
ShardingSphere分库分表核心原理精讲第五节 扩展性
12从应用到原理:如何高效阅读 ShardingSphere 源码?从本课时开始,专栏将进入:“ShardingSphere 源码解析之基础设施”的模块。在介绍完 ShardingSphere 所具备的分库分表、读写分离、分布式事务、数据脱敏等各项核心功能之后,我将带领你全面剖析这些核心功能背后的实现原理和机制。我们将通过深入解析 ShardingSphere 源码这一途径来实现这一目标。如何系统
12 从应用到原理:如何高效阅读 ShardingSphere 源码?
从本课时开始,专栏将进入:“ShardingSphere 源码解析之基础设施”的模块。在介绍完 ShardingSphere 所具备的分库分表、读写分离、分布式事务、数据脱敏等各项核心功能之后,我将带领你全面剖析这些核心功能背后的实现原理和机制。我们将通过深入解析 ShardingSphere 源码这一途径来实现这一目标。
如何系统剖析 ShardingSphere 的代码结构?
在阅读开源框架时,我们碰到的一大问题在于,常常会不由自主地陷入代码的细节而无法把握框架代码的整体结构。市面上主流的、被大家所熟知而广泛应用的代码框架肯定考虑得非常周全,其代码结构不可避免存在一定的复杂性。对 ShardingSphere 而言,情况也是一样,我们发现 ShardingSphere 源码的一级代码结构目录就有 15 个,而这些目录内部包含的具体 Maven 工程则多达 50 余个:
ShardingSphere 源码一级代码结构目录
如何快速把握 ShardingSphere 的代码结构呢?这是我们剖析源码时需要回答的第一个问题,为此我们需要梳理剖析 ShardingSphere 框架代码结构的系统方法。
本课时我们将对如何系统剖析 ShardingSphere 代码结构这一话题进行抽象,梳理出应对这一问题的六大系统方法(如下图):
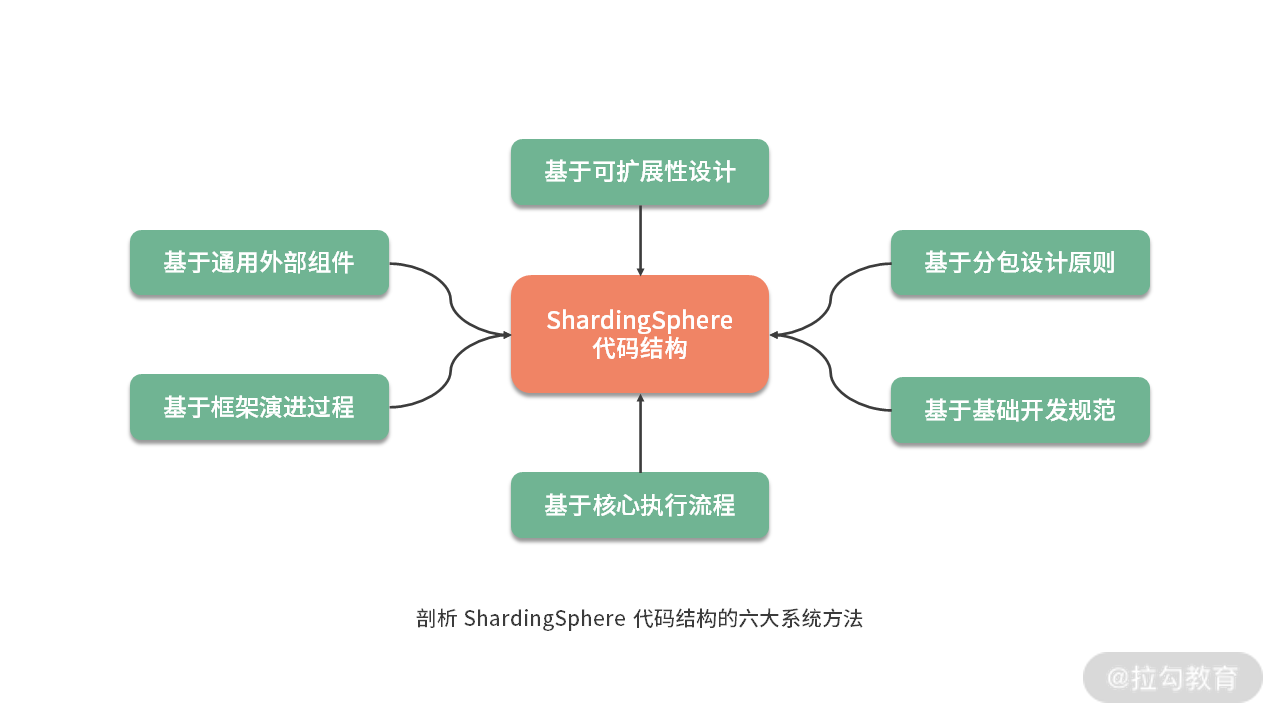
接下来,我们将结合 ShardingSphere 框架对这些方法进行展开。
基于可扩展性设计阅读源码
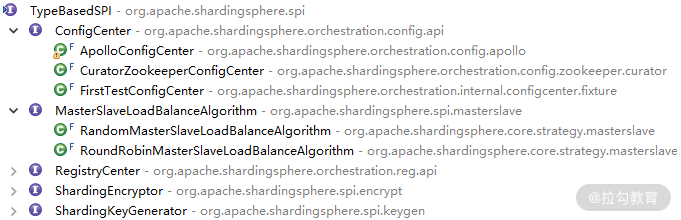
ShardingSphere 在设计上采用了微内核架构模式来确保系统具有高度的可扩展性,并使用了 JDK 提供的 SPI 机制来具体实现微内核架构。在 ShardingSphere 源代码的根目录下,存在一个独立工程 shardingsphere-spi。显然,从命名上看,这个工程中应该包含了 ShardingSphere 实现 SPI 的相关代码。该工程中存在一个 TypeBasedSPI 接口,它的类层结构比较丰富,课程后面将要讲到的很多核心接口都继承了该接口,包括实现配置中心的 ConfigCenter、注册中心的 RegistryCenter 等,如下所示:
ShardingSphere 中 TypeBasedSPI 接口的类层结构
这些接口的实现都遵循了 JDK 提供的 SPI 机制。在我们阅读 ShardingSphere 的各个代码工程时,一旦发现在代码工程中的 META-INF/services 目录里创建了一个以服务接口命名的文件,就说明这个代码工程中包含了用于实现扩展性的 SPI 定义。
