
【机器学习】支持向量机SVM | python实现 | 分类问题
SVM实现分类问题
·
一、SVM基础概念
1.1.SVM常用几种模型
1.SVC,(分类问题)
2.SVR,(回归问题)
3.LinearSVC
4.LinearSVR
5…其他等等
二、具体案例——鸢(yuan)尾花分类(分类问题)
2.1.实现代码(datasets直接导入)
代码如下(示例):
from sklearn import datasets #导入数据集模块
from sklearn.model_selection import train_test_split #数据集划分
from sklearn import svm #导入SVM支持向量机
from sklearn.metrics import classification_report #用于显示主要分类指标的文本报告
import sklearn.metrics as sm #生成混淆矩阵的库
import seaborn as sn #混淆矩阵可视化的库
import matplotlib.pyplot as plt #画图
#--------------------------------1.加载数据集---------------------------------#
iris = datasets.load_iris()#加载鸢尾花数据集
print(iris)
X = iris.data #输入特征
Y = iris.target #标签(输出特征)
print(X)
print('----------------')
print(Y)
print('----------------')
print('鸢尾花输入特征的维度是{}'.format(X.shape))
print('鸢尾花标签的维度是{}'.format(Y.shape))
#--------------------------------2.划分数据集---------------------------------#
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=45) # 数据划分
#--------------------------------3.模型训练---------------------------------#
clas = svm.SVC()#选择分类器
clas.fit(X_train,Y_train)#训练
#--------------------------------4.模型预测---------------------------------#
Y_pre=clas.predict(X_test)#预测测试集
#--------------------------------5.性能评估---------------------------------#
m = sm.confusion_matrix(Y_test, Y_pre) #生成混淆矩阵
print('混淆矩阵为:', m, sep='\n')
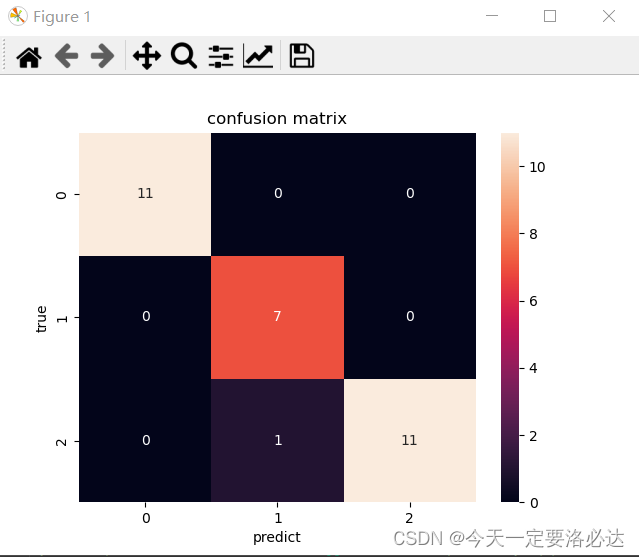
ax = sn.heatmap(m,annot=True,fmt='.20g')
ax.set_title('confusion matrix')
ax.set_xlabel('predict')
ax.set_ylabel('true')
plt.show() #混淆矩阵可视化
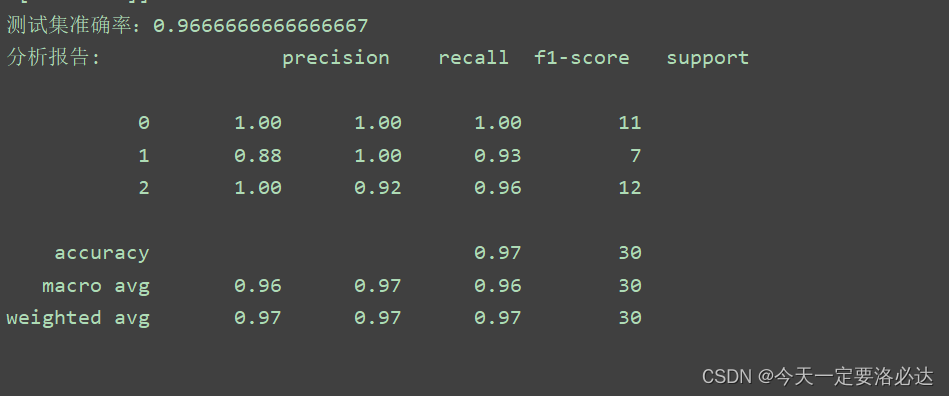
print("测试集准确率:%s"%clas.score(X_test,Y_test)) #输出测试集准确度
print("分析报告:",classification_report(Y_test,Y_pre))#生成分类报告
混淆矩阵可视化:
对角线上的部分说明分类正确,第三行第二列的1表示有一个错了,真实类别为2,但是预测为了1
测试集准确率和分类分析报告:
 、
、
三.其他基础算法学习
3.1.数据集划分函数train_test_split
首先看下它的构造
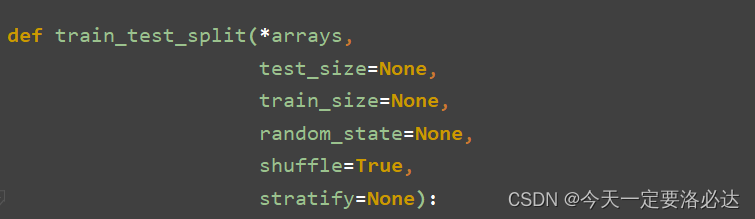
它的功能主要是用来划分数据的,按比例划分。
实际例子如下:
from sklearn.model_selection import train_test_split #数据集划分
X=[[1,2],[2,3],[3,4],[4,5],[5,6]]
Y=[0,0,1,0,1]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2,random_state=42) # 数据划分
print(X_train)
print(X_test)
print(Y_train)
print(Y_test)
结果:
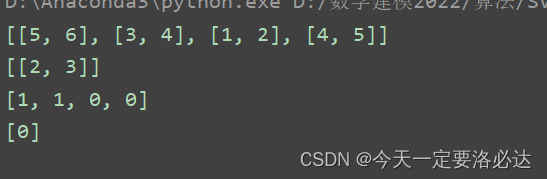
其中有几个参数重点强调一下:
1.test_size=0.2意思是测试集占比为0.2
2.random_state=42。这个是随机数种子的意思,最开始它的作用我也理解了好久。简单的说,就是必须给它赋值,不然每一次划分出来的数据集是不一样的,这对后面各个算法测评该数据集具有很严重的影响(要评价哪一种算法好,数据集必须先保持一致。) 至于取多少,网上很多人取42.
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)