] nums, int k) { //数组/字符串长度 int n = nums.length; //双指针,表示当前遍历的区间[left, right],闭区间 int left = 0, right = 0; //定义变量统计 子数组/子区间 是否有效 int sum = 0; //定义变量动态保存最大 求和/计数 int res = 0; //右指针遍历到数组尾 while (right < n) { //增加当前右指针对应的数值 sum += nums[right]; //当在该区间内 sum 超出定义范围 while (sum > k) { //先将左指针指向的数值减去 sum -= nums[left]; //左指针右移 left++; } //到 while 结束时,我们找到了一个符合题意要求的 子数组/子串 res = Math.max(res, right - left + 1); //移动右指针,去探索下一个区间 right++; } return res; } } 作者:腌菜读作梦想
- 滑动窗口 + 哈希表存储模板:例如 567.字符串的排列 、76. 最小覆盖子串、
3. 无重复字符的最长子串、
438.找到字符串中所有字母异位词 (三题的题解将直接以代码注释的形式贴出)class Solution { public String slidingWindow(String s, String t) { //创建两个哈希表,分别记录 [需要的] 和 [加入的] Map<Character, Integer> need = new HashMap<>(); Map<Character, Integer> map = new HashMap<>(); //创建 [双指针] 和 [有效数量] int left = 0, right = 0; int valid = 0; //外层循环,供右指针遍历 while(right < s.length()){ //创建临时 c 字符,是移入 窗口 内的字符 char c = s.charAt(right); 进行窗口一系列逻辑更新 ... //判断左指针是否要右移即窗口收缩:有效数量足够满足条件 /* 可能是规定的窗口大小超出了,可能是有效值数量达成了 1. while(valid == need.size()) 2. while(right - left + 1 >= s1.length()) */ while(windows need shrink){ // 创建 d 是要移除窗口的字符 char d = s.charAt(left); left++; //进行窗口一系列逻辑更新 ... } //右指针右移 right++; } } } 作者:腌菜读作梦想需要注意的是:
unordered_map 就是哈希表(字典),它的一个方法 count(key) 相当于 Java 的 containsKey(key) 可以判断键 key 是否存在。
可以使用方括号访问键对应的值
map[key]。需要注意的是,如果该key不存在,C++ 会自动创建这个 key,并把map[key]赋值为 0。Java 的
map.put(key, map.getOrDefault(key, 0) + 1)相当于C++的map[key]++。
LeetCode567.字符串的排列:
这种题目,是明显的滑动窗口算法,相当给你一个 S 和一个 T,请问你 S 中是否存在一个子串,包含 T 中所有字符且不包含其他字符。由于排列不会改变字符串中每个字符的个数,所以只有当两个字符串每个字符的个数均相等时,一个字符串才是另一个字符串的排列。
class Solution { public boolean checkInclusion(String s1, String s2) { Map<Character, Integer> need = new HashMap<>(); 滑动窗口 + 两哈希,始终保证窗口长度,当长度超了s1.length(),左指针准备右移 Map<Character, Integer> map = new HashMap<>(); int left = 0, right = 0; 当发现有效值长度 valid == need.size() 时,就说明窗口map中就是一个合法的排列,所以立即返回 true。 int valid = 0; //统计s1词频 for(Character c : s1.toCharArray()) { need.put(c, need.getOrDefault(c, 0) + 1); } while(right < s2.length()) { char c = s2.charAt(right); 进行窗口内数据的一系列更新 if(need.containsKey(c)) { map.put(c, map.getOrDefault(c, 0) + 1); //map[c]++ if(need.get(c).equals(map.get(c))) { valid++; } } 判断左侧窗口是否要收缩,保证窗口的大小始终和需要查找的字串一致 是 >= 而不是 > 的原因: 假设目标字串长度是2,如果是 > 的话,此时窗口内有两个元素, 下一轮增加窗口的时候再加入一个就是3个元素的, 超出了子串长度但却有可能返回true while(right - left + 1 >= s1.length()) { 在这里判断是否找到了合法的子串 if(valid == need.size()) { return true; } d是需要移出窗口的元素 进行窗口内数据的一系列更新 char d = s2.charAt(left); if(need.containsKey(d)) { if(need.get(d).equals(map.get(d))) { valid--; } map.put(d, map.get(d) - 1); //map[d]-- } left++; } right++; } return false; } }当然此方法有一定的理解难度,我们还可以使用之前的双指针滑窗来解决。
左程云大神提供了一种有趣的思路:
通过一个记账本 charCount 做为【总账表】维护s1的词频表; 滑动窗口内每一个右边界字符进入窗口后,【还账】:charCount[str2[r] - 'a']-- 如果某个字符多还了(变成负值),即尝试失败,开始尝试下一个左端点(l++); 左边界字符出窗口后,表示【重新赊账】:charCount[str2[l] - 'a']++ 最终如果欠账还足了(窗口长度达到len1),则尝试成功,直接返回true。public static boolean checkInclusion(String s1, String s2) { char[] str1 = s1.toCharArray(); char[] str2 = s2.toCharArray(); int len1 = s1.length(); int len2 = s2.length(); int[] charCount = new int[26]; // 【总欠账表】:s1的词频表 for (char c : str1) { // 统计s1的词频 charCount[c - 'a']++; } int l = 0, r = 0; // 滑动窗口左右边界 // 依次尝试固定以s2中的每一个位置l作为左端点开始的len1长度的子串s2[l ... l+len1)是否是s1的排列 while (l <= len2 - len1) { // 固定左端点只需要尝试到len2-len1即可 // 右边界s2[r]字符进入窗口【还账】 while (r < l + len1 && charCount[str2[r] - 'a'] >= 1) { charCount[str2[r] - 'a']--; // 【"还账"】 r++; } if (r == l + len1) return true; // 左边界s2[l]字符出窗口【赊账】,l++,开始尝试固定下一个位置做左端点 此程序直接排除了r>l+len1的可能,若要开始尝试固定下一个位置做左端点,则表明 r!=l+len1并且当前str2[r]多还了 charCount[str2[l] - 'a']++; // 重新【"赊账"】 l++; } return false; // 所有的左端点均尝试还账失败,不可能再有答案了 } 作者:seven
LeetCode76.最小覆盖子串:
要在
S(source) 中找到包含T(target) 中全部字母的一个子串,且这个子串一定是所有可能子串中最短的。(处理窗口的扩大和缩小和上一题相同)具体思路为:
- 我们先不断地增加
right指针扩大窗口[left, right),直到窗口中的字符串符合要求(包含了T中的所有字符)。【相当于在寻找一个「可行解」】此时,我们停止增加 right,转而不断增加 left 指针缩小窗口 [left, right),直到窗口中的字符串不再符合要求(不包含 T 中的所有字符了)。同时,每次增加 left,我们都要更新一轮结果。【相当于优化这个「可行解」,最终找到最优解,也就是最短的覆盖子串】
如果一个字符进入窗口,应该增加 map 计数器;如果一个字符将移出窗口的时候,应该减少 map 计数器;当 valid 满足 need 时应该收缩窗口;应该在收缩窗口的时候更新最终结果。
string minWindow(string s, string t) { unordered_map<char, int> need, window; for (char c : t) need[c]++; int left = 0, right = 0; int valid = 0; // 记录最小覆盖子串的起始索引及长度 int start = 0, len = INT_MAX; while (right < s.size()) { // c 是将移入窗口的字符 char c = s[right]; // 进行窗口内数据的一系列更新 if (need.count(c)) { window[c]++; if (window[c] == need[c]) valid++; } // 判断左侧窗口是否要收缩 while (valid == need.size()) { // 在这里更新最小覆盖子串 if (right - left + 1 < len) { start = left; len = right - left + 1; } // d 是将移出窗口的字符 char d = s[left]; // 进行窗口内数据的一系列更新 if (need.count(d)) { window[d]--; if (window[d] == need[d]) valid--; } // 左移窗口 left++; } // 右移窗口 right++; } // 返回最小覆盖子串 return len == INT_MAX ? "" : s.substr(start, len); } 作者:labuladong
LeetCode438.找到字符串中所有字母异位词:
相当于,输入一个串S,一个串T,找到S中所有T的排列,返回它们的起始索引。
