基于springboot+vue+爬虫实现电影推荐系统
这是一个前后端分离的电影管理和推荐系统,采用Vue.js + Spring Boot技术栈开发,电影数据来源于豆瓣,采用Python爬虫进行爬取相关电影的数据,将数据插入MYSQL数据库,然后在前端进行数据展示。后台主要进行电影相关基本数据的管理功能。给用户推荐的电影数据写入到REDIS数据库中进行存储。作者简介:Java领域优质创作者、CSDN博客专家 、掘金特邀作者、多年架构师设计经验、腾讯课
·
项目编号:BS-XX-136
一,项目简介
这是一个前后端分离的电影管理和推荐系统,采用Vue.js + Spring Boot技术栈开发,电影数据来源于豆瓣,采用Python爬虫进行爬取相关电影的数据,将数据插入MYSQL数据库,然后在前端进行数据展示。后台主要进行电影相关基本数据的管理功能。给用户推荐的电影数据写入到REDIS数据库中进行存储。推荐算法采用协同过滤算法,采用于ItemCF和UserCF相结合的方式来进行推荐。
二,环境介绍
语言环境:Java: jdk1.8
数据库:Mysql: mysql5.7+Redis
应用服务器:Tomcat: tomcat8.5.31
开发工具:IDEA或eclipse
前端技术栈: - Vue.js - ElementUI - axios
后端技术栈: - Spring Boot - MyBatis - Apache Shiro - Spring Data Redis
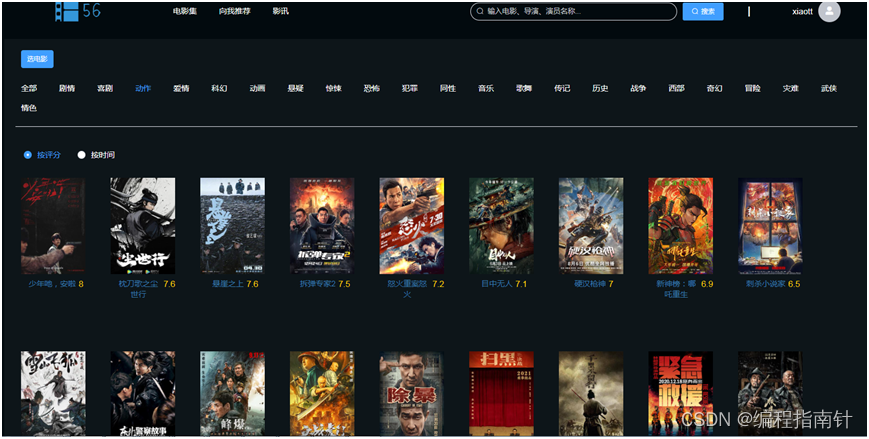
三,系统展示
前端分类列表

