
【深度学习】李宏毅2021/2022春深度学习课程笔记 - Classification(Short Version)
本节用较短的篇幅介绍一下深度学习解决如何分类问题。如果想看长的版本,可以参考下面的视频。
文章目录
一、前言
本节用较短的篇幅介绍一下深度学习解决如何分类问题。如果想看长的版本,可以参考下面的视频。

二、Classification as Regression
把分类当作回归来看
如下图所示,我们可以把每个类别对应到一个数字,然后进行回归,目标就是预测值和真实类别对应的数字越接近越好。如下图所示,Class1对应数字1,Class2对应数字2,Class3对应数字3。
但是把类别对应到数字有个缺点,就是:默认类别之间是有大小关系的,即Class1和Class2的相似程度大于Class1和Class3的相似程度,这在大部分情况下是不合理的。(当然也有合理的时候,比如根据身高体重预测某人的年龄,那么相邻年龄的身高体重当然是比较相似的)

三、Class as One-Hot Vector
最常用的做法是,将每个类别映射为独热编码(One-Hot Vector)

此时,神经网络就需要输出三个数值
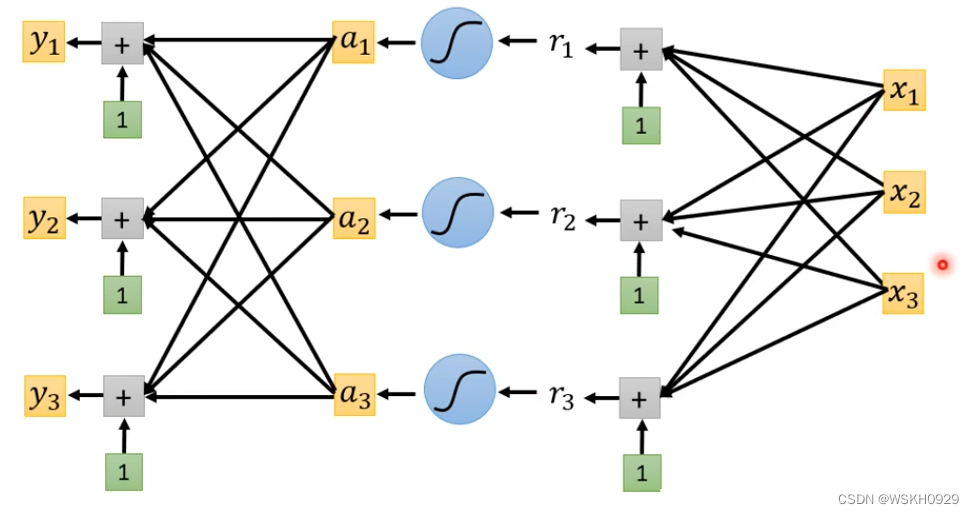
一般地,在分类问题中,我们会将神经网络最后输出的 n维 向量进行 SoftMax 归一化处理后,再计算损失