在上题的基础上改改即可。
vector<int> findAnagrams(string s, string t) { unordered_map<char, int> need, map; for (char c : t) need[c]++; int left = 0, right = 0; int valid = 0; vector<int> res; // 记录结果 while (right < s.size()) { char c = s[right]; right++; // 进行窗口内数据的一系列更新 if (need.count(c)) { window[c]++; if (window[c] == need[c]) valid++; } // 判断左侧窗口是否要收缩 while (right - left >= t.size()) { // 当窗口符合条件时,把起始索引加入 res if (valid == need.size()) res.push_back(left); char d = s[left]; left++; // 进行窗口内数据的一系列更新 if (need.count(d)) { if (window[d] == need[d]) valid--; window[d]--; } } } return res; } 作者:labuladong
LeetCode3.无重复字符的最长子串:
这个题终于有了点新意,不是一套框架就出答案,不过反而更简单了,稍微改一改框架就行了:
class Solution { public: int lengthOfLongestSubstring(string s) { unordered_map<char, int> map; int left = 0, right = 0; int res = 0; while(right < s.size()) { char c = s[right]; map[c]++; while(map[c] >= 2) { char d = s[left]; map[d]--; left++; } res = max(res, right - left + 1); right++; } return res; } };当map[c]值大于 1 时,说明窗口中存在重复字符,不符合条件,就该移动
left缩小窗口了。唯一需要注意的是,在哪里更新结果
res呢?我们要的是最长无重复子串,哪一个阶段可以保证窗口中的字符串是没有重复的呢?在收缩窗口完成后更新res!因为窗口收缩的 while 条件是存在重复元素,换句话说收缩完成后一定保证窗口中没有重复。
LeetCode30.串联所有单词的子串(难):
问题描述:
给定一个字符串
s和一个字符串数组words。words中所有字符串 长度相同。
s中的 串联子串 是指一个包含words中所有字符串以任意顺序排列连接起来的子串。返回所有串联字串在
s中的开始索引。你可以以 任意顺序 返回答案。
示例 1:
- 例如,如果
words = ["ab","cd","ef"], 那么"abcdef","abefcd","cdabef","cdefab","efabcd", 和"efcdab"都是串联子串。"acdbef"不是串联子串,因为他不是任何words排列的连接。输入:s = "barfoothefoobarman", words = ["foo","bar"] 输出:[0,9] 解释:因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。 子串 "barfoo" 开始位置是 0。它是 words 中以 ["bar","foo"] 顺序排列的连接。 子串 "foobar" 开始位置是 9。它是 words 中以 ["foo","bar"] 顺序排列的连接。 输出顺序无关紧要。返回 [9,0] 也是可以的。
代码分析:
本题是 438. 找到字符串中所有字母异位词 的进阶,难度较大。不过438的元素是字母,本题的元素是单词,可以用类似滑动窗口的方法来解决。
记 words 的长度为 m,words 中每个单词的长度为 n,s 的长度为 ls。首先需要将 s 划分为若干单词组,每个单词的大小均为 n (首尾除外)。这样的划分方法有 n 种(即s的长度是否能被n整除,余数范围为0~n-1即为划分方法数),具体操作为先删去前 i (i=0∼n−1)个字母后,将剩下的字母进行划分,如果末尾有不到 n 个字母也删去(剩余字母的删除不影响结论)对这 n 种划分得到的单词数组分别使用滑动窗口对 words 进行类似于「字母异位词」的搜寻。
划分成单词组后,一个窗口包含 s 中前 m 个单词,用一个哈希表 differ 表示窗口中单词频次和 words 中单词频次之差。初始化 differ 时,出现在窗口中的单词,每出现一次,相应的值增加 1,出现在 words 中的单词,每出现一次,相应的值减少 1。然后将窗口右移,右侧会加入一个单词,左侧会移出一个单词,并对 differ 做相应的更新。窗口移动时,若出现 differ 中值不为 0 的键的数量为 0,则表示这个窗口中的单词频次和 words 中单词频次相同,窗口的左端点是一个待求的起始位置。
划分的方法有 n 种,做 n 次滑动窗口后,即可找到所有的起始位置。
具体看代码来理解。要注意理解滑窗中存放的是长单词,进进出出的是短单词,我们判断的依据是不断向后滑动的长单词中短单词的词频之差。
——by 力扣官方题解
本题的各种下标、细节需要仔细理解
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> res;
int m = words.size(), n = words[0].size(), ls = s.size();
n种划分方式把s中每n个字母一组的组合方式都考虑到
注意条件i + m * n <= ls!!!
考虑到所有组合方式的情况下还要保证当前划分方式要在ls范围内至少容下一组由m个
短单词组成的长单词即至少容下一个滑窗
for(int i = 0; i <= n - 1 && i + m * n <= ls; ++i) {
//哈希表中key为string,differ表示存放长单词的窗口中的短单词频次和words中的短单词频次之差
unordered_map<string, int> differ;
将该划分方式下的每个分别由n个字母组成的的短单词加入集合并进行比对
differ表示窗口中的单词频次与words中的单词频次之差
只要差值为0就将其抹去,为正或负都记录下来
for(int j = 0; j < m; ++j) {
++differ[s.substr(i + j * n, n)];
}
for(string &word : words) {
if(--differ[word] == 0) {
differ.erase(word);
}
}
开始滑动窗口
for(int start = i; start < ls - m * n + 1; start += n) {
若start == i,当前长单词中的短单词频次已经在前面两个for循环处统计好了
直接判断differ是否为空即可
if(start != i) {
//右边的单词滑进来
string word = s.substr(start + (m - 1) * n, n);
if(++differ[word] == 0) {
differ.erase(word);
}
//左边的单词滑出去,一进一出保证了滑窗的长度不变
word = s.substr(start - n, n);
if(--differ[word] == 0) {
differ.erase(word);
}
}
//differ为空表明在窗口中的单词均在words中出现且都仅出现一次
if(differ.empty()) {
res.emplace_back(start);
}
}
}
return res;
}
};
作者:力扣官解变量名称以上述方法的代码为准。将 words 中的单词存入哈希表,复杂度为 O(m)(由于字符串长度固定且不超过 30,假定所有哈希操作均为 O(1) 的);需要做 n 次滑动窗口,每次需要遍历一次 s。整体时间复杂度为O(ls×n)。
上述方法是对枚举起点的过程进行了优化,即将起点根据 当前下标与单词长度的取余结果 进行分类,这样我们就不用频繁的建立新的哈希表和进行单词统计。
比较好想的直观的一个方法是由 宫水三叶 提供的:
- 使用哈希表map记录words中每个单词的出现次数
- 枚举s中的每个字符作为起点,往后取得仅仅一个长度为 m*n 的子串 sub
- 使用哈希表 cur 统计 sub 中每个单词的出现次数(每隔n个长度作为一个单词)
- 比较 cur 和 map 是否相同
在步骤 3 中,如果发现
sub中包含了words没有出现的单词,可以直接剪枝。剪枝处使用了带标签的
continue语句直接回到外层循环进行。(C++中使用goto语句)这样你会发现,之前的方法由于经过分类优化,枚举起点次数少多了,并且每个起点都用滑动窗口以步长为n的距离向后不断探索,其间取得的sub可不仅仅为一个。
class Solution {
public List<Integer> findSubstring(String s, String[] words) {
int n = s.length(), m = words.length, w = words[0].length();
Map<String, Integer> map = new HashMap<>();
for (String word : words) map.put(word, map.getOrDefault(word, 0) + 1);
List<Integer> ans = new ArrayList<>();
out:for (int i = 0; i + m * w <= n; i++) {
Map<String, Integer> cur = new HashMap<>();
String sub = s.substring(i, i + m * w);
for (int j = 0; j < sub.length(); j += w) {
String item = sub.substring(j, j + w);
if (!map.containsKey(item)) continue out;
cur.put(item, cur.getOrDefault(item, 0) + 1);
}
//集合之间的equals()需要满足键和值分别相同
if (cur.equals(map)) ans.add(i);
}
return ans;
}
}
作者:宫水三叶若变量名称采用第一种方法的代码中的标准。将 words 中的单词存入哈希表,复杂度为 O(m)(由于字符串长度固定且不超过 30,假定所有哈希操作均为 O(1) 的);然后第一层循环枚举 s 中的每个字符作为起点,复杂度为 O(ls);在循环中将 sub 划分为 m 个单词进行统计,枚举了 m - 1 个下标,复杂度为 O(m);每个单词的长度为 n。整体时间复杂度为 O(ls*m*n)。