详情展示

全文检索

电影推荐

后台管理


电影管理

注册

登陆

四,核心代码展示
package com.fivesix.fivesixserver.controller;
import com.fivesix.fivesixserver.entity.Menu;
import com.fivesix.fivesixserver.service.MenuService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
public class MenuController {
@Autowired
MenuService menuService;
@GetMapping("/api/menu")
public List<Menu> getMenusOfUser() {
return menuService.listAllByCurrUser();
}
@GetMapping("/api/admin/role/menu")
public List<Menu> getMenusOfRole() {
return menuService.listAllByRole(1);
}
}
package com.fivesix.fivesixserver.controller;
import com.fivesix.fivesixserver.entity.Movie;
import com.fivesix.fivesixserver.service.MovieService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.io.IOException;
import java.util.Comparator;
import java.util.List;
import java.util.UUID;
import java.util.stream.Collectors;
@RestController
public class MovieController {
@Autowired
MovieService movieService;
/*
前台请求接口
*/
@GetMapping("/api/movies")
public List<Movie> list() throws Exception {
System.out.println("load all movies sorted by rate successfully.");
return movieService.list().stream().sorted(Comparator.comparingDouble(Movie::getRate).reversed()).collect(Collectors.toList());
}
@GetMapping("/api/movies/page/{pageIndex}")
public List<Movie> listByPageIndex(@PathVariable("pageIndex") int pageIndex) {
System.out.printf("请求起始为%d:的21部电影\n",pageIndex);
return movieService.listByPageIndex(pageIndex).stream().sorted(Comparator.comparingDouble(Movie::getRate).reversed()).collect(Collectors.toList());
}
@GetMapping("/api/movies/category/{cid}/{dateOrRate}")
public Object listByCategory(@PathVariable("cid") int cid, @PathVariable("dateOrRate") int dateOrRate) throws Exception {
List<Movie> res;
if (cid == 0) {
res = movieService.list();
}else{
res = movieService.listByCategory(cid);
}
if (dateOrRate == 1) return res.stream().sorted(Comparator.comparingDouble(Movie::getRate).reversed()).collect(Collectors.toList());
else return res.stream().sorted(Comparator.comparing(Movie::getDate).reversed()).collect(Collectors.toList());
}
@GetMapping("/api/search")
public List<Movie> listByKeywords(@RequestParam("keywords") String keywords) {
if (!keywords.equals("")){
System.out.println("search result returned.");
return movieService.listByKeywords(keywords).stream().sorted(Comparator.comparing(Movie::getDate).reversed()).collect(Collectors.toList());
}else{
return null;
}
}
/*
以下为后台请求接口
*/
@PostMapping("/api/admin/content/movie/update")
public Movie save(@RequestBody Movie movie, @RequestParam(value = "changeCategories") String categoriesIsChanged) throws Exception {
Movie movie1 = movieService.getByMovieName(movie.getTitle());
if (movie1 != null) {
if (categoriesIsChanged.equals("true")) {
movieService.updateMovieAndCategories(movie);
System.out.println("update movie and categories.");
} else {
movieService.update(movie);
System.out.println("update movie.");
}
} else {
movieService.save(movie);
System.out.println("add new movie.");
}
return movie;
}
@PostMapping("/api/admin/content/movie/delete")
public void delete(@RequestBody Movie movie) throws Exception{
movieService.deleteById(movie.getId());
System.out.println("delete movie by id successfully.");
}
/*
电影封面上传
*/
@PostMapping("/api/admin/content/movie/cover")
public String coversUpload(MultipartFile file) throws Exception {
String folder = "D:/workspace/fivesix/img/full";
File imageFolder = new File(folder);
//对文件重命名,保留文件的格式png/jpg
String newName = UUID.randomUUID().toString();
File f = new File(imageFolder, newName + file.getOriginalFilename()
.substring(file.getOriginalFilename().length() - 4));
if (!f.getParentFile().exists())
f.getParentFile().mkdirs();
try {
file.transferTo(f);
String imgURL = "http://localhost:8443/api/file/" + f.getName();
return imgURL;
} catch (IOException e) {
e.printStackTrace();
return "";
}
}
}
package com.fivesix.fivesixserver.controller;
import com.fivesix.fivesixserver.entity.User;
