模式识别概念
模式识别概念、目的、方法、基本构成、性能测试
目录
一、什么是模式?什么是模式识别
模式的直观特性
- 可观察性
- 可区分性
- 相似性
什么是模式
模式是指存在时间和空间中可以观察到的物体,如果我们可以区别他们是否相同或者相似,都可以称之为模式。模式所指的不是事物本身,而是从事物获得的信息,因此,模式往往表现为具有时间和空间分布的信息。
什么是模式识别
“模式识别”则是在某些一定量度或观测基础上把待识模式划分到各自的模式类中去。
对人类来说,特别重要的是对光学信息(通过视觉器官来获得)和声学信息(通过听觉器官来获得) 的识别。这是模式识别的两个重要方面。市场上可见到的代表性产品有光学字符识别、语音识别系统。
模式识别可以用
Y=F(X)
来简要描述, X是定义域,取自特征集。Y是值域,来自类别的标号集。F是模式识别的判别方法
二、模式识别的目的
利用计算机对物理对象进行分类,在错误概率最小的条件下,使识别的结果尽量与客观物体相符合。
模式识别可以在各个领域应用,例如生物学领域的自动细胞学、染色体特性研究、遗传研究。天文学领域的天文望远镜图像分析、自动光谱学。 经济学的股票交易预测、企业行为分析。医学的心电图分析、脑电图分析、医学图像分析。工程上的产品缺陷检测、特征识别、语音识别、自动导航系统、污染分析。军事上的航空摄像分析、雷达和声纳信号检测和分类、自动目标识别。安全上的指纹识别、人脸识别、监视和报警系统。
三、模式识别方法
1.两个概念
特征空间:从模式得到的对分类有用的度量、属性或基元构成的空间。
解释空间:将c个类别表示为其中
为所属类别的集合,称为解释空间。
2.模式识别目标
模式识别系统的目标是在特征空间和解释空间之间找到一种映射关系,这种也映射也称之为假说。

3.假说获得的两种方法
3.1监督学习
在特征空间中找到一个与解释空间的结构相对应的假说。在给定模式下假定一个解决方案,任何在训练集中接近目标的假说也都必须在“未知”的样本上得到近似的结果。
• 依靠已知所属类别的的训练样本集,按它们特征向量的分布来确定假说 (通常为一个判别函数),在判别函数确定之后能用它对未知的模式进行分类;
• 对分类的模式要有足够的先验知识,通常需要采集足够数量的具有典型性的样本进行训练。 (监督学习和非监督学习的最明显区别)
监督学习是指:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。
监督学习是从标记的训练数据来推断一个功能的机器学习任务。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。一个最佳的方案将允许该算法来正确地决定那些看不见的实例的类标签。这就要求学习算法是在一种“合理”的方式从一种从训练数据到看不见的情况下形成。
3.2非监督学习
在解释空间中找到一个与特征空间的结构相对应的假说。这种方法试图找到一种只以特征空间中的相似关系为基础的有效假说。
• 在没有先验知识的情况下,通常采用聚类分析方法,基于 “物以类聚”的观点,用数学方法分析各特征向量之间的距离及分散情况;
• 如果特征向量集聚集若干个群,可按群间距离远近把它们划分成类;
• 这种按各类之间的亲疏程度的划分,若事先能知道应划分成 几类,则可获得更好的分类结果。
• 非监督学习是指在没有类别信息情况下,通过对所研究对象的大量样本的数据分析实现对样本分类的一种数据处理方法