剑指 Offer II 041. 滑动窗口的平均值:
问题描述:
给定一个整数数据流和一个窗口大小,根据该滑动窗口的大小,计算滑动窗口里所有数字的平均值。
实现
MovingAverage类:
MovingAverage(int size)用窗口大小size初始化对象。double next(int val)成员函数next每次调用的时候都会往滑动窗口增加一个整数,请计算并返回数据流中最后size个值的移动平均值,即滑动窗口里所有数字的平均值。
示例:
输入: inputs = ["MovingAverage", "next", "next", "next", "next"] inputs = [[3], [1], [10], [3], [5]] 输出: [null, 1.0, 5.5, 4.66667, 6.0]
代码分析:
本题名叫“滑动窗口”,实际上是一道队列模拟题。
这道题要求根据给定的数据流计算滑动窗口中所有数字的平均值,滑动窗口的大小为给定的参数 size。当数据流中的数字个数不超过滑动窗口的大小时,计算数据流中的所有数字的平均值;当数据流中的数字个数超过滑动窗口的大小时,只计算滑动窗口中的数字的平均值,数据流中更早的数字被移出滑动窗口。
由于数字进入滑动窗口和移出滑动窗口的规则符合先进先出,因此可以使用队列存储滑动窗口中的数字,同时维护滑动窗口的大小以及滑动窗口的数字之和。
初始时,队列为空,滑动窗口的大小设为给定的参数 size,滑动窗口的数字之和为 0。
每次调用 next 时,需要将 val 添加到滑动窗口中,同时确保滑动窗口中的数字个数不超过 size,如果数字个数超过 size 则需要将多余的数字移除,在添加和移除数字的同时需要更新滑动窗口的数字之和。由于每次调用只会将一个数字添加到滑动窗口中,因此每次调用最多只需要将一个多余的数字移除。具体操作如下:
- 如果队列中的数字个数等于滑动窗口的大小,则移除队首的数字,将移除的数字从滑动窗口的数字之和中减去。如果队列中的数字个数小于滑动窗口的大小,则不移除队首的数字。
- 将 val 添加到队列中,并加到滑动窗口的数字之和中。
- 计算滑动窗口的数字之和与队列中的数字个数之商,即为滑动窗口中所有数字的平均值。
一套下来行云流水,看代码。
——by 力扣官方题解
class MovingAverage {
public:
MovingAverage(int size) {
this->size = size;
this->sum = 0.0;
}
double next(int val) {
if (qu.size() == size) {
sum -= qu.front();
qu.pop();
}
qu.emplace(val);
sum += val;
return sum / qu.size();
}
private:
int size;
double sum;
queue<int> qu;
};
作者:力扣官解当然,有几个需要留心的地方:
不能用vector容器初始化queue。因为queue转换器要求容器支持front()、back()、push_back()及 pop_front(),说明queue的数据从容器后端入栈而从前端出栈(单端队列)。所以可以使用deque(double-ended queue,双端队列)和list对queue初始化,而vector因其缺少pop_front(),不能用于queue。
- Queue接口与List、Set同一级别,都是继承了Collection接口。LinkedList除了实现了
List接口,也实现了Deque接口,可以当做双端队列来使用。
LeetCode239. 滑动窗口最大值:
问题描述:
给你一个整数数组
nums,有一个大小为k的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的k个数字。滑动窗口每次只向右移动一位。返回 滑动窗口中的最大值 。
示例 1:
输入:nums = [1,3,-1,-3,5,3,6,7], k = 3 输出:[3,3,5,5,6,7] 解释: 滑动窗口的位置 最大值 --------------- ----- [1 3 -1] -3 5 3 6 7 3 1 [3 -1 -3] 5 3 6 7 3 1 3 [-1 -3 5] 3 6 7 5 1 3 -1 [-3 5 3] 6 7 5 1 3 -1 -3 [5 3 6] 7 6 1 3 -1 -3 5 [3 6 7] 7
代码分析:
本题和上一题大体相同,唯一需要考虑在维护滑窗的同时维护最大值。
对于每个滑动窗口,我们可以使用 O(k) 的时间遍历其中的每一个元素,找出其中的最大值。对于长度为 n 的数组 nums 而言,窗口的数量为 n−k+1,因此该算法的时间复杂度为 O((n−k+1)k)=O(nk),会超出时间限制,因此我们需要进行一些优化。
我们可以想到,对于两个相邻(只差了一个位置)的滑动窗口,它们共用着 k−1 个元素,而只有 1 个元素是变化的。我们可以根据这个特点进行优化。
方法一:优先队列
对于「最大值」,我们可以想到一种非常合适的数据结构,那就是优先队列(堆),其中的大根堆可以帮助我们实时维护一系列元素中的最大值。
对于本题而言,初始时,我们将数组 nums 的前 k 个元素放入优先队列中。每当我们向右移动窗口时,我们就可以把一个新的元素放入优先队列中,此时堆顶的元素就是堆中所有元素的最大值。如果我们不做什么处理的话,那么随着滑窗的右移,可能这个最大值未被更新掉但已不在滑窗中(即在数组 nums 中的位置出现在滑动窗口左边界的左侧)。那么也没有保留这个值的必要了,我们可以将它从优先队列中永久移除。
我们不断地移除堆顶的元素,直到其确实出现在滑动窗口中。此时,堆顶元素就是滑动窗口中的最大值。为了方便判断堆顶元素与滑动窗口的位置关系,我们可以在优先队列中存储二元组 (num,index),表示元素 num 在数组中的下标为 index。
class Solution { public: vector<int> maxSlidingWindow(vector<int>& nums, int k) { int n = nums.size(); priority_queue<pair<int, int> > q; for(int i = 0; i <= k - 1; ++i) { q.emplace(nums[i], i); } vector<int> ans = {q.top().first}; for(int i = k; i <= n - 1; ++i) { q.emplace(nums[i], i); //时刻检查堆顶元素位置是否已经不在滑窗中 while(q.top().second <= i - k) { q.pop(); } //更新在滑窗中的最大值 ans.push_back(q.top().first); } return ans; } }; 作者:力扣官解在最坏情况下,数组 nums 中的元素单调递增,那么最终优先队列中包含了所有元素,没有元素被移除。由于将一个元素放入优先队列的时间复杂度为 O(logn),因此总时间复杂度为 O(nlogn)。
方法二:单调队列(具有单调性的双端队列)
我们可以顺着方法一的思路继续进行优化。
由于我们需要求出的是滑动窗口的最大值,试想如下情境:
- 如果当前的滑动窗口中有两个下标 i 和 j,其中 i 在 j 的左侧(i<j),并且 i 对应的元素不大于 j 对应的元素(nums[i]≤nums[j]),那么会发生什么呢?
由于 nums[j] 的存在,nums[i] 一定不会是滑动窗口中的最大值了!也就是说,nums[j]遮挡住了nums[i]。我们可以将 nums[i] 永久地移除。
可以使用一个队列存储所有还没有被移除的下标(有可能作为滑窗最大值的备选)。在队列中,这些下标按照从小到大的顺序被存储,并且它们在数组 nums 中对应的值是严格单调递减的。(如果队列中有两个相邻的下标,它们对应的值相等或者递增,那么令前者为 i,后者为 j,就对应了上面所说的情况,即 nums[i] 会被移除,这就产生了矛盾)
当滑窗右移时,我们需要把一个新的元素放入队列中。为了保持队列的性质,我们会不断地将新的元素与队尾的元素相比较。如果前者大于等于后者,那么队尾的元素就可以被永久地移除,我们将其弹出队列。重复此操作,直到队列为空或者新的元素小于队尾的元素。
由于队列中下标对应的元素是严格单调递减的,因此此时队首下标对应的元素就是滑动窗口中的最大值。但与方法一中相同的是,此时的最大值可能在滑动窗口左边界的左侧,并且随着窗口向右移动,它永远不可能出现在滑动窗口中了。因此我们还需要不断从队首弹出元素,直到队首元素在窗口中为止。
class Solution { public: vector<int> maxSlidingWindow(vector<int>& nums, int k) { int n = nums.size(); deque<int> q; for (int i = 0; i < k; ++i) { //注意严格单减,">=" while (!q.empty() && nums[i] >= nums[q.back()]) { q.pop_back(); } q.push_back(i); } vector<int> ans = {nums[q.front()]}; //初始化写法 for (int i = k; i < n; ++i) { while (!q.empty() && nums[i] >= nums[q.back()]) { q.pop_back(); } q.push_back(i); while (q.front() <= i - k) { q.pop_front(); } ans.push_back(nums[q.front()]); } return ans; } }; 作者:力扣官解每一个下标恰好被放入队列一次,并且最多被弹出队列一次,因此时间复杂度为 O(n)。
我们使用的数据结构是双向的,因此「不断从队首弹出元素」保证了队列中最多不会有超过 k+1 个元素,因此队列使用的空间为 O(k)。
方法三:分块(莫队基础)
我们可以将数组 nums 从左到右按照 k 个一组进行分组,最后一组中元素的数量可能会不足 k 个。如果我们希望求出 nums[i] 到 nums[i+k−1] 的最大值,就会有两种情况:
如果 i 是 k 的倍数,那么 nums[i] 到 nums[i+k−1] 恰好是一个分组。我们只要预处理出每个分组中的最大值,即可得到答案;
- 如果 i 不是 k 的倍数,那么 nums[i] 到 nums[i+k−1] 会跨越两个分组,占有第一个分组的后缀以及第二个分组的前缀。假设 j 是 k 的倍数,并且满足 i<j≤i+k−1,那么 nums[i] 到 nums[j−1] 就是第一个分组的后缀,nums[j] 到 nums[i+k−1] 就是第二个分组的前缀。如果我们能够预处理出每个分组中的前缀最大值以及后缀最大值,同样可以在 O(1) 的时间得到答案。
因此我们用 prefixMax[i] 表示下标 i 对应的分组中,以 i 结尾的前缀最大值;suffixMax[i] 表示下标 i 对应的分组中,以 i 开始的后缀最大值。它们分别满足如下的递推式:
以及
在递推 suffixMax[i] 时需要考虑到边界条件 suffixMax[n−1]=nums[n−1],而在递推 prefixMax[i] 时的边界条件 prefixMax[0]=nums[0] 恰好包含在递推式的第一种情况中,因此无需特殊考虑。
在预处理完成之后,对于 nums[i] 到 nums[i+k−1] 的所有元素,如果 i 不是 k 的倍数,那么窗口中的最大值为 suffixMax[i] 与 prefixMax[i+k−1] 中的较大值;如果 i 是 k 的倍数,那么此时窗口恰好对应一整个分组,suffixMax[i] 和 prefixMax[i+k−1] 都等于分组中的最大值。因此无论窗口属于哪一种情况,取个较大值就一劳永逸。
class Solution { public: vector<int> maxSlidingWindow(vector<int>& nums, int k) { int n = nums.size(); //以i结尾的前缀最大值和以i开始的后缀最大值 vector<int> prefixMax(n), suffixMax(n); for(int i = 0; i <= n - 1; ++i) { //正好包含了0处的边界条件,无需特殊考虑 if(i % k == 0) { prefixMax[i] = nums[i]; } else { prefixMax[i] = max(prefixMax[i - 1], nums[i]); } } for(int i = n - 1; i >= 0; --i) { if(i == n - 1 || (i + 1) % k == 0) { suffixMax[i] = nums[i]; } else { suffixMax[i] = max(suffixMax[i + 1], nums[i]); } } vector<int> ans; for(int i = 0; i <= n - k; ++i) { ans.push_back(max(suffixMax[i], prefixMax[i + k - 1])); } return ans; } }; 作者:力扣官解我们需要 O(n) 的时间预处理出数组 prefixMax,suffixMax 以及计算答案。
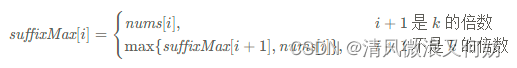
我们再来看 宫水三叶 的思路:
具体的,除了给定的 nums 以外,我们构建一个分块数组 region,其中 region[idx] = x, 含义为块编号为 idx 的最大值为 x,一个块对应一个原始区间 [l,r]。
如何定义块大小是实现分块算法的关键。对于本题,本质是求若干个大小为 k 的区间最大值。我们可以设定块大小为
,这样所需创建的分块数组大小为
。分块数组的更新操作为 O(1),而查询则为
因此使用分块算法总的计算量为 n×
分块算法的几个操作函数:
int getIdx(int x):计算原始下标对应的块编号;void add(int x, int v) :计算原始下标x所属的idx,并将region[idx]和v取max来更新region[idx];int query(int l, int r) :查询 [l,r] 中的最大值,如果 l 和 r 所在块相同,直接遍历 [l,r] 进行取值;若 l 和 r 不同块,则处理 l 和 r 对应的块内元素后,对块编号在 (getIdx(l),getIdx(r))之间的块进行遍历。class Solution { int n, m, len; int[] nums, region; int getIdx(int x) { return x / len; } void add(int x, int v) { region[getIdx(x)] = Math.max(region[getIdx(x)], v); } int query(int l, int r) { int ans = Integer.MIN_VALUE; if (getIdx(l) == getIdx(r)) { for (int i = l; i <= r; i++) ans = Math.max(ans, nums[i]); } else { int i = l, j = r; while (getIdx(i) == getIdx(l)) ans = Math.max(ans, nums[i++]); while (getIdx(j) == getIdx(r)) ans = Math.max(ans, nums[j--]); for (int k = getIdx(i); k <= getIdx(j); k++) ans = Math.max(ans, region[k]); } return ans; } public int[] maxSlidingWindow(int[] _nums, int k) { nums = _nums; n = nums.length; len = (int) Math.sqrt(k); m = n / len + 10; region = new int[m]; Arrays.fill(region, Integer.MIN_VALUE); //把数组中每一个元素划分到对应的分块里面去并更新最大值 for (int i = 0; i < n; i++) add(i, nums[i]); int[] ans = new int[n - k + 1]; for (int i = 0; i < n - k + 1; i++) ans[i] = query(i, i + k - 1); return ans; } } 作者:宫水三叶数组大小为 n,块大小为
LeetCode187.重复的DNA序列:
问题描述:
给定一个表示 DNA序列 的字符串
s,返回所有在 DNA 分子中出现不止一次的 长度为10的序列(子字符串)。你可以按 任意顺序 返回答案。
示例 :
输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT" 输出:["AAAAACCCCC","CCCCCAAAAA"]输入:s = "AAAAAAAAAAAAA" 输出:["AAAAAAAAAA"]
代码分析:
这是一道比较简单的字符串哈希/滑动窗口题,可以采用类似30.题的对起点进行分类的解法。滑窗长度直接定为10就好。当然需要注意,为了防止相同的子串被重复添加到答案,而又不使用常数较大的 Set 结构。我们可以规定:当且仅当该子串在之前出现过一次(加上本次,当前出现次数为两次)时,将子串加入答案。
vector<string> findRepeatedDnaSequences(string s) { int n = s.size(); int len = 10; unordered_map<string, int> map; vector<string> ans; for(int i = 0; i <= len - 1; ++i) { int j = i; while(j + len - 1 <= n - 1) { if(++map[s.substr(j, len)] == 2) ans.push_back(s.substr(j, len)); j += len; } } return ans; }
方法二:字符串哈希+前缀和
以上解法的时间复杂度为O(10*n) ,计算量为 10^6。若题目给定的子串长度大于 100 时,加上生成子串和哈希表本身常数操作,那么计算量将超过 10^7,会 TLE。
因此一个能够做到严格 O(n) 的做法是使用「字符串哈希 + 前缀和」。
具体做法为,我们使用一个与字符串 s 等长的哈希数组 h[],以及次方数组 p[]。
由字符串预处理得到这样的哈希数组和次方数组复杂度为 O(n)。当我们需要计算子串 s[i...j] 的哈希值,只需要利用前缀和思想 h[j]−h[i−1]∗p[j−i+1] 即可在 O(1) 时间内得出哈希值(与子串长度无关)。
- 到这里,还有一个小小的细节需要注意:如果我们期望做到严格 O(n),进行计数的「哈希表」就不能是以 String 作为 key,只能使用 Integer(也就是 hash 结果本身)作为 key。因为 Java 中的 String 的 hashCode 实现是会对字符串进行遍历的,这样哈希计数过程仍与长度有关,而 Integer 的 hashCode 就是该值本身,这是与长度无关的。
class Solution { /* 进阶解法:字符串hash+前缀和计算 根据字符串每个字符的信息计算出一个"特有"的数值,这个数值很大程度上可以辨别不同的字符串于相同的字符串 然后直接用这个数值代替字符串就行,可以通过判断数值是否相同从而简介判断字符串是否相同 这个数值的计算完全可以利用前缀和结合进出窗口的元素来快速计算 这个在字符串窗口(长度)非常大的时会有很高的效率 */ public List<String> findRepeatedDnaSequences(String s) { List<String> res = new ArrayList<>(); if(s == null || s.length <= 10) return res; // N是哈希数组的大小,P是质数底数(不唯一) int N = (int)1e5 + 1, P = 131313; // h为哈希数组,p为对应位置的幂 int[] h = new int[N], p = new int[N]; int len = s.length(); // 求数组h与p:h与p的索引意义均为字符串长度i p[0] = 1; h[0] = 0; // 遍历长度为[1,len] for(int i = 1; i <= len; i++) { h[i] = h[i - 1] * P + s.charAt(i - 1); p[i] = p[i - 1] * P; } // 存储hash值与出现的次数 Map<Integer, Integer> map = new HashMap<>(); // 遍历每个长度为10的子串:以i-1为起始索引,起始索引开始为0 // 例如长度为11,原本是0,1作为起始索引;偏移一位后为i=1,2,其中2=len-10+1 for(int i = 1; i + 10 - 1 <= len; i++) { // 一开始i=1,j=10,说明是索引[0,9]的 int j = i + 10 - 1; // 计算出s[i-1,j-1]的hash值 int hash = h[j] - h[i - 1] * p[10]; // 找出map中是否曾经出现过hash的值 int cnt = map.getOrDefault(hash, 0); // 出现过:将s[i-1,j-1]加入res if(cnt == 1) res.add(s.substring(i - 1, j)); // 更新map map.put(hash, cnt + 1); } return res; } } 作者:宫水三叶字符串哈希的「构造 p 数组」和「计算哈希」的过程,不会溢出吗?