在 ShardingSphere 中,大量使用了微内核架构和 SPI 机制实现系统的扩展性。只要掌握了微内核架构的基本原理以及 SPI 的实现方式就会发现,原来在 ShardingSphere 中,很多代码结构上的组织方式就是为了满足这些扩展性的需求。ShardingSphere 中实现微内核架构的方式就是直接对 JDK 的 ServiceLoader 类进行一层简单的封装,并添加属性设置等自定义的功能,其本身并没有太多复杂的内容。
当然,可扩展性的表现形式不仅仅只有微内核架构一种。在 ShardingSphere 中也大量使用了回调(Callback)机制以及多种支持扩展性的设计模式。掌握这些机制和模式也有助于更好地阅读 ShardingSphere 源码。
基于分包设计原则阅读源码
分包(Package)设计原则可以用来设计和规划开源框架的代码结构。对于一个包结构而言,最核心的设计要点就是高内聚和低耦合。我们刚开始阅读某个框架的源码时,为了避免过多地扎进细节而只关注某一个具体组件,同样可以使用这些原则来管理我们的学习预期。
以 ShardingSphere 为例,我们在分析它的路由引擎时发现了两个代码工程,一个是 sharding-core-route,一个是 sharding-core-entry。从代码结构上讲,尽管这两个代码工程都不是直接面向业务开发人员,但 sharding-core-route 属于路由引擎的底层组件,包含了路由引擎的核心类 ShardingRouter。
而 sharding-core-entry 则位于更高的层次,提供了 PreparedQueryShardingEngine 和 SimpleQueryShardingEngine 类,分包结构如下所示:
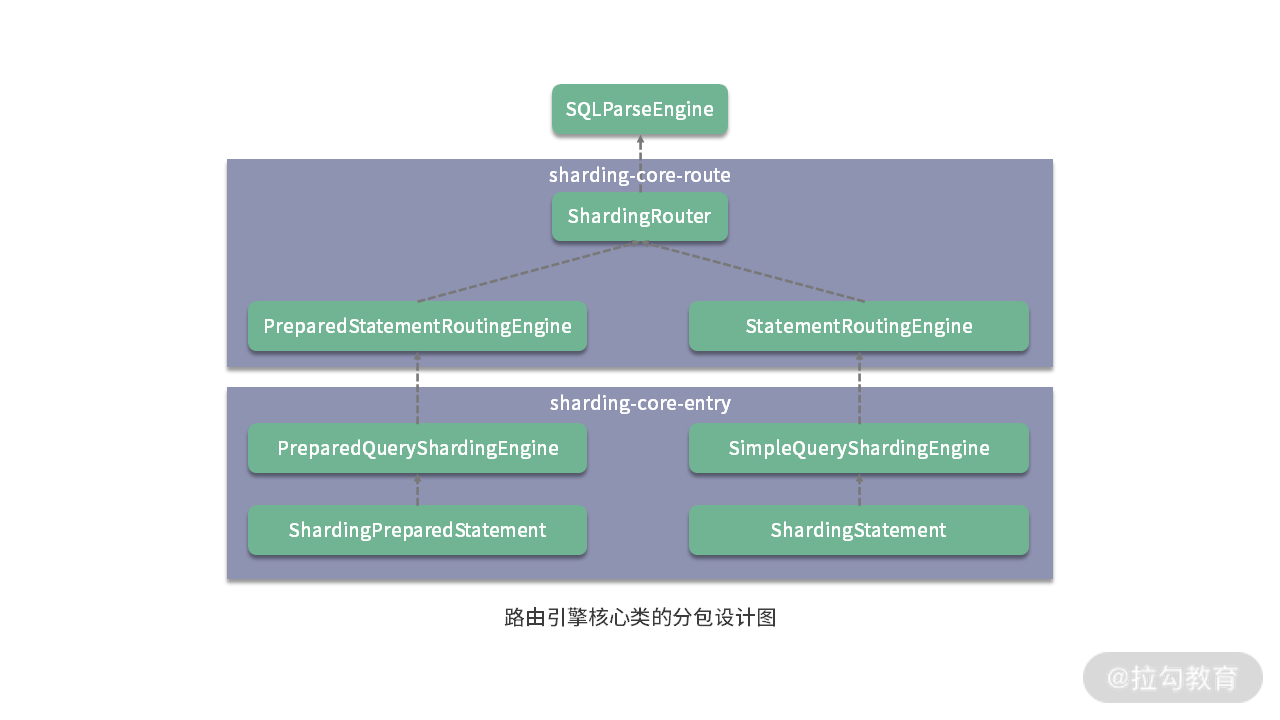
图中我们可以看到两个清晰的代码结构层次关系,这是 ShardingSphere 中普遍采用的分包原则中,具有代表性的一种,即根据类的所属层级来组织包结构。
基于基础开发规范阅读源码
对于 ShardingSphere 而言,在梳理它的代码结构时有一个非常好的切入点,那就是基于 JDBC 规范。我们知道 ShardingSphere 在设计上一开始就完全兼容 JDBC 规范,它对外暴露的一套分片操作接口与 JDBC 规范中所提供的接口完全一致。只要掌握了 JDBC 中关于 DataSource、Connection、Statement 等核心接口的使用方式,就可以非常容易地把握 ShardingSphere 中暴露给开发人员的代码入口,进而把握整个框架的代码结构。
我们来看这方面的示例,如果你是刚接触到 ShardingSphere 源码,要想找到 SQL 执行入口是一件有一定难度的事情。在 ShardingSphere 中,存在一个 ShardingDataSourceFactory 工厂类,专门用来创建 ShardingDataSource。而基于《规范兼容:JDBC 规范与 ShardingSphere 是什么关系?》中的讨论,ShardingDataSource 就是一个 JDBC 规范中的 DataSource 实现类:
public final class ShardingDataSourceFactory {
public static DataSource createDataSource(