import com.fivesix.fivesixserver.result.Result;
import com.fivesix.fivesixserver.service.UserService;
import org.apache.shiro.SecurityUtils;
import org.apache.shiro.authc.AuthenticationException;
import org.apache.shiro.authc.UsernamePasswordToken;
import org.apache.shiro.crypto.SecureRandomNumberGenerator;
import org.apache.shiro.crypto.hash.SimpleHash;
import org.apache.shiro.subject.Subject;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.util.HtmlUtils;
import java.util.List;
@RestController
public class UserController {
private final UserService userService;
public UserController (UserService userService) {
this.userService = userService;
}
@PostMapping(value = "/api/login")
public Result login(@RequestBody User requestUser,@RequestParam(value = "rememberMe") boolean rememberMe) {
String requestUserName = HtmlUtils.htmlEscape(requestUser.getUsername());
Subject subject = SecurityUtils.getSubject();
UsernamePasswordToken usernamePasswordToken = new UsernamePasswordToken(requestUserName,requestUser.getPassword());
usernamePasswordToken.setRememberMe(rememberMe);
try{
subject.login(usernamePasswordToken);
return new Result(200,"login successfully");
} catch (AuthenticationException e) {
e.printStackTrace();
return new Result(400,"账号或密码错误");
}
}
@PostMapping("/api/register")
public Result register(@RequestBody User user) {
String username = HtmlUtils.htmlEscape(user.getUsername());
user.setUsername(username);
//生成盐
String salt = new SecureRandomNumberGenerator().nextBytes().toString();
user.setSalt(salt);
//设置迭代次数
int times = 2;
//生成加密的密码
String encodedPassword = new SimpleHash("md5",user.getPassword(),salt,times).toString();
user.setPassword(encodedPassword);
try {
userService.register(user);
return new Result(200,"register successfully.");
}catch (Exception e) {
e.printStackTrace();
return new Result(400,e.getMessage());
}
}
@GetMapping("api/logout")
public Result logout() {
Subject subject = SecurityUtils.getSubject();
subject.logout();
return new Result(200,"登出成功");
}
@GetMapping("api/authentication")
public Result authenticate() {
return new Result(200,"认证成功");
}
@GetMapping("api/admin/user")
public List<User> getAllUsers() {
return userService.listAll();
}
@PostMapping("api/admin/user/delete")
public Result delete(@RequestBody User user) {
try {
userService.deleteUser(user);
return new Result(200,"删除用户成功");
}catch (Exception e) {
return new Result(400,"删除用户失败");
}
}
@PutMapping("api/admin/user/update")
public Result update(@RequestBody User user) {
try{
userService.updateUser(user);
return new Result(200,"更新用户成功");
}catch (Exception e){
return new Result(400,"更新用户失败");
}
}
}
使用Python来进行电影数据爬取的核心代码
# -*- coding: utf-8 -*-
import scrapy
import json
import re
import time
from douban.items import DoubanItem
from fake_useragent import UserAgent
import random
class MovieHotSpider(scrapy.Spider):
#爬虫的名称,在命令行可以方便的运行爬虫
name = "movie_hot"
allowed_domains = ["movie.douban.com"]
#pro = ['139.224.37.83','115.223.7.110','221.122.91.75']
# 拼接豆瓣电影URL
BASE_URL = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%s&sort=recommend&page_limit=%s&page_start=%s'
MOVIE_TAG = '华语'
PAGE_LIMIT = 20
page_start = 0
domains = BASE_URL % (MOVIE_TAG, PAGE_LIMIT, page_start)
#伪装浏览器
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
#,"Cookie":'_vwo_uuid_v2=D65EBF690D9454DE4C13354E37DC5B9AA|3bb7e6e65f20e31141b871b4fea88dc2; __yadk_uid=QBp8bLKHjCn5zS2J5r8xV7327R0wnqkU; douban-fav-remind=1; gr_user_id=0a41d8d1-fe39-4619-827a-17961cf31795; viewed="35013197_10769749_23008813_26282806_34912177_22139960_35003794_30249691_26616244_27035127"; push_noty_num=0; push_doumail_num=0; __utmv=30149280.21320; bid=gplG4aEN4Xc; ll="108288"; ap_v=0,6.0; __utma=30149280.819011260.1572087992.1604448803.1604453561.105; __utmc=30149280; __utmz=30149280.1604453561.105.65.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __gads=ID=eddb65558a1da756-223ab4f88bc400c8:T=1604453562:RT=1604453562:S=ALNI_MZGB_I69qmiL2tt3lm57JVX1i4r2w; __utmb=30149280.4.10.1604453561; dbcl2="213202515:Ip9mjwUAab4"; ck=wxUS; __utma=223695111.897479705.1572088003.1604448803.1604455298.71; __utmb=223695111.0.10.1604455298; __utmc=223695111; __utmz=223695111.1604455298.71.42.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1604455298%2C%22https%3A%2F%2Faccounts.douban.com%2F%22%5D; _pk_ses.100001.4cf6=*; _pk_id.100001.4cf6=e11874c5506d4ab1.1572088003.71.1604455342.1604450364.'