会溢出,溢出就会变为负数,当且仅当两个哈希值溢出程度与 Integer.MAX_VALUE 呈不同的倍数关系时,会产生错误结果(哈希冲突),此时考虑修改 P 或者采用表示范围更大的 long 来代替 int。
LeetCode219. 存在重复元素 II:
问题描述:
给你一个整数数组
nums和一个整数k,判断数组中是否存在两个 不同的索引i和j,满足nums[i] == nums[j]且abs(i - j) <= k。如果存在,返回true;否则,返回false。
代码分析:
借这题来复习一下前面所学的双指针滑窗模板。仅仅注意判断重元最好还是用哈希表,空间换时间是不亏的。
class Solution { public: bool containsNearbyDuplicate(vector<int>& nums, int k) { if(k == 0) return false; int n = nums.size(); int left = 0, right = 0; unordered_map<int, int> map; while(right <= n - 1) { if(++map[nums[right]] >= 2) { return true; } //滑窗收缩 if(right - left >= k) { --map[nums[left]]; ++left; } ++right; } return false; } };
LeetCode220.存在重复元素 III(难):
问题描述:
给你一个整数数组
nums和两个整数k和t。请你判断是否存在 两个不同下标i和j,使得abs(nums[i] - nums[j]) <= t,同时又满足abs(i - j) <= k。如果存在则返回
true,不存在返回false。
代码分析:
本题难点在于
abs(nums[i] - nums[j]) <= t 该如何处理?即使知道了方法和使用的数据结构,对于题目条件的灵活转换也是个难题方法一:滑动窗口+有序集合二分
对于序列中每一个元素 x 左侧的至多 k 个元素,如果这 k 个元素中存在一个元素落在区间 [x - t, x + t] 中,我们就找到了一对符合条件的元素。注意到对于两个相邻的元素,它们各自的左侧的 k 个元素中有 k-1 个是重合的。于是我们可以使用滑动窗口的思路,维护一个大小为 k 的滑动窗口,每次遍历到元素 x 时,滑动窗口中包含元素 x 前面的最多 k 个元素,我们检查窗口中是否存在元素落在区间 [x−t,x+t] 中即可。
如果使用队列维护滑动窗口内的元素,由于元素是无序的,我们只能对于每个元素都遍历一次队列来检查是否有元素符合条件。如果数组的长度为 n,则使用队列的时间复杂度为 O(nk),会超出时间限制。
我们希望能够找到一个数据结构维护滑动窗口内的元素,该数据结构需要满足以下操作:
- 支持添加和删除指定元素的操作,否则我们无法维护滑动窗口;
- 内部元素有序,支持二分查找的操作,这样我们可以快速判断滑动窗口中是否存在元素满足条件,具体而言,对于元素 x,当我们希望判断滑动窗口中是否存在某个数 y 落在区间 [x−t,x+t] 中,只需要判断滑动窗口中所有大于等于 x−t 的元素中的最小元素是否小于等于 x+t 即可。
我们可以使用有序集合来支持这些操作。实现方面,我们在有序集合中查找大于等于 x−t 的最小的元素 y,如果 y 存在,且 y≤x+t,我们就找到了一对符合条件的元素。完成检查后,我们将 x 插入到有序集合中,如果有序集合中元素数量超过了 k,我们将有序集合中最早被插入的元素删除即可。
注意:
- 为防止整型 int 溢出,我们既可以使用长整型 long,也可以对查找区间 [x−t,x+t] 进行限制,使其落在 int 范围内。
- 如果当前有序集合中存在相同元素,那么此时程序将直接返回 true。因此本题中的有序集合无需处理相同元素的情况。
class Solution { public: bool containsNearbyAlmostDuplicate(vector<int>& nums, int k, int t) { int n = nums.size(); set<int> rec; for (int i = 0; i < n; i++) { //返回找到不小于其参数的值第一次出现的位置的迭代器 之所以要把nums[i]与INT_MIN和INT_MAX比较,是为了进行值越界保护 剧透一下,本题有特殊测试案例是超了int范围的,在不换成long的情况下可以仿照如下 auto iter = rec.lower_bound(max(nums[i], INT_MIN + t) - t); if (iter != rec.end() && *iter <= min(nums[i], INT_MAX - t) + t) { return true; } //滑窗移动 rec.insert(nums[i]); if (i >= k) { rec.erase(nums[i - k]); } } return false; } }; 作者:力扣官解n 是给定数组的长度。每个元素至多被插入有序集合和从有序集合中删除一次,每次操作时间复杂度均为 O(log(min(n,k))),整体O(nlog(min(n,k)))。
方法二:桶排序
我们按照元素的大小进行分桶,维护一个滑动窗口内的元素对应的元素。
对于元素值 x,其影响的值区间为 [x−t,x+t]。于是我们可以设定桶的大小为 t+1t + 1t+1。如果两个元素同属一个桶,那么这两个元素必然符合条件。如果两个元素属于相邻桶,那么我们需要校验这两个元素是否差值不超过 t。如果两个元素既不属于同一个桶,也不属于相邻桶,那么这两个元素必然不符合条件。
具体地,我们遍历该序列,假设当前遍历到元素 x,那么我们首先检查 x 所属于的桶是否已经存在元素,如果存在,那么我们就找到了一对符合条件的元素,否则我们继续检查两个相邻的桶内是否存在符合条件的元素。
实现方面,我们将 int 范围内的每一个整数 x 表示为 x=(t+1)×a+b(0≤b≤t) 的形式,这样 x 即归属于编号为 a 的桶。因为一个桶内至多只会有一个元素,所以我们使用哈希表实现即可。
#define LL long long class Solution { public: LL size; bool containsNearbyAlmostDuplicate(vector <int> & nums, int k, int t) { int n = nums.size(); unordered_map<LL, LL> m; size = t + 1L; for (int i = 0; i < n; i++) { LL u = nums[i] * 1L; LL idx = getIdx(u); // 目标桶已存在(桶不为空),说明前面已有 [u - t, u + t] 范围的数字 if (m.find(idx) != m.end()) return true; // 检查相邻的桶 LL l = idx - 1, r = idx + 1; if (m.find(l) != m.end() && abs(u - m[l]) <= t) return true; if (m.find(r) != m.end() && abs(u - m[r]) <= t) return true; // 建立目标桶 m.insert({idx, u}); // 移除下标范围不在 [max(0, i - k), i) 内的桶 if (i >= k) m.erase(getIdx(nums[i - k])); } return false; } LL getIdx(LL u) { return u >= 0 ? u / size : ((u + 1) / size) - 1; } }; 作者:宫水三叶难点是对于getIdx()函数的理解,正负数的处理逻辑不同。详见题解链接 力扣
LeetCode396.旋转函数:
问题描述:
给定一个长度为
n的整数数组nums。假设
arrk是数组nums顺时针旋转k个位置后的数组,我们定义nums的 旋转函数F为:
F(k) = 0 * arrk[0] + 1 * arrk[1] + ... + (n - 1) * arrk[n - 1]返回
F(0), F(1), ..., F(n-1)中的最大值 。生成的测试用例让答案符合 32 位 整数。
示例 1:
输入: nums = [4,3,2,6] 输出: 26 解释: F(0) = (0 * 4) + (1 * 3) + (2 * 2) + (3 * 6) = 0 + 3 + 4 + 18 = 25 F(1) = (0 * 6) + (1 * 4) + (2 * 3) + (3 * 2) = 0 + 4 + 6 + 6 = 16 F(2) = (0 * 2) + (1 * 6) + (2 * 4) + (3 * 3) = 0 + 6 + 8 + 9 = 23 F(3) = (0 * 3) + (1 * 2) + (2 * 6) + (3 * 4) = 0 + 2 + 12 + 12 = 26 所以 F(0), F(1), F(2), F(3) 中的最大值是 F(3) = 26 。
代码分析:
这道题考虑到数据规模,用暴力解会超时,除了找规律、迭代公式就只能另辟蹊径了。
方法一:前缀和+滑动窗口
题目要对「旋转数组」做逻辑,容易想到将 nums 进行复制拼接,得到长度为 2∗n 的新数组,在新数组上任意一个长度为 n 的滑动窗口都对应了一个旋转数组。
然后考虑在窗口的滑动过程中,计算结果会如何变化,假设当前我们处理到下标为 [i,i+n−1] 的滑动窗口,根据题意,当前结果为:
当窗口往后移动一位,也就是窗口的右端点来到 i+n 的位置,左端点来到 i+1 的位置时:
- 需要增加「新右端点」的值,即增加 nums[i+n]∗(n−1),同时减去「旧左端点」的值,即减少 nums[i]∗0(固定为 0),然后更新新旧窗口的公共部分 [i+1,i+n−1]。
不难发现,随着窗口的逐步右移,每一位公共部分的权值系数都会进行减一。
变为
因此,公共部分的差值为
,这引导我们可以使用前缀和进行优化。
至此,我们从旧窗口到新窗口的过渡,都是 O(1),整体复杂度为 O(n)。
- 实现上,我们并不需要真正对 nums 进行复制拼接,而只需要在计算前缀和数组 sum 进行简单的下标处理即可。
class Solution { public int maxRotateFunction(int[] nums) { int n = nums.length; int[] sum = new int[n * 2 + 10]; for (int i = 1; i <= 2 * n; i++) sum[i] = sum[i - 1] + nums[(i - 1) % n]; int ans = 0; for (int i = 1; i <= n; i++) ans += nums[i - 1] * (i - 1); for (int i = n + 1, cur = ans; i < 2 * n; i++) { cur += nums[(i - 1) % n] * (n - 1); cur -= sum[i - 1] - sum[i - n]; if (cur > ans) ans = cur; } return ans; } } 作者:宫水三叶
LeetCode424.替换后的最长重复字符:
问题描述:
给你一个字符串
s和一个整数k。你可以选择字符串中的任一字符,并将其更改为任何其他大写英文字符。该操作最多可执行k次。在执行上述操作后,返回包含相同字母的最长子字符串的长度。
示例 :
输入:s = "AABABBA", k = 1 输出:4 解释: 将中间的一个'A'替换为'B',字符串变为 "AABBBBA"。 子串 "BBBB" 有最长重复字母, 答案为 4。
代码分析:
本题类似于 1004. 最大连续1的个数 III ,此外与此相类似的还有2024.考试的最大困惑、1208. 尽可能使字符串相等(后面会贴出)。但1004.只会在0和1两个状态中改变,本题每个位置的字母都有26种改变选择,明显难度就上来了,启发我们要学会转化题目条件。
你可能也想过,某个位置的字母是否改变、改变成什么应该受到该位置左右两边元素的影响,我们希望通过更新该处使得目前周围字符串长度尽可能大。继续细想(我们仍尝试套用双指针滑窗模板),当前滑窗内的所有修改应该“劲往一处使”,即全都修改成统一的某个字符。那么这个字符如何选取?不管三七二十一统一选取为当前nums[i]可以吗?会对最终结果产生何种影响?不可以,意思是说这种right每次往右走,只要不满足条件,left就一直收敛的算法模板不能套用,我们需要对其进行升级:
- 我们仍需要枚举字符串中的每一个位置作为右端点,然后找到其最远的左端点的位置,满足该区间内除了出现次数最多的那一类字符之外,剩余的字符(即非最长重复字符)数量不超过 k 个。
- 每次右指针右移,如果区间仍然满足条件,那么左指针不移动(区间长度增加呗),否则左指针至多右移一格,保证区间长度不减小(不减小这是这种算法的关键,具体看代码注释)。