final Map<String, DataSource> dataSourceMap, final ShardingRuleConfiguration shardingRuleConfig, final Properties props) throws SQLException {
return new ShardingDataSource(dataSourceMap, new ShardingRule(shardingRuleConfig, dataSourceMap.keySet()), props);
}
}
通过这个工厂类,我们很容易就找到了创建支持分片机制的 DataSource 入口,从而引出其背后的 ShardingConnection、ShardingStatement 等类。
事实上,在 ShardingSphere 中存在一批 DataSourceFactory 工厂类以及对应的 DataSource 类:
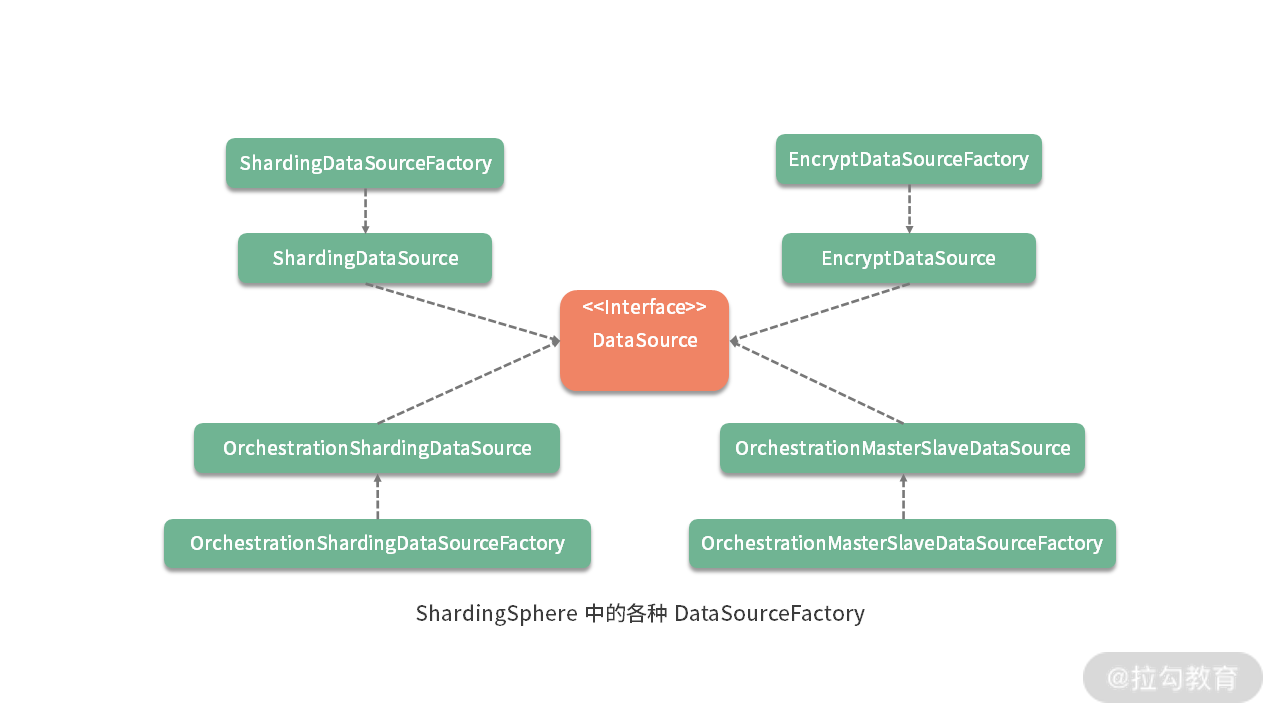
在阅读 ShardingSphere 源码时,JDBC 规范所提供的核心接口及其实现类,为我们高效梳理代码入口和组织方式提供了一种途径。
基于核心执行流程阅读源码
事实上,还有一个比较容易理解和把握的方法可以帮我们梳理代码结构,这就是代码的执行流程。任何系统行为都可以认为是流程的组合。通过分析,看似复杂的代码结构一般都能梳理出一条贯穿全局的主流程。只要我们抓住这条主流程,就能把握框架的整体代码结构。
那么,对于 ShardingSphere 框架而言,什么才是它的主流程呢?这个问题其实不难回答。事实上,JDBC 规范为我们实现数据存储和访问提供了基本的开发流程。我们可以从 DataSource 入手,逐步引入 Connection、Statement 等对象,并完成 SQL 执行的主流程。这是从框架提供的核心功能角度梳理的一种主流程。
对于框架内部的代码组织结构而言,实际上也存在着核心流程的概念。最典型的就是 ShardingSphere 的分片引擎结构,整个分片引擎执行流程可以非常清晰的分成五个组成部分,分别是解析引擎、路由引擎、改写引擎、执行引擎和归并引擎:
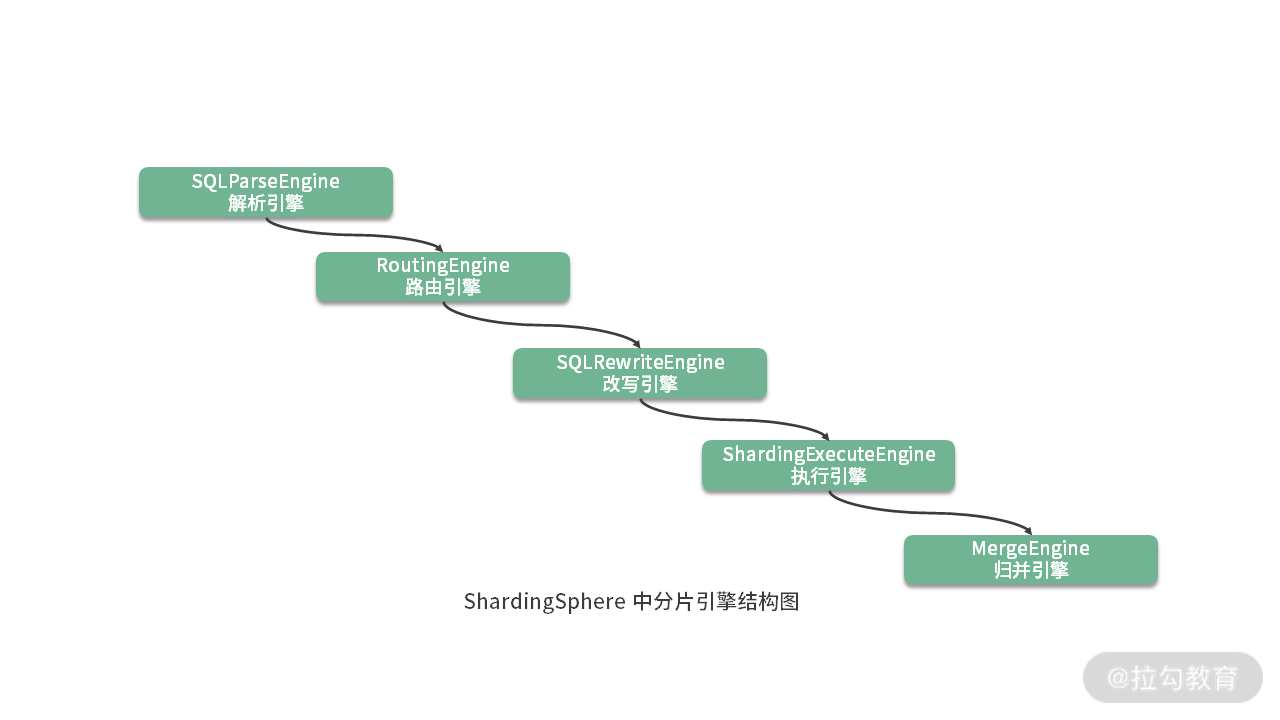
ShardingSphere 对每个引擎都进行了明确地命名,在代码工程的组织结构上也做了对应的约定,例如 sharding-core-route 工程用于实现路由引擎;sharding-core-execute 工程用于实现执行引擎;sharding-core-merge 工程用于实现归并引擎等。这是从框架内部实现机制角度梳理的一种主流程。
在软件建模领域,可以通过一些工具和手段对代码执行流程进行可视化,例如 UML 中的活动图和时序图。在后续的课时中,我们会基于这些工具帮你梳理 ShardingSphere 中很多有待挖掘的代码执行流程。
基于框架演进过程阅读源码
ShardingSphere 经历了从 1.X 到 4.X 版本的发展,功能越来越丰富,目前的代码结构已经比较复杂。但我相信 ShardingSphere 的开发人员也不是一开始就把 ShardingSphere 设计成现在这种代码结构。换个角度,如果我们自己来设计这样一个框架,通常会采用一定的策略,从简单到复杂、从核心功能到辅助机制,逐步实现和完善框架,这也是软件开发的一个基本规律。针对这个角度,当我们想要解读 ShardingSphere 的代码结构而又觉得无从下手时,可以考虑一个核心问题:如何从易到难对框架进行逐步拆解?