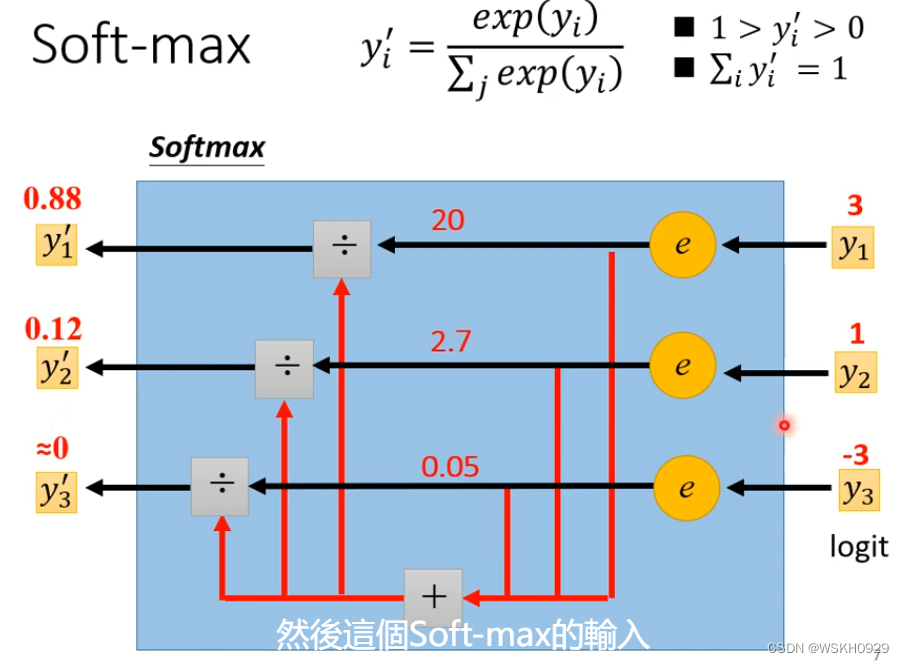
四、Soft-Max 归一化
下图给出了 SoftMax 归一化的基本原理和公式
五、Loss of Classification
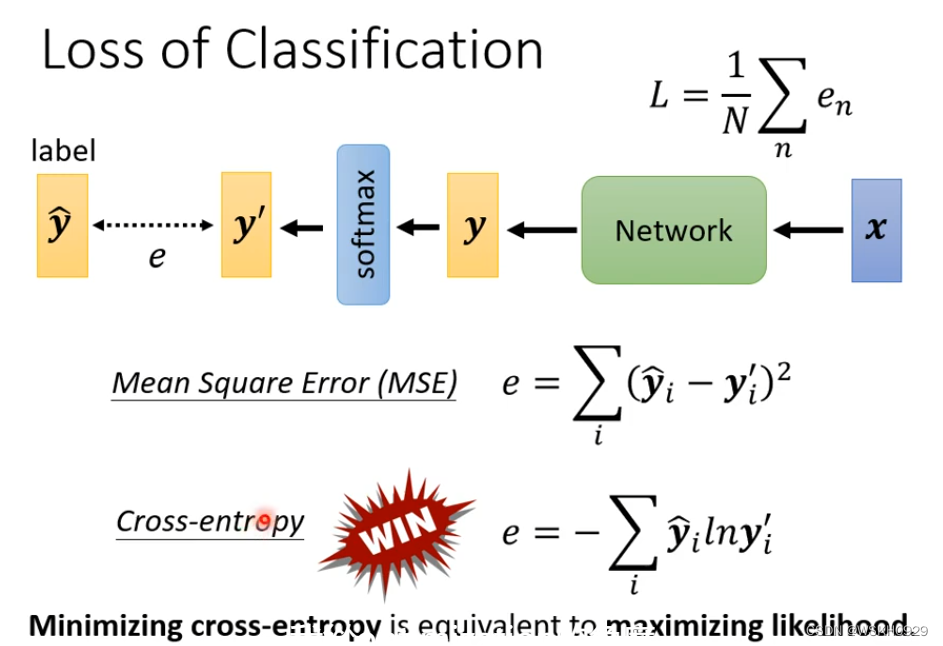
由于在分类问题中,输出往往是 n 维向量,所以不能用 回归中常用的 MSE和MAE损失函数进行损失的计算。在分类问题中,常用的损失函数是交叉熵损失(Cross-Entropy),交叉熵损失用来评价预测分布和真实分布的相似程度
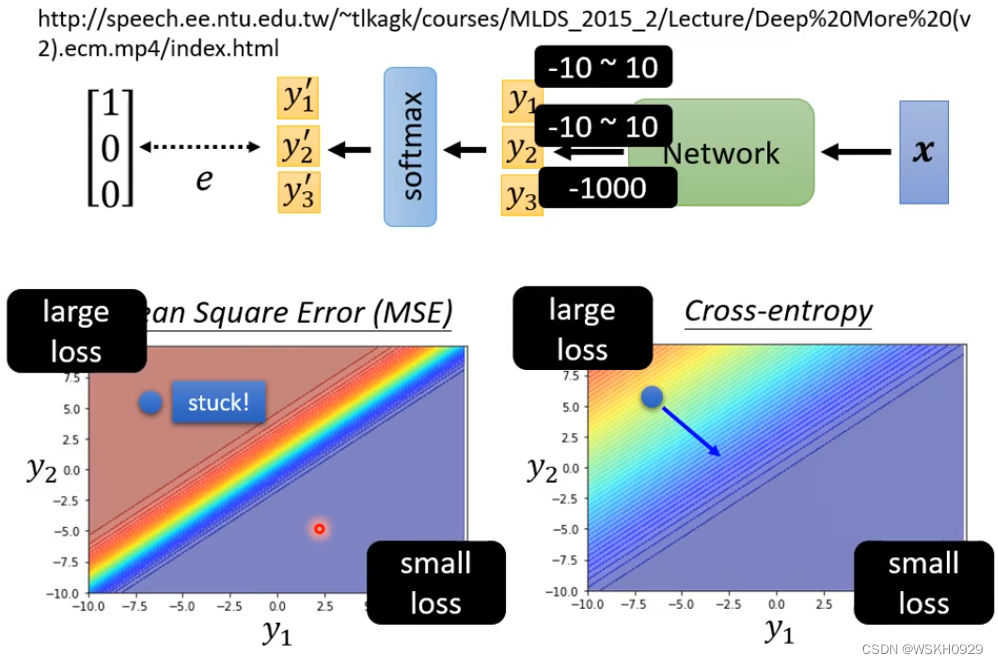
下图展示了使用MSE和Cross-Entropy时候的Loss图像。可以注意到,两个损失函数都是左上角误差大,右下角误差小。但是使用MSE时,左上角有一大片区域的Loss非常相近,即具有较大的平坦区域,在平坦区域中梯度很小,也就是说,如果初始值设定在了平坦区域中,模型很可能Train不起来。但是交叉熵损失的图像中就没有看到有较大的平坦区域,可以更好的Train。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)