class Solution { public int characterReplacement(String s, int k) { int[] num = new int[26]; int n = s.length(); int maxn = 0; //left:左边界,用于滑动时减去头部或者计算长度 //right:右边界,用于加上划窗尾巴或者计算长度 int left = 0, right = 0; while (right < n) { int indexR = s.charAt(right) - 'A'; num[indexR]++; //求窗口中曾出现某字母的最大次数 //计算某字母出现在某窗口中的最大次数,窗口长度只能增大或者不变(注意后面left指针只移动了0-1次) //这样做的意义:我们求的是最长,如果找不到更长的维持长度不变返回结果不受影响 maxn = Math.max(maxn, num[indexR]); //窗口总长度len=right-left+1,以下简称len //其他字母总数=len-字母出现最大次数>替换数目 => len>字母出现最大次数+替换数目 //分析一下,替换数目是不变的=k,字母出现最大次数是可能变化的,因此,只有字母出现最大次数增加的情况,len才能拿到最大值 //又不满足条件的情况下,left和right一起移动,len不变的 if (right - left + 1 - maxn > k) { //这里要减的,因为left越过该点,会对最大值有影响 num[s.charAt(left) - 'A']--; //只要把该点抛出窗口即可,仍保持窗口长度不变的方式就是让right也提前走一步 left++; } //right提前多走一步 right++; } //要消除right提前多走一步的影响,结果为(right-1)-left+1==right-left return right - left; } } 作者:力扣官解要搞清楚滑动窗口的限制条件是什么,本题中窗口的限制就是当前窗口(right-left+1)的非主体元素(right-left+1-maxn)的个数不超过k个(也就这点我们不能容忍),一旦超过那么就要缩小窗口(left+1),但题解中并没有保证丢掉的一定是非主体元素,即在left+1过程中也可能丢掉主体元素,此时窗口仍然不符合条件(这点我们可以容忍)。
在之前的模板中我们左移while直至满足条件后,才继续增长窗口大小,但本题不需要(如果算法写到这,仍要用while,就无法保留之前处理过的当前窗口的最大值,更别提返回该值了)。直接保持窗口大小,右移直至满足条件为止,为什么可以呢?因为我们求的是最大窗口,如果后续符合条件的窗口大于当前窗口,说明当前窗口右移后是子窗口,无需缩小窗口,甚至还要增大,若当前窗口为最大窗口则无需缩小,本质上窗口大小是只增不减的.从循环中还可以看出实际上窗口中主体元素变多时,窗口才会变大。
宫水三叶版解法:
相较于上述解法可能更贴近大家所熟知的双指针滑窗模板,并非像官解维护了窗口最大值。
class Solution { public int characterReplacement(String s, int k) { char[] cs = s.toCharArray(); int[] cnt = new int[26]; int ans = 0; for (int l = 0, r = 0; r < s.length(); r++) { // cnt[cs[r] - 'A']++; int cur = cs[r] - 'A'; cnt[cur]++; // while (!check(cnt, k)) cnt[cs[l++] - 'A']--; while (!check(cnt, k)) { int del = cs[l] - 'A'; cnt[del]--; l++; } //直至符合限制l不再移动时才更新最大值 ans = Math.max(ans, r - l + 1); } return ans; } boolean check(int[] cnt, int k) { int max = 0, sum = 0; for (int i = 0; i < 26; i++) { max = Math.max(max, cnt[i]); sum += cnt[i]; } return sum - max <= k; } } 作者:宫水三叶
LeetCode480.滑动窗口中位数(难):
问题描述:
给你一个数组 nums,有一个长度为 k 的窗口从最左端滑动到最右端。窗口中有 k 个数,每次窗口向右移动 1 位。你的任务是找出每次窗口移动后得到的新窗口中元素有序化后的中位数,并输出由它们组成的数组。
代码分析:
本题是 295. 数据流的中位数 的进阶版。难点在于选取何种数据结构或算法求出排序后窗口中的最中间的一或两个元素。
方法一:双优先队列+延迟删除(设计思想难)
使用两个优先队列(堆)维护所有的元素,第一个优先队列 small 是一个大根堆,它负责维护所有元素中较小的那一半;第二个优先队列 large 是一个小根堆,它负责维护所有元素中较大的那一半。具体地,如果当前需要维护的元素个数为 x,那么 small 中维护了
(向上取整)个元素,large 中维护了
(向下取整)个元素,也就是说:
- small 中的元素个数要么与 large 中的元素个数相同,要么比 large 中的元素个数恰好多 1 个。
这样设计的好处在于:当二者包含的元素个数相同时,它们各自的堆顶元素的平均值即为中位数;而当 small 包含的元素多了一个时,small 的堆顶元素即为中位数。
插入方面,如果当前两个优先队列都为空,那么根据元素个数的要求,我们必须将这个元素加入 small;如果 small 非空(显然不会存在 small 空而 large 非空的情况),我们就可以将 num 与 small 的堆顶元素 top 比较:
如果 num≤top,我们就将其加入 small 中;
如果 num>top,我们就将其加入 large 中。
在成功地加入元素 num 之后,两个优先队列的元素个数可能会变得不符合要求。由于我们只加入了一个元素,那么不符合要求的情况只能是下面的二者之一:
- small 比 large 的元素个数多了 2 个;
- small 比 large 的元素个数少了 1 个。
对于第一种情况,我们将 small 的堆顶元素放入 large;对于第二种情况,我们将 large 的堆顶元素放入 small,这样就可以解决了插入的问题。
然而对于移除而言,设计起来就不是那么容易了,因为我们知道,优先队列不支持移出非堆顶元素这一操作的,因此我们可以考虑使用「延迟删除」的技巧,即:
- 当我们需要移出优先队列中的某个元素时,我们只将这个删除操作「记录」下来,而不去真的删除这个元素。当这个元素出现在 small 或者 large 的堆顶时,我们再去将其移出对应的优先队列。
「延迟删除」使用到的辅助数据结构一般为哈希表 delayed,其中的每个键值对(num,freq),表示元素 num 还需要被删除 freq 次。「优先队列 + 延迟删除」有非常多种设计方式,体现在「延迟删除」的时机选择。在本题解中,我们使用一种比较容易编写代码的设计方式,即:
我们保证在 insert(num),erase(num),getMedian() 任意操作完成之后small 和 large 的堆顶元素都是不需要被「延迟删除」的(或者说任意操作开始之前)。这样设计的好处在于:我们无需更改 getMedian() 的设计,只需要略加修改 insert(num) 即可。
我们首先设计一个辅助函数 prune(heap),它的作用很简单,就是对 heap 这个优先队列(small 或者 large 之一),不断地弹出其需要被删除的堆顶元素,并且减少 delayed 中对应项的值。在 prune(heap) 完成之后,我们就可以保证 heap 的堆顶元素是不需要被「延迟删除」的。
这样我们就可以在 prune(heap) 的基础上设计另一个辅助函数 makeBalance(),它的作用即为调整 small 和 large 中的元素个数,使得二者的元素个数满足要求。由于有了 erase(num) 以及「延迟删除」,我们在将一个优先队列的堆顶元素放入另一个优先队列时,第一个优先队列的堆顶元素可能是需要删除的。因此我们就可以用 makeBalance() 将 prune(heap) 封装起来,它的逻辑如下:
- 如果 small 和 large 中的元素个数满足要求,则不进行任何操作;
- 如果 small 比 large 的元素个数多了 2 个,那么我们我们将 small 的堆顶元素放入 large。此时 small 的对应元素可能是需要删除的,因此我们调用 prune(small);
- 如果 small 比 large 的元素个数少了 1 个,那么我们将 large 的堆顶元素放入 small。此时 large 的对应的元素可能是需要删除的,因此我们调用 prune(large)。
此时,我们只需要在原先 insert(num) 的设计的最后加上一步 makeBalance() 即可。然而对于 erase(num),我们还是需要进行一些思考的:
- 如果 num 与 small 和 large 的堆顶元素都不相同,那么 num 是需要被「延迟删除」的,我们将其在哈希表中的值增加 1;
- 否则,例如 num 与 small 的堆顶元素相同,那么该元素是可以理解被删除的。虽然我们没有实现「立即删除」这个辅助函数,但只要我们将 num 在哈希表中的值增加 1,并且调用「延迟删除」的辅助函数 prune(small),那么就相当于实现了「立即删除」的功能。
此时,所有的接口都已经设计完成了。由于 insert(num) 和 erase(num) 的最后一步都是 makeBalance(),而 makeBalance() 的最后一步是 prune(heap),因此我们就保证了任意操作完成之后,small 和 large 的堆顶元素都是不需要被「延迟删除」的。
class DualHeap { private: // 大根堆,维护较小的一半元素 priority_queue<int> small; // 小根堆,维护较大的一半元素 priority_queue<int, vector<int>, greater<int>> large; // 哈希表,记录「延迟删除」的元素,key 为元素,value 为需要删除的次数 unordered_map<int, int> delayed; int k; // small 和 large 当前包含的元素个数,需要扣除被「延迟删除」的元素 int smallSize, largeSize; public: //构造函数,采用参数表形式 DualHeap(int _k): k(_k), smallSize(0), largeSize(0) {} private: // 不断地弹出 heap 的堆顶元素,并且更新哈希表 prune删除操作和哈希表共同完成erase延迟删除操作 template<typename T> void prune(T& heap) { 该删除确保堆顶再无待延迟删除元素 while (!heap.empty()) { int num = heap.top(); if (delayed.count(num)) { --delayed[num]; if (!delayed[num]) { delayed.erase(num); } heap.pop(); } else { break; } } } // 调整 small 和 large 中的元素个数,使得二者的元素个数满足要求 平衡操作里包含prune删除操作 void makeBalance() { if (smallSize > largeSize + 1) { // small 比 large 元素多 2 个 large.push(small.top()); small.pop(); --smallSize; ++largeSize; // small 堆顶元素被移除,为了保证移除后的堆顶元素为非延迟删除元素,需要进行 prune prune(small); } else if (smallSize < largeSize) { // large 比 small 元素多 1 个 small.push(large.top()); large.pop(); ++smallSize; --largeSize; // large 堆顶元素被移除,需要进行 prune prune(large); } } public: void insert(int num) { if (small.empty() || num <= small.top()) { small.push(num); ++smallSize; } else { large.push(num); ++largeSize; } makeBalance(); } void erase(int num) { ++delayed[num]; if (num <= small.top()) { 可以看到,虽然删除存在延时,但smallSize和largeSize是即时更新的 --smallSize; if (num == small.top()) { 如果碰巧是堆顶,立即删除不犹豫 prune(small); } } else { --largeSize; if (num == large.top()) { prune(large); } } 插入和删除都要记得最后检查平衡 makeBalance(); } double getMedian() { return k & 1 ? small.top() : ((double)small.top() + large.top()) / 2; } }; class Solution { public: vector<double> medianSlidingWindow(vector<int>& nums, int k) { DualHeap dh(k); for (int i = 0; i < k; ++i) { dh.insert(nums[i]); } vector<double> ans = {dh.getMedian()}; for (int i = k; i < nums.size(); ++i) { dh.insert(nums[i]); dh.erase(nums[i - k]); ans.push_back(dh.getMedian()); } return ans; } }; 作者:力扣官解由于「延迟删除」的存在,small 比 large 在最坏情况下可能包含所有的 n 个元素,即没有一个元素被真正删除了。因此优先队列的大小是 O(n) 而不是 O(k) 的,其中 n 是数组 nums 的长度。