实际上,在前面几个课时介绍 ShardingSphere 的核心功能时已经回答了这个问题。我们首先介绍的是分库分表功能,然后扩展到读写分离,然后再到数据脱敏。从这些功能的演进我们可以推演其背后的代码结构的演进。这里以数据脱敏功能的实现过程为例来解释这一观点。
在 ShardingSphere 中,数据脱敏功能的实现实际上并不是独立的,而是依赖于 SQL 改写引擎。我们可以快速来到 BaseShardingEngine 类的 rewriteAndConvert 方法中:
private Collection<RouteUnit> rewriteAndConvert(final String sql, final List<Object> parameters, final SQLRouteResult sqlRouteResult) {
//构建SQLRewriteContext
SQLRewriteContext sqlRewriteContext = new SQLRewriteContext(metaData.getRelationMetas(), sqlRouteResult.getSqlStatementContext(), sql, parameters);
//构建ShardingSQLRewriteContextDecorator对SQLRewriteContext进行装饰
new ShardingSQLRewriteContextDecorator(shardingRule, sqlRouteResult).decorate(sqlRewriteContext);
//判断是否根据数据脱敏列进行查询
boolean isQueryWithCipherColumn = shardingProperties.<Boolean>getValue(ShardingPropertiesConstant.QUERY_WITH_CIPHER_COLUMN);
//构建EncryptSQLRewriteContextDecorator对SQLRewriteContext进行装饰
new EncryptSQLRewriteContextDecorator(shardingRule.getEncryptRule(), isQueryWithCipherColumn).decorate(sqlRewriteContext);
//生成SQLTokens
sqlRewriteContext.generateSQLTokens();
…
return result;
}
注意,这里基于装饰器模式实现了两个 SQLRewriteContextDecorator,一个是 ShardingSQLRewriteContextDecorator,另一个是 EncryptSQLRewriteContextDecorator,而后者是在前者的基础上完成装饰工作。也就是说,我们首先可以单独使用 ShardingSQLRewriteContextDecorator 来完成对 SQL 的改写操作。
随着架构的演进,我们也可以在原有 EncryptSQLRewriteContextDecorator 的基础上添加新的面向数据脱敏的功能,这就体现了一种架构演进的过程。通过阅读这两个装饰器类,以及 SQL 改写上下文对象 SQLRewriteContext,我们就能更好地把握代码的设计思想和实现原理:
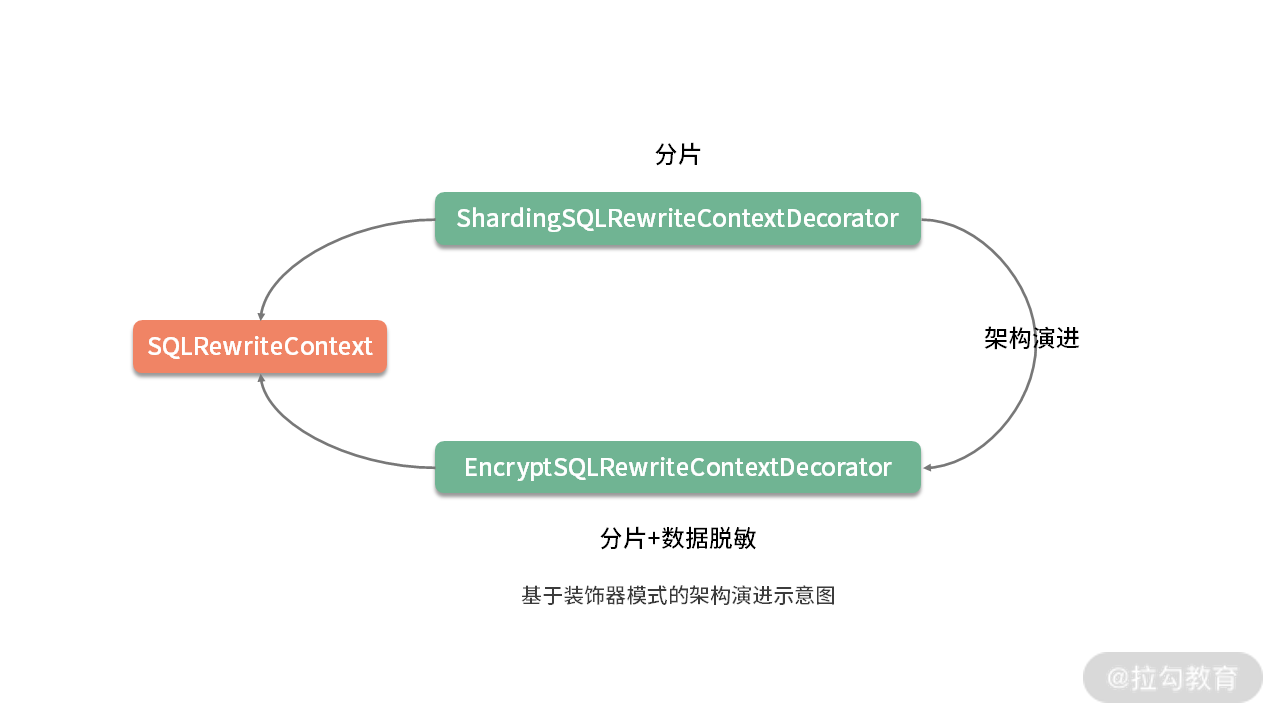
关于数据脱敏以及装饰器模式的具体实现细节我们会在《数据脱敏:如何基于改写引擎实现低侵入性数据脱敏方案?》中进行详细展开。
基于通用外部组件阅读源码
在《开篇寄语:如何正确学习一款分库分表开源框架?》中,我们提出了一种观点,即技术原理存在相通性。这点同样可以帮助我们更好地阅读 ShardingSphere 源码。
在 ShardingSphere 中集成了一批优秀的开源框架,包括用于实现配置中心和注册中心的Zookeeper、Apollo、Nacos,用于实现链路跟踪的 SkyWalking,用于实现分布式事务的 Atomikos 和 Seata 等。
我们先以分布式事务为例,ShardingSphere 提供了一个 sharding-transaction-core 代码工程,用于完成对分布式事务的抽象。然后又针对基于两阶段提交的场景,提供了 sharding-transaction-2pc 代码工程,以及针对柔性事务提供了 sharding-transaction-base 代码工程。而在 sharding-transaction-2pc 代码工程内部,又包含了如下所示的 5 个子代码工程。
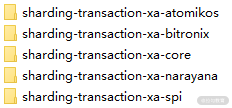
sharding-transaction-2pc 代码工程下的子工程
在翻阅这些代码工程时,会发现每个工程中的类都很少,原因就在于,这些类都只是完成与第三方框架的集成而已。所以,只要我们对这些第三方框架有一定了解,阅读这部分代码就会显得非常简单。
再举一个例子,我们知道 ZooKeeper 可以同时用来实现配置中心和注册中心。作为一款主流的分布式协调框架,基本的工作原理就是采用了它所提供的临时节点以及监听机制。基于 ZooKeeper 的这一原理,我们可以把当前 ShardingSphere 所使用的各个 DataSource 注册到 ZooKeeper 中,并根据 DataSource 的运行时状态来动态对数据库实例进行治理,以及实现访问熔断机制。事实上,ShardingSphere 能做到这一点,依赖的就是 ZooKeeper 所提供的基础功能。只要我们掌握了这些功能,理解这块代码就不会很困难,而 ShardingSphere 本身并没有使用 ZooKeeper 中任何复杂的功能。
如何梳理ShardingSphere中的核心技术体系?