}
#总共爬取的页数
pages = 100
# 爬虫从此开始
def start_requests(self):
print('~~~~爬取列表: '+ self.domains)
yield scrapy.Request(
url = self.domains,
headers=self.headers,
callback=self.request_movies
)
# 分析列表页
def request_movies(self, response):
infos = response.text
# 使用JSON模块解析响应结果
infos = json.loads(infos)
# 迭代影片信息列表
for movie_info in infos['subjects']:
print('~~~爬取电影: ' + movie_info['title'] + '/'+ movie_info['rate'])
# 提取影片页面url,构造Request发送请求,并将item通过meta参数传递给影片页面解析函数
yield scrapy.Request(
url = str(movie_info['url']),
headers = self.headers,
callback = self.request_movie,
dont_filter=True
)
#如果已经爬完pages或者当前标签下没有更多电影时退出
if self.pages > 0 and len(infos['subjects']) == self.PAGE_LIMIT:
self.pages -= 1
self.page_start += self.PAGE_LIMIT
url = self.BASE_URL % (self.MOVIE_TAG,self.PAGE_LIMIT,self.page_start)
time.sleep(5)
print('-----爬取列表: ' + url)
yield scrapy.Request(
url=url,
headers=self.headers,
callback=self.request_movies,
dont_filter=True
)
# 分析详情页
def request_movie(self, response):
#组装数据
movie_item = DoubanItem()
title = response.css('div#content>h1>span:nth-child(1)::text').extract_first()
t = re.findall('[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5_0-9]', title)
#获取非info区域数据
movie_item['title'] = ''.join(t)
movie_item['date'] = response.css('div#content>h1>span.year::text').extract_first()[1:-1]
movie_item['rate'] = response.css('strong.rating_num::text').extract_first()
#movie_item['commentCount'] = response.css('div.rating_sum>a.rating_people>span::text').extract_first()
#movie_item['start'] = '/'.join(response.css('span.rating_per::text').extract())
#movie_item['better'] = '/'.join(response.css('div.rating_betterthan>a::text').extract())
movie_item['abs'] = response.css('#link-report>span::text').extract_first().strip()
movie_item['cover'] = response.css('#mainpic>a>img::attr(src)').extract_first()
# 获取整个信息字符串
info = response.css('div.subject div#info').xpath('string(.)').extract_first()
# 提取所以字段名
fields = [s.strip().replace(':', '') for s in response.css('div#info span.pl::text').extract()]
# 提取所有字段的值
values = [re.sub('\s+', '', s.strip()) for s in re.split('\s*(?:%s):\s*' % '|'.join(fields), info)][1:]
# 处理列名称
for i in range(len(fields)):
if '导演' == fields[i]:
fields[i] = 'director'
if '编剧' == fields[i]:
fields[i] = 'scriptwriter'
if '主演' == fields[i]:
fields[i] = 'actors'
if '类型' == fields[i]:
fields[i] = 'categories'
if '制片国家/地区' == fields[i]:
fields[i] = 'district'
if '语言' == fields[i]:
fields[i] = 'language'
if '片长' == fields[i]:
fields[i] = 'duration'
# 将所有信息填入item
other_info = list(zip(fields,values))
for field,value in other_info:
if field in ['IMDb链接','上映日期','官方网站','又名']:
other_info.remove((field,value))
final_info = dict(other_info[:-1])
movie_item.update(final_info)
# 处理缺失字段
if not 'director' in movie_item.keys():
movie_item['director'] = '/'
if not 'scriptwriter' in movie_item.keys():
movie_item['scriptwriter'] = '/'
if not 'actors' in movie_item.keys():
movie_item['actors'] = '/'
if not 'categories' in movie_item.keys():
movie_item['categories'] = '/'
if not 'district' in movie_item.keys():
movie_item['district'] = '/'
if not 'language' in movie_item.keys():
movie_item['language'] = '/'
if not 'duration' in movie_item.keys():
movie_item['duration'] = '/'
print('~完成爬取电影: ' + movie_item['title'] + '/' + movie_item['rate'])
#将数据加入到字典中
yield movie_item
五,项目总结
项目采用前后端分离的方式来进行开发实现,并进行了数据的爬取操作,相关亮点比较多,业务功能相对较少。主要实现数据的爬取及展示以及相关的推荐功能。

前往低代码交流专区
更多推荐

 2
2 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)