insert(num) 和 erase(num) 的单次时间复杂度为 O(logn),getMedian() 的单次时间复杂度为 O(1)。因此总时间复杂度为 O(nlogn)。
Java版:
区别于C++,Java中的remove()不仅可以删除头节点而且还可以用 remove(Object o) 来删除堆中的与给定对象相同的最先出现的对象,所以用JAVA解本题就不用考虑延迟删除了。但是其方法时间复杂度为O(n)而非O(logn),数据量准备的比较好的话可能通过不了,需要手写堆实现,增加log级的删除方法。
class Solution { public double[] medianSlidingWindow(int[] nums, int k) { int n = nums.length; int cnt = n - k + 1; double[] ans = new double[cnt]; // 如果是奇数滑动窗口,让 right 的数量比 left 多一个 //此处写法为lamda表达式 PriorityQueue<Integer> left = new PriorityQueue<>((a,b)->Integer.compare(b,a)); // 滑动窗口的左半部分 PriorityQueue<Integer> right = new PriorityQueue<>((a,b)->Integer.compare(a,b)); // 滑动窗口的右半部分 for (int i = 0; i < k; i++) right.add(nums[i]); for (int i = 0; i < k / 2; i++) left.add(right.poll()); ans[0] = getMid(left, right); for (int i = k; i < n; i++) { // 人为确保了 right 会比 left 多,因此,删除和添加都与 right 比较(left 可能为空) int add = nums[i], del = nums[i - k]; if (add >= right.peek()) { right.add(add); } else { left.add(add); } if (del >= right.peek()) { right.remove(del); } else { left.remove(del); } adjust(left, right); ans[i - k + 1] = getMid(left, right); } return ans; } void adjust(PriorityQueue<Integer> left, PriorityQueue<Integer> right) { while (left.size() > right.size()) right.add(left.poll()); while (right.size() - left.size() > 1) left.add(right.poll()); } double getMid(PriorityQueue<Integer> left, PriorityQueue<Integer> right) { if (left.size() == right.size()) { return (left.peek() / 2.0) + (right.peek() / 2.0); } else { return right.peek() * 1.0; } } } 作者:宫水三叶注意:
- 在 Java 中 Integer.compare 的实现是 (x < y) ? -1 : ((x == y) ? 0 : 1)。只是单纯的比较,不涉及运算,所以不存在溢出风险。优于 (x, y) -> y-x 。当
y = Integer.MAX_VALUE,x = Integer.MIN_VALUE时,到导致溢出,返回的是负数 ,而不是逻辑期望的正数。- 计算中位数时使用的是
(a / 2.0) + (b / 2.0)的形式,而不是采用(a + b) / 2.0的形式。后者有相加溢出的风险。平衡二叉树:
insert 和 erase 都是平衡二叉树的标准操作,getMedian 只要首先得到平衡树的 size,再根据奇偶性得到第 size/2 或者 (size+1)/2 的数即可。
/*手写平衡二叉树*/ class IndexedAVL{ private static class Node{ // 节点存储的真实的数据 int val; // size 是这节点统辖的树的所有元素的总个数,cnt这个节点存储val出现的次数, height是节点的高度 int size,cnt,height; Node left,right; public Node(int val) { this.val = val; this.cnt = this.height = this.size = 1; } } private int size; public int getSize() { return size; } private Node root; private int h(Node node){ return node==null?0:node.height; } private int getSize(Node p){ return p==null?0:p.size; } private void pushUp(Node p){ p.height = Math.max(h(p.left),h(p.right))+1; p.size = p.cnt + getSize(p.left) + getSize(p.right); } // 右旋 private Node zig(Node p){ Node q = p.left; p.left = q.right; q.right = p; pushUp(p); pushUp(q); return q; } // 左旋 private Node zag(Node q){ Node p = q.right; q.right = p.left; p.left = q; pushUp(q); pushUp(p); return p; } private Node LL(Node t){ return zig(t); } private Node LR(Node t){ t.left = zag(t.left); return zig(t); } private Node RR(Node t){ return zag(t); } private Node RL(Node t){ t.right = zig(t.right); return zag(t); } private Node insert(Node t,int value) { if(t == null){ return new Node(value); } Node newRoot = t; // 插入完成之后,要将搜索路径上的点依次进行调整 height,调整 size的大小 if(value < t.val){ t.left = insert(t.left,value); int leftH = h(t.left); int rightH = h(t.right); if(leftH - rightH > 1){ // LL型 if(value <= t.left.val){ newRoot = LL(t); // LR型 }else{ newRoot = LR(t); } } }else if(value > t.val){ t.right = insert(t.right,value); int leftH = h(t.left); int rightH = h(t.right); if(rightH -leftH >1){ // RR型 if(value >= t.right.val){ newRoot = RR(t); // RL型 }else{ newRoot = RL(t); } } }else { t.cnt++; } pushUp(newRoot); return newRoot; } private Node remove(Node t,int value) { if(t == null) return null; Node newRoot = t; if(value < t.val){ t.left = remove(t.left,value); // 删除左子树的节点,唯一可能导致"失衡" 的情况是 bf由 -1 变成-2 int leftH = h(t.left); int rightH = h(t.right); if(rightH - leftH > 1){ if( h(t.right.right) >= h(t.right.left) ){ newRoot = RR(t); }else{ newRoot = RL(t); } } } else if(value > t.val){ t.right = remove(t.right,value); int leftH = h(t.left); int rightH = h(t.right); // 删除右子树的节点,唯一可能导致"失衡" 的情况是 bf由 1 变成 2 if(leftH - rightH > 1){ if(h(t.left.left) >= h(t.left.right)){ newRoot = LL(t); }else{ newRoot = LR(t); } } }else{ if(t.cnt>1){ t.cnt--; }else{ // 下面细分成 3种情况 (左右子树都为空,一棵为空另一棵不为空,都不为空) if(t.left == null && t.right == null){ return null; }else if(t.left != null && t.right == null){ return t.left; }else if(t.left == null){ return t.right; }else{ // 用前驱的值代替(后继也是一样) Node cur = t.left; while(cur.right != null){ cur = cur.right; } t.val = cur.val; t.left = remove(t.left,cur.val); // 这个地方仍然要有形态的调整 // 删除左子树的节点,唯一可能导致"失衡" 的情况是 bf由 -1 变成-2 int leftH = h(t.left); int rightH = h(t.right); if(rightH - leftH > 1){ if( h(t.right.right) >= h(t.right.left) ){ newRoot = RR(t); }else{ newRoot = RL(t); } } } } } pushUp(newRoot); return newRoot; } private int getItemByRank(Node node,int rank){ if(node == null) return Integer.MIN_VALUE; if(getSize(node.left) >= rank) return getItemByRank(node.left,rank); if(getSize(node.left)+node.cnt >= rank) return node.val; return getItemByRank(node.right,rank-getSize(node.left)-node.cnt); } public int getItemByRank(int rank){ return getItemByRank(root,rank); } public void add(int value){ root = insert(root,value); this.size++; } public void erase(int value){ root = remove(root,value); this.size--; } } class Solution { public double[] medianSlidingWindow(int[] nums, int k) { List<Double> list = new ArrayList<>(); IndexedAVL avl = new IndexedAVL(); // 初始化 int n = nums.length; for(int i=0;i<k-1;i++){ avl.add(nums[i]); } int l = 0 ,r = k-1; while(r<n){ avl.add(nums[r++]); if(k%2!=0){ list.add(avl.getItemByRank(k/2+1)*1.0); }else{ list.add(((double)avl.getItemByRank(k/2)+avl.getItemByRank(k/2+1))/2.0); } avl.erase(nums[l++]); } double[] ans = new double[list.size()]; for(int i=0;i<list.size();i++){ ans[i] = list.get(i); } return ans; } }C++中multiset底层就是红黑树,非常方便;当然手写splay、FHQ treap、AVL什么的也行。