ShardingSphere 中包含了很多技术体系,在本课程中,我们将从基础架构、分片引擎、分布式事务以及治理与集成等 4 个方面对这些技术体系进行阐述。
基础架构
这里定义基础架构的标准是,属于基础架构类的技术可以脱离 ShardingSphere 框架本身独立运行。也就是说,这些技术可以单独抽离出来,供其他框架直接使用。我们认为 ShardingSphere 所实现的微内核架构和分布式主键可以归到基础架构。
分片引擎
分片引擎是 ShardingSphere 最核心的技术体系,包含了解析引擎、路由引擎、改写引擎、执行引擎、归并引擎和读写分离等 6 大主题,我们对每个主题都会详细展开。分片引擎在整个 ShardingSphere 源码解析内容中占有最大篇幅。
对于解析引擎而言,我们重点梳理 SQL 解析流程所包含的各个阶段;对于路由引擎,我们将在介绍路由基本原理的基础上,给出数据访问的分片路由和广播路由,以及如何在路由过程中集成多种分片策略和分片算法的实现过程;改写引擎相对比较简单,我们将围绕如何基于装饰器模式完成 SQL 改写实现机制这一主题展开讨论;而对于执行引擎,首先需要梳理和抽象分片环境下 SQL 执行的整体流程,然后把握 ShardingSphere 中的 Executor 执行模型;在归并引擎中,我们将分析数据归并的类型,并阐述各种归并策略的实现过程;最后,我们将关注普通主从架构和分片主从架构下读写分离的实现机制。
分布式事务
针对分布式事务,我们需要理解 ShardingSphere 中对分布式事务的抽象过程,然后系统分析在 ShardingSphere 中如何基于各种第三方框架集成强一致性事务和柔性事务支持的实现原理。
治理与集成
在治理和集成部分,从源码角度讨论的话题包括数据脱敏、配置中心、注册中心、链路跟踪以及系统集成。
对于数据脱敏,我们会在改写引擎的基础上给出如何实现低侵入性的数据脱敏方案;配置中心用来完成配置信息的动态化管理,而注册中心则实现了数据库访问熔断机制,这两种技术可以采用通用的框架进行实现,只是面向了不同的业务场景,我们会分析通用的实现原理以及面向业务场景的差异性;ShardingSphere 中实现了一系列的 Hook 机制,我们将基于这些 Hook 机制以及 OpenTracing 协议来剖析实现数据访问链路跟踪的工作机制;当然,作为一款主流的开源框架,ShardingSphere 也完成与 Spring 以及 SpringBoot 的无缝集成,对系统集成方式的分析可以更好地帮助我们使用这个框架。
从源码解析到日常开发
通过系统讲解框架源码来帮助你深入理解 ShardingSphere 实现原理是本课程的一大目标,但也不是唯一目标。作为扩展,我们希望通过对 ShardingSphere 这款优秀开源框架的学习,掌握系统架构设计和实现过程中的方法和技巧,并指导日常的开发工作。例如,在下一课时介绍微内核架构时,我们还将重点描述基于 JDK 所提供的 SPI 机制来实现系统的扩展性,而这种实现机制完全可以应用到日常开发过程中。
这是一个从源码分析到日常开发的过程,而且是一个不断演进的过程。所谓理论指导实践,我们需要从纷繁复杂的技术知识体系和各种层出不穷的工具框架中抓住其背后的原理,然后做到用自己的语言和方法对这些原理进行阐述,也就是能够构建属于你自己的技术知识体系。
总结
本课时是 ShardingSphere 源码解析部分的第一个课时,我们讲解了剖析 ShardingSphere 代码结构的六大系统方法,引导你从可扩展性、分包设计原则、基础开发规范、核心执行流程、框架演进过程、通用外部组件等维度来正确阅读 ShardingSphere 源码。同时,我们针对 ShardingSphere 的基础架构本身以及业务功能来梳理了后续课程将要展开的各项核心技术体系。
这里给你留一道思考题:在剖析 ShardingSphere 的各种方法中,你能针对每个方法列举一两个具体的示例吗?
本课时的内容就到这里,从下一课时开始,我们将进入 ShardingSphere 中基础架构类技术体系的讨论,先要讨论的是微内核架构及其实现原理,记得按时来听课。
13 微内核架构:ShardingSphere 如何实现系统的扩展性?
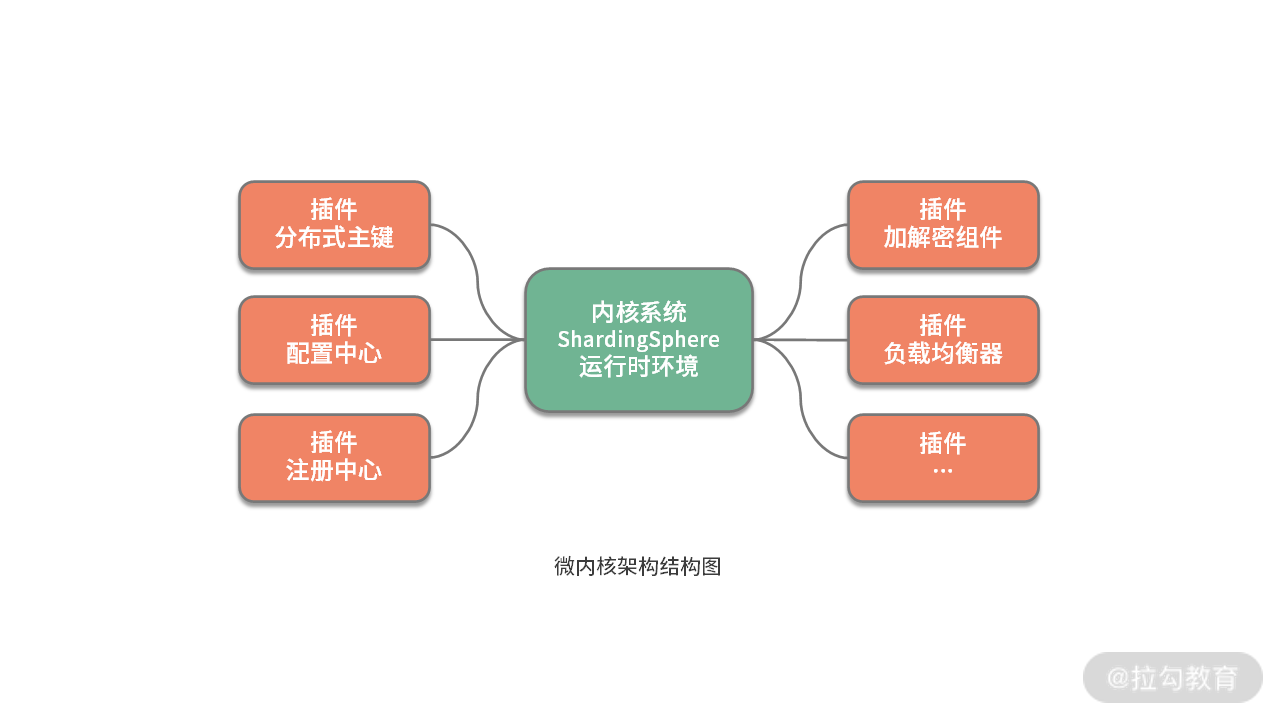
我们已经在课程中多次提到 ShardingSphere 使用了微内核架构来实现框架的扩展性。随着课程的演进,我们会发现,用于实现配置中心的 ConfigCenter、用于数据脱敏的 ShardingEncryptor 以及用于数据库治理的注册中心接口 RegistryCenter 等大量组件的实现也都使用了微内核架构。那么,究竟什么是微内核架构呢?今天我们就来讨论这个架构模式的基本原理以及在 ShardingSphere 中的应用。
什么是微内核架构?
微内核是一种典型的架构模式 ,区别于普通的设计模式,架构模式是一种高层模式,用于描述系统级的结构组成、相互关系及相关约束。微内核架构在开源框架中的应用也比较广泛,除了 ShardingSphere 之外,在主流的 PRC 框架 Dubbo 中也实现了自己的微内核架构。那么,在介绍什么是微内核架构之前,我们有必要先阐述这些开源框架会使用微内核架构的原因。
为什么要使用微内核架构?
