
[MindSpore]报错RuntimeError: Exception thrown from PyFunc.
MindSpore教程->数据处理->自定义数据集
1 报错描述
1.1 系统环境
ardware Environment(Ascend/GPU/CPU): CPU
Software Environment:
– MindSpore version (source or binary): 1.7.0
– Python version (e.g., Python 3.7.5): 3.7.6
– OS platform and distribution (e.g., Linux Ubuntu 16.04): Windows-10-10.0.19041-SP0
– GCC/Compiler version (if compiled from source):
1.2 基本信息
1.2.1脚本
此案例为创建一个做超分辨率的数据集,使用mindspore.dataset.GeneratorDataset接口实现自定义方式的进行数据集加载。
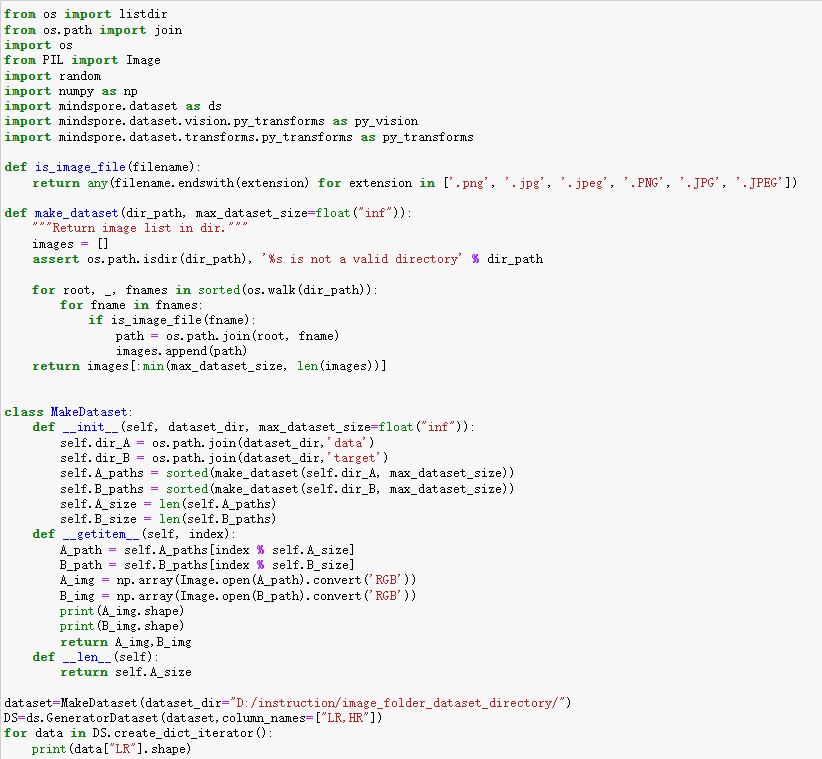
1.2.2报错
报错信息:RuntimeError: Exception thrown from PyFunc. Invalid python function, the ‘source’ of ‘GeneratorDataset’ should return same number of NumPy arrays as specified in column_names, the size of column_names is:1 and number of returned NumPy array is:2
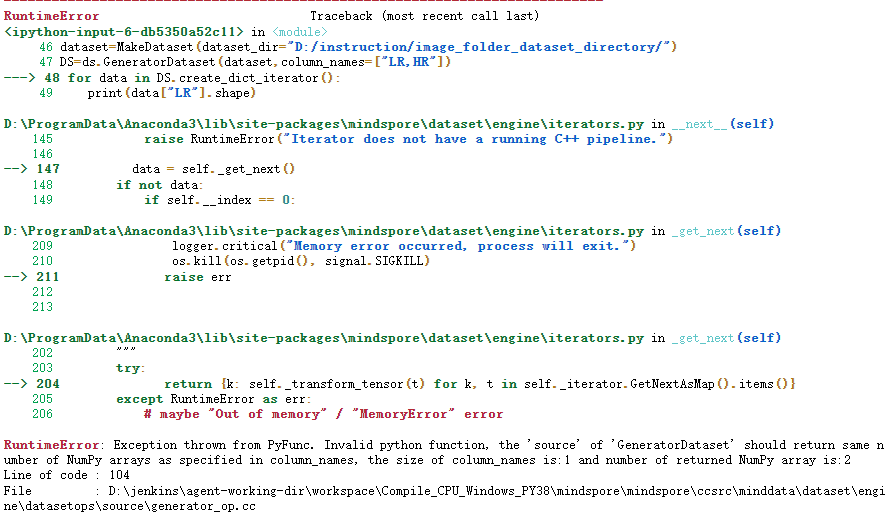
2 原因分析
根据报错信息提示,GeneratorDataset中使用到的数据返回字段应与指定的列名个数一致,但目前指定列名个数为1,返回列数为2。按照数据返回列数分析,应定义两个列名, 但源码中:DS=ds.GeneratorDataset(dataset,column_names=[“LR,HR”]),[“LR,HR”]表示为一个字段,故应在此部分进行修改。
3 解决方法
DS=ds.GeneratorDataset(dataset,column_names=[“LR,HR”])
改为与输入数据返回字段相匹配的形式:
DS=ds.GeneratorDataset(dataset,column_names=[“LR”,“HR”])
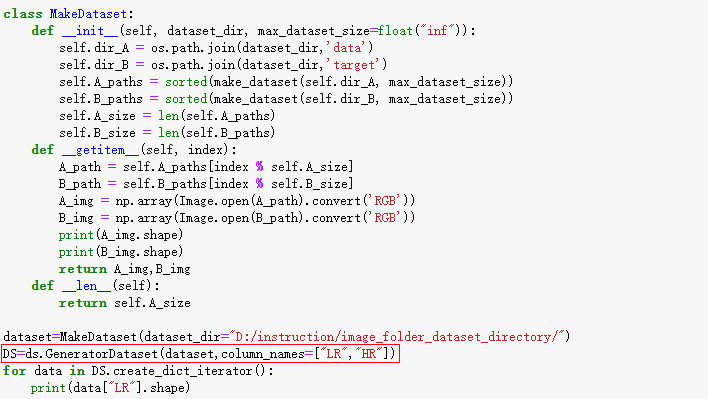
此时正常执行,可创建自定义数据集,输出如下:

4 总结
定位报错问题的步骤:
1、找到报错的用户代码行:for data in DS.create_dict_iterator():;
2、根据日志报错信息中的提示,定位到自定义数据返回时出现问题。GeneratorDataset返回与定义的columns字段不一致,导致报错。
3、自定义数据集创建时返回与定义的字段保持一致。
5 参考文档
mindspore教程->数据处理->自定义数据集
自定义数据集 — MindSpore master documentation
更多推荐




 1
1 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)