LeetCode295.数据流的中位数:
问题描述:
实现 MedianFinder 类:
MedianFinder()初始化MedianFinder对象。
void addNum(int num)将数据流中的整数num添加到数据结构中。
double findMedian()返回到目前为止所有元素的中位数。与实际答案相差10-5以内的答案将被接受。基本条件同上题,区别在于上题求的是固定长度滑窗内的中位数,本题要求左固定而右不断扩大的数据结构中的中位数。
代码分析:
经过上一题的洗礼,本题我们可以仿照写出。并且我们没有写erase()和prune()的必要了,makeBalance()都得到了极大的简化。
class MedianFinder { public: priority_queue<int, vector<int> > queMin; priority_queue<int, vector<int>, greater<int> > queMax; MedianFinder() {} void addNum(int num) { if (queMin.empty() || num <= queMin.top()) { queMin.push(num); if (queMax.size() + 1 < queMin.size()) { queMax.push(queMin.top()); queMin.pop(); } } else { queMax.push(num); if (queMax.size() > queMin.size()) { queMin.push(queMax.top()); queMax.pop(); } } } double findMedian() { if (queMin.size() > queMax.size()) { return queMin.top(); } return (queMin.top() / 2.0 + queMax.top() / 2.0) ; } };方法二:有序集合+双指针
我们也可以使用有序集合维护这些数。我们把有序集合看作自动排序的数组,使用双指针指向有序集合中的中位数元素即可。当累计添加的数的数量为奇数时,双指针指向同一个元素。当累计添加的数的数量为偶数时,双指针分别指向构成中位数的两个数。
当我们尝试添加一个数 num 到数据结构中,我们需要分情况讨论:
- 初始有序集合为空时,我们直接让左右指针指向 num 所在的位置。
- 有序集合中元素为奇数时,left 和 right 同时指向中位数。如果 num 大于等于中位数,那么只要让 right 右移,否则让 left 左移即可。
- 有序集合中元素为偶数时,left 和 right 分别指向构成中位数的两个数。
针对第三点:
- 当 num 成为新的唯一的中位数,那么我们让 left 右移,right 左移,这样它们即可指向 num 所在的位置;
- 当 num 大于等于 right,那么我们让 left 右移即可;
- 当 num 小于 right 指向的值,那么我们让 right 左移,注意到如果 num 恰等于 left 指向的值,那么 num 将被插入到 left 右侧,使得 left 和 right 间距增大,所以我们还需要额外让 left 指向移动后的 right。
class MedianFinder { //基于红黑树,允许键值重复的有序集合 multiset<int> nums; multiset<int>::iterator left, right; public: MedianFinder() : left(nums.end()), right(nums.end()) {} void addNum(int num) { const size_t n = nums.size(); nums.insert(num); //若初始集合为空,直接指向num所在位置 if (!n) { left = right = nums.begin(); } else if (n & 1) { if (num < *left) { left--; } else { right++; } } else { if (num > *left && num < *right) { left++; right--; } else if (num >= *right) { left++; } else { right--; left = right; } } } double findMedian() { return (*left + *right) / 2.0; } }; 作者:力扣官解
LeetCode2024.考试的最大困扰度:
问题描述:
(2022.8.30 字节跳动)简单讲就是给你一个长度为n个字符的字符串,每个字符只有“T”或“F”两种状态。现在要求不超过k次地改变字符的状态,返回最大的连续“T”或“F”的数目。
代码分析:
本题十分类似 1004. 最大连续1的个数 III 。只不过对于1004.每个位置仅有一个状态是有效的,而本题两个状态都是有效的。因此我们考虑分别统计“T”串和“F”串。
class Solution { public: int maxConsecutiveChar(string& answerKey, int k, char ch) { int n = answerKey.size(); int ans = 0; for (int left = 0, right = 0, sum = 0; right < n; right++) { sum += answerKey[right] != ch; while (sum > k) { sum -= answerKey[left++] != ch; } ans = max(ans, right - left + 1); } return ans; } int maxConsecutiveAnswers(string answerKey, int k) { return max(maxConsecutiveChar(answerKey, k, 'T'), maxConsecutiveChar(answerKey, k, 'F')); } }; 作者:力扣官解
LeetCode1208.尽可能使字符串相等:
问题描述:
给你两个长度相同的字符串,
s和t。将
s中的第i个字符变到t中的第i个字符需要|s[i] - t[i]|的开销(开销可能为 0),也就是两个字符的 ASCII 码值的差的绝对值。用于变更字符串的最大预算是
maxCost。在转化字符串时,总开销应当小于等于该预算,这也意味着字符串的转化可能是不完全的。如果你可以将
s的子字符串转化为它在t中对应的子字符串,则返回可以转化的最大长度。如果
s中没有子字符串可以转化成t中对应的子字符串,则返回0。
代码分析:
除了像上题的标准双指针滑窗做法,我们还可以借鉴 424. 替换后的最长重复字符 使得滑窗长度不变或只增大的做法。
class Solution { public int equalSubstring(String s, String t, int maxCost) { int n = s.length(); int[] diff = new int[n]; for (int i = 0; i < n; i++) { diff[i] = Math.abs(s.charAt(i) - t.charAt(i)); } int maxLength = 0; int start = 0, end = 0; int sum = 0; while (end < n) { sum += diff[end]; while (sum > maxCost) { sum -= diff[start]; start++; } maxLength = Math.max(maxLength, end - start + 1); end++; } return maxLength; } };这样写也可以:
class Solution { public int equalSubstring(String s, String t, int maxCost) { int n = s.length(); int[] diff = new int[n]; for (int i = 0; i < n; i++) { diff[i] = Math.abs(s.charAt(i) - t.charAt(i)); } int maxLength = 0; int start = 0, end = 0; int sum = 0; while (end < n) { sum += diff[end]; if (sum > maxCost) { sum -= diff[start]; start++; } end++; } return end - start; } }方法二:前缀和+二分搜索
首先计算数组 diff 的前缀和,创建长度为 n+1 的数组 accDiff,其中 accDiff[0]=0,对于 0≤i<n,有 accDiff[i+1]=accDiff[i]+diff[i]。
即当 1≤i≤n 时,accDiff[i] 为 diff 从下标 0 到下标 i−1 的元素和:
当 diff 的子数组以下标 j 结尾时,需要找到最小的下标 k(k≤j),使得 diff 从下标 k 到 j 的元素和不超过 maxCost,此时子数组的长度是 j−k+1。由于已经计算出前缀和数组 accDiff,因此可以通过 accDiff 得到 diff 从下标 k 到 j 的元素和:
因此,找到最小的下标 k(k≤j),使得 diff 从下标 k 到 j 的元素和不超过 maxCost,等价于找到最小的下标 k(k≤j),使得 accDiff[j+1]−accDiff[k]≤maxCost。
由于 diff 的的每个元素都是非负的,因此 accDiff 是递增的,对于每个下标 j,可以通过在 accDiff 内进行二分查找的方法找到符合要求的最小的下标 k。
对于下标范围 [1,n] 内的每个 i,通过二分查找的方式,在下标范围 [0,i] 内找到最小的下标 start,使得 accDiff[start] ≥ accDiff[i]−maxCost,此时对应的 diff 的子数组的下标范围是从 start 到 i−1,子数组的长度是 i−start。
遍历下标范围 [1,n] 内的每个 i 之后,即可得到符合要求的最长子数组的长度,即字符串可以转化的最大长度。
class Solution { public int equalSubstring(String s, String t, int maxCost) { int n = s.length(); int[] accDiff = new int[n + 1]; for (int i = 0; i < n; i++) { accDiff[i + 1] = accDiff[i] + Math.abs(s.charAt(i) - t.charAt(i)); } int maxLength = 0; for (int i = 1; i <= n; i++) { int start = binarySearch(accDiff, i, accDiff[i] - maxCost); maxLength = Math.max(maxLength, i - start); } return maxLength; } public int binarySearch(int[] accDiff, int endIndex, int target) { int low = 0, high = endIndex; while (low < high) { //防止(high+low)/2溢出 int mid = (high - low) / 2 + low; if (accDiff[mid] < target) { low = mid + 1; } else { high = mid; } } return low; } } 作者:力扣官解计算前缀和数组 accDiff 的时间复杂度是 O(n)。 需要进行 n 次二分查找,每次二分查找的时间复杂度是 O(logn),二分查找共需要 O(nlogn) 的时间。 因此总时间复杂度是 O(nlogn)。
持续更新......(40000字)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)