微内核架构本质上是为了提高系统的扩展性 。所谓扩展性,是指系统在经历不可避免的变更时所具有的灵活性,以及针对提供这样的灵活性所需要付出的成本间的平衡能力。也就是说,当在往系统中添加新业务时,不需要改变原有的各个组件,只需把新业务封闭在一个新的组件中就能完成整体业务的升级,我们认为这样的系统具有较好的可扩展性。
就架构设计而言,扩展性是软件设计的永恒话题。而要实现系统扩展性,一种思路是提供可插拔式的机制来应对所发生的变化。当系统中现有的某个组件不满足要求时,我们可以实现一个新的组件来替换它,而整个过程对于系统的运行而言应该是无感知的,我们也可以根据需要随时完成这种新旧组件的替换。
比如在下个课时中我们将要介绍的 ShardingSphere 中提供的分布式主键功能,分布式主键的实现可能有很多种,而扩展性在这个点上的体现就是, 我们可以使用任意一种新的分布式主键实现来替换原有的实现,而不需要依赖分布式主键的业务代码做任何的改变 。
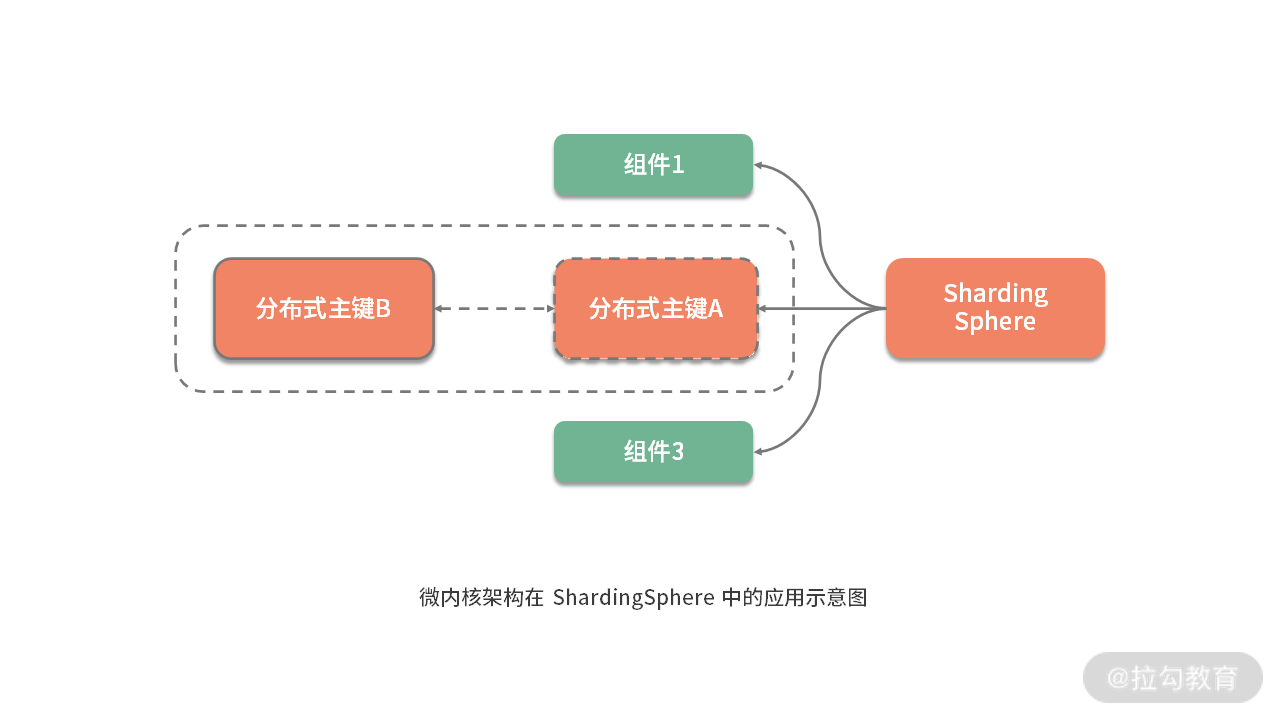
微内核架构模式为这种实现扩展性的思路提供了架构设计上的支持,ShardingSphere 基于微内核架构实现了高度的扩展性。在介绍如何实现微内核架构之前,我们先对微内核架构的具体组成结构和基本原理做简要的阐述。
什么是微内核架构?
从组成结构上讲, 微内核架构包含两部分组件:内核系统和插件 。这里的内核系统通常提供系统运行所需的最小功能集,而插件是独立的组件,包含自定义的各种业务代码,用来向内核系统增强或扩展额外的业务能力。在 ShardingSphere 中,前面提到的分布式主键就是插件,而 ShardingSphere 的运行时环境构成了内核系统。
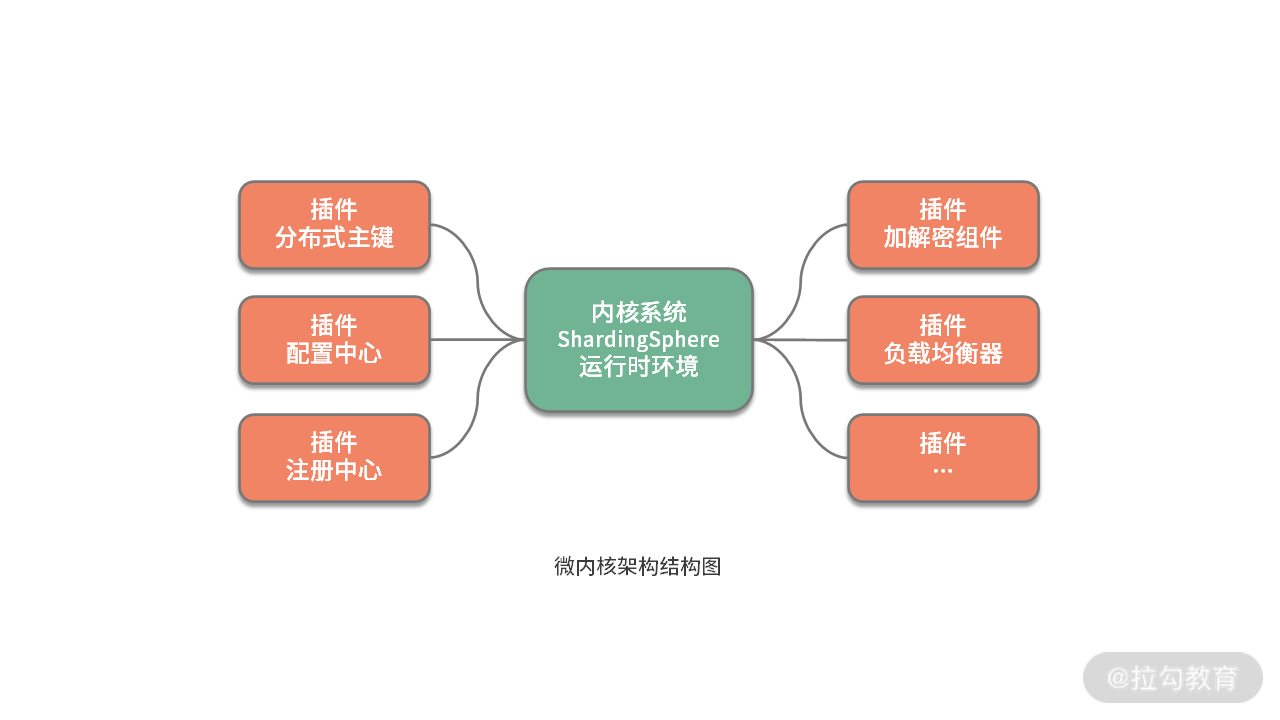
那么这里的插件具体指的是什么呢?这就需要我们明确两个概念,一个概念就是经常在说的 API ,这是系统对外暴露的接口。而另一个概念就是 SPI(Service Provider Interface,服务提供接口),这是插件自身所具备的扩展点。就两者的关系而言,API 面向业务开发人员,而 SPI 面向框架开发人员,两者共同构成了 ShardingSphere 本身。
可插拔式的实现机制说起来简单,做起来却不容易,我们需要考虑两方面内容。一方面,我们需要梳理系统的变化并把它们抽象成多个 SPI 扩展点。另一方面, 当我们实现了这些 SPI 扩展点之后,就需要构建一个能够支持这种可插拔机制的具体实现,从而提供一种 SPI 运行时环境 。
那么,ShardingSphere 是如何实现微内核架构的呢?让我们来一起看一下。
如何实现微内核架构?