由于在很多实际应用中,缺少所研究对象类别形成过程的知识,或者为了判断各个样本(模式)所属的类别需要很大的工作量(例如卫星遥感照片上各像元所对应的地面情况),因此往往只能用无类别标答的样本集进形学习。通过无监督式学习,把样本集划分为若干个子集(类别),从而直接解决看样本的分类问题,或者把它作为训练样本集,再用监督学习方法进行分类器设计。
四、模式识别的主要方法
- 数据聚类
- 统计分类
- 结构模式识别
- 神经网络
4.1数据聚类
目标:用某种相似性度量的方法将原始数据组织成有意义的和有用的各种数据集。 是一种非监督学习的方法,解决方案是数据驱动的。

4.2统计分类
统计模式识别是对模式的统计分类方法,即结合统计概率论的贝叶斯决策系统进行模式识别的技术,又称为决策理论识别方法。它是基于概率统计模型得到各类别的特征向量的分布,以取得分类的方法。 特征向量分布的获得是基于一个类别已知的训练样本集。 是一种监督的学习方法,分类器是概念驱动的。
统计模式识别方法就是用给定的有限数量样本集,在已知研究对象统计模型或已知判别函数类条件下根据一定的准则通过学习算法把d维特征空间划分为c个区域,每一个区域与每一类别相对应。模式识别系统在进行工作时只要判断被识别的对象落入哪一个区域,就能确定出它所属的类别。由噪声和传感器所引起的变异性,可通过预处理而部分消除;而模式本身固有的变异性则可通过特征提取和特征选择得到控制,尽可能地使模式在该特征空间中的分布满足上述理想条件。因此一个统计模式识别系统应包含预处理、特征提取、分类器等部分。
4.3结构模式识别
该方法通过考虑识别对象的各部分之间的联系来达到识别分类的目的。 识别采用结构匹配的形式,通过计算一个匹配程度值 (matching score)来评估一个未知的对象或未知对象某些部分与某种典型模式的关系如何。 当成功地制定出了一组可以描述对象部分之间关系的规则后, 可以应用一种特殊的结构模式识别方法 – 句法模式识别,来检查一个模式基元的序列是否遵守某种规则,即句法规则或语法。
4.4神经网络
神经网络是受人脑组织的生理学启发而创立的。 由一系列互相联系的、相同的单元(神经元)组成。相互 间的联系可以在不同的神经元之间传递增强或抑制信号。 增强或抑制是通过调整神经元相互间联系的权重系数来 (weight)实现。 神经网络可以实现监督和非监督学习条件下的分类。
关于这部分小编之前介绍过(神经网络模型之BP算法及实例分析),大家可以翻一下前面。
五、模式识别系统的基本构成
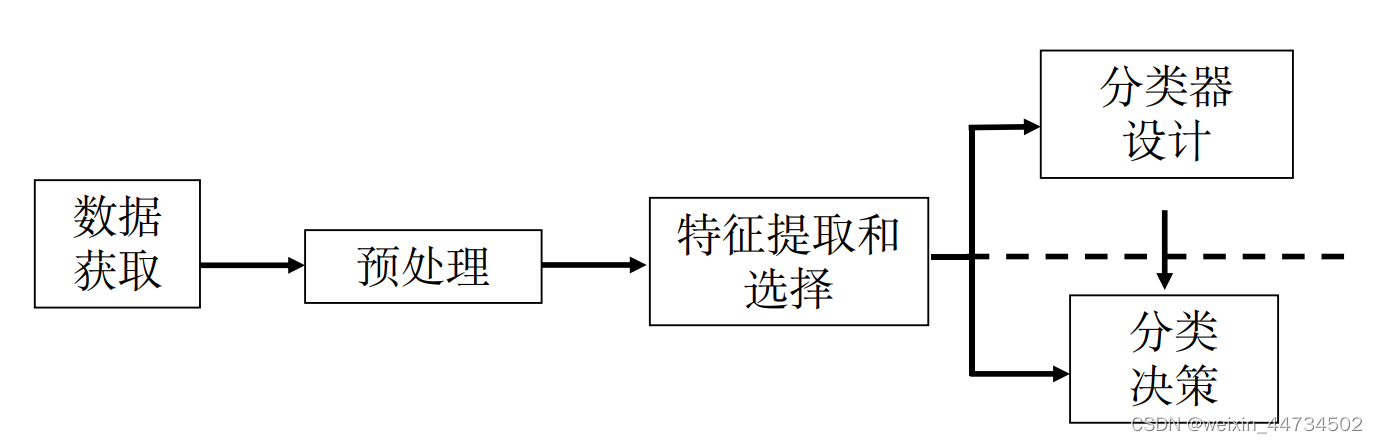
模式识别系统的基本构成
数据获取:用计算机可以运算的符号来表示所研究的对象,二维图像: 文字、指纹、地图、照片等。一维波形: 脑电图、心电图、季节震动波形等。
预处理单元: 去噪声,提取有用信息,并对输入测量仪器或其它因素所造成的退化现象进行复原。
特征提取和选择:对原始数据进行变换,得到最能反映分类本质的特征。
测量空间:原始数据组成的空间。
特征空间:分类识别赖以进行的空间
模式表示:维数较高的测量空间->维数较低的特征空间
分类决策:在特征空间中用模式识别方法把被识别对象归为某一类别。
基本做法:在样本训练集基础上确定某个判决规则,使得按这种规则对被识别对象进行分类所造成的错误识别率最小或引起的损失最小。
六、性能测试
系统评价原则:为了更好地对模式识别系统性能进行评价,必须使用一组独立于训练集的测试集对系统进行测试
其中,训练集:是一个已知样本集,在监督学习方法中,用它来开发出模式分类器。测试集:在设计识别和分类系统时没有用过的独立样本集。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)