事实上,JDK 已经为我们提供了一种微内核架构的实现方式,这种实现方式针对如何设计和实现 SPI 提出了一些开发和配置上的规范,ShardingSphere 使用的就是这种规范。首先,我们需要设计一个服务接口,并根据需要提供不同的实现类。接下来,我们将模拟实现分布式主键的应用场景。
基于 SPI 的约定,创建一个单独的工程来存放服务接口,并给出接口定义。请注意 这个服务接口的完整类路径为 com.tianyilan.KeyGenerator ,接口中只包含一个获取目标主键的简单示例方法。
package com.tianyilan;
public interface KeyGenerator{
String getKey();
}
针对该接口,提供两个简单的实现类,分别是基于 UUID 的 UUIDKeyGenerator 和基于雪花算法的 SnowflakeKeyGenerator。为了让演示过程更简单,这里我们直接返回一个模拟的结果,真实的实现过程我们会在下一课时中详细介绍。
public class UUIDKeyGenerator implements KeyGenerator {
public String getKey() {
return “UUIDKey”;
}
}
public class SnowflakeKeyGenerator implements KeyGenerator {
public String getKey() {
return “SnowflakeKey”;
}
}
接下来的这个步骤很关键, 在这个代码工程的 META-INF/services/ 目录下,需要创建一个以服务接口完整类路径 com.tianyilan.KeyGenerator 命名的文件 ,文件的内容是指向该接口所对应的两个实现类的完整类路径 com.tianyilan.UUIDKeyGenerator 和 com.tianyilan. SnowflakeKeyGenerator。
我们把这个代码工程打成一个 jar 包,然后新建另一个代码工程,该代码工程需要这个 jar 包,并完成如下所示的 Main 函数。
import java.util.ServiceLoader;
import com.tianyilan. KeyGenerator;
public class Main {
public static void main(String[] args) {
ServiceLoader<KeyGenerator> generators = ServiceLoader.load(KeyGenerator.class);
for (KeyGenerator generator : generators) {
System.out.println(generator.getClass());
String key = generator.getKey();
System.out.println(key);
}
}
}
现在,该工程的角色是 SPI 服务的使用者,这里使用了 JDK 提供的 ServiceLoader 工具类来获取所有 KeyGenerator 的实现类。现在在 jar 包的 META-INF/services/com.tianyilan.KeyGenerator 文件中有两个 KeyGenerator 实现类的定义。执行这段 Main 函数,我们将得到的输出结果如下:
class com.tianyilan.UUIDKeyGenerator
UUIDKey
class com.tianyilan.SnowflakeKeyGenerator
SnowflakeKey
如果我们调整 META-INF/services/com.tianyilan.KeyGenerator 文件中的内容,去掉 com.tianyilan.UUIDKeyGenerator 的定义,并重新打成 jar 包供 SPI 服务的使用者进行引用。再次执行 Main 函数,则只会得到基于 SnowflakeKeyGenerator 的输出结果。
至此, 完整 的 SPI 提供者和使用者的实现过程演示完毕。我们通过一张图,总结基于 JDK 的 SPI 机制实现微内核架构的开发流程:
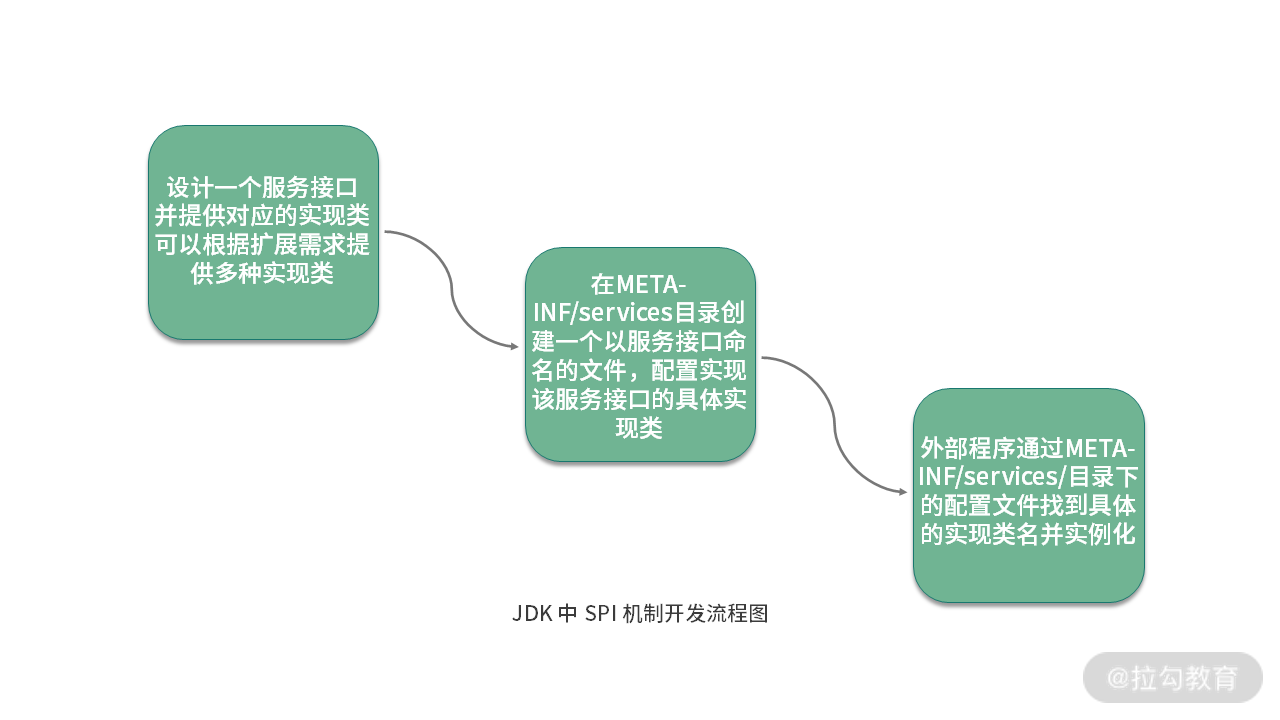
这个示例非常简单,但却是 ShardingSphere 中实现微内核架构的基础。接下来,就让我们把话题转到 ShardingSphere,看看 ShardingSphere 中应用 SPI 机制的具体方法。
ShardingSphere 如何基于微内核架构实现扩展性?
ShardingSphere 中微内核架构的实现过程并不复杂,基本就是对 JDK 中 SPI 机制的封装。让我们一起来看一下。
ShardingSphere 中的微内核架构基础实现机制
我们发现,在 ShardingSphere 源码的根目录下,存在一个独立的工程 shardingsphere-spi。显然,从命名上看,这个工程中应该包含了 ShardingSphere 实现 SPI 的相关代码。我们快速浏览该工程,发现里面只有一个接口定义和两个工具类。我们先来看这个接口定义 TypeBasedSPI:
public interface TypeBasedSPI {
//获取SPI对应的类型
String getType();
//获取属性
Properties getProperties();
//设置属性
void setProperties(Properties properties);
}
从定位上看,这个接口在 ShardingSphere 中应该是一个顶层接口,我们已经在上一课时给出了这一接口的实现类类层结构。接下来再看一下 NewInstanceServiceLoader 类,从命名上看,不难想象该类的作用类似于一种 ServiceLoader,用于加载新的目标对象实例:
public final class NewInstanceServiceLoader {
private static final Map<Class, Collection<Class<?>>> SERVICE_MAP = new HashMap<>();
//通过ServiceLoader获取新的SPI服务实例并注册到SERVICE_MAP中
public static <T> void register(final Class<T> service) {
for (T each : ServiceLoader.load(service)) {
registerServiceClass(service, each);
}
}
private static <T> void registerServiceClass(final Class<T> service, final T instance) {
Collection<Class<?>> serviceClasses = SERVICE_MAP.get(service);
if (null == serviceClasses) {
serviceClasses = new LinkedHashSet<>();
}
serviceClasses.add(instance.getClass());
SERVICE_MAP.put(service, serviceClasses);
}
public static <T> Collection<T> newServiceInstances(final Class<T> service) {
Collection<T> result = new LinkedList<>();
if (null == SERVICE_MAP.get(service)) {
return result;
}
for (Class<?> each : SERVICE_MAP.get(service)) {
result.add((T) each.newInstance());
}
return result;
}
}
在上面这段代码中, 首先看到了熟悉的 ServiceLoader.load(service) 方法,这是 JDK 中 ServiceLoader 工具类的具体应用。同时,注意到 ShardingSphere 使用了一个 HashMap 来保存类的定义以及类的实例之 间 的一对多关系,可以认为,这是一种用于提高访问效率的缓存机制。
最后,我们来看一下 TypeBasedSPIServiceLoader 的实现,该类依赖于前面介绍的 NewInstanceServiceLoader 类。 下面这段代码演示了 基于 NewInstanceServiceLoader 获取实例类列表,并根据所传入的类型做过滤:
//使用NewInstanceServiceLoader获取实例类列表,并根据类型做过滤
private Collection<T> loadTypeBasedServices(final String type) {
return Collections2.filter(NewInstanceServiceLoader.newServiceInstances(classType), new Predicate<T>() {
public boolean apply(final T input) {
return type.equalsIgnoreCase(input.getType());
}
});
}
TypeBasedSPIServiceLoader 对外暴露了服务的接口,对通过 loadTypeBasedServices 方法获取的服务实例设置对应的属性然后返回:
//基于类型通过SPI创建实例
public final T newService(final String type, final Properties props) {
Collection<T> typeBasedServices = loadTypeBasedServices(type);
if (typeBasedServices.isEmpty()) {
throw new RuntimeException(String.format("Invalid `%s` SPI type `%s`.", classType.getName(), type));
}
T result = typeBasedServices.iterator().next();
result.setProperties(props);
return result;
}
同时,TypeBasedSPIServiceLoader 也对外暴露了不需要传入类型的 newService 方法,该方法使用了 loadFirstTypeBasedService 工具方法来获取第一个服务实例:
//基于默认类型通过SPI创建实例
public final T newService() {
T result = loadFirstTypeBasedService();
result.setProperties(new Properties());
return result;
}
private T loadFirstTypeBasedService() {
Collection<T> instances = NewInstanceServiceLoader.newServiceInstances(classType);
if (instances.isEmpty()) {
throw new RuntimeException(String.format(“Invalid %s SPI, no implementation class load from SPI.”, classType.getName()));
}
return instances.iterator().next();
}
这样,shardingsphere-spi 代码工程中的内容就介绍完毕。 这部分内容相当于是 ShardingSphere 中所提供的插件运行时环境 。下面我们基于 ShardingSphere 中提供的几个典型应用场景来讨论这个运行时环境的具体使用方法。
微内核架构在 ShardingSphere 中的应用
-
SQL 解析器 SQLParser
我们将在 15 课时中介绍 SQLParser 类,该类负责将具体某一条 SQL 解析成一个抽象语法树的整个过程。而这个 SQLParser 的生成由 SQLParserFactory 负责:
public final class SQLParserFactory {
public static SQLParser newInstance(final String databaseTypeName, final String sql) {
//通过SPI机制加载所有扩展
for (SQLParserEntry each : NewInstanceServiceLoader.newServiceInstances(SQLParserEntry.class)) {
…
}
}
可以看到,这里并没有使用前面介绍的 TypeBasedSPIServiceLoader 来加载实例,而是直接使用更为底层的 NewInstanceServiceLoader。
这里引入的 SQLParserEntry 接口就位于 shardingsphere-sql-parser-spi 工程的 org.apache.shardingsphere.sql.parser.spi 包中。显然,从包的命名上看,该接口是一个 SPI 接口。在 SQLParserEntry 类层结构接口中包含一批实现类,分别对应各个具体的数据库:
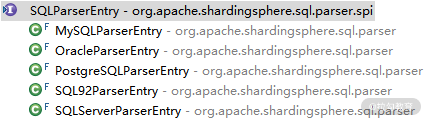
SQLParserEntry 实现类图
我们先来看针对 MySQL 的代码工程 shardingsphere-sql-parser-mysql,在 META-INF/services 目录下,我们找到了一个 org.apache.shardingsphere.sql.parser.spi.SQLParserEntry 文件:

MySQL 代码工程中的 SPI 配置
可以看到这里指向了 org.apache.shardingsphere.sql.parser.MySQLParserEntry 类。再来到 Oracle 的代码工程 shardingsphere-sql-parser-oracle,在 META-INF/services 目录下,同样找到了一个 org.apache.shardingsphere.sql.parser.spi.SQLParserEntry 文件:

Oracle 代码工程中的 SPI 配置
显然,这里应该指向 org.apache.shardingsphere.sql.parser.OracleParserEntry 类,通过这种方式,系统在运行时就会根据类路径动态加载 SPI。
可以注意到,在 SQLParserEntry 接口的类层结构中,实际并没有使用到 TypeBasedSPI 接口 ,而是完全采用了 JDK 原生的 SPI 机制。
-
配置中心 ConfigCenter
接下来,我们来找一个使用 TypeBasedSPI 的示例,比如代表配置中心的 ConfigCenter:
public interface ConfigCenter extends TypeBasedSPI
显然,ConfigCenter 接口继承了 TypeBasedSPI 接口,而在 ShardingSphere 中也存在两个 ConfigCenter 接口的实现类,一个是 ApolloConfigCenter,一个是 CuratorZookeeperConfigCenter。
在 sharding-orchestration-core 工程的 org.apache.shardingsphere.orchestration.internal.configcenter 中,我们找到了 ConfigCenterServiceLoader 类,该类扩展了前面提到的 TypeBasedSPIServiceLoader 类:
public final class ConfigCenterServiceLoader extends TypeBasedSPIServiceLoader<ConfigCenter> {
static {
NewInstanceServiceLoader.register(ConfigCenter.class);
}
public ConfigCenterServiceLoader() {
super(ConfigCenter.class);
}
//基于SPI加载ConfigCenter
public ConfigCenter load(final ConfigCenterConfiguration configCenterConfig) {
Preconditions.checkNotNull(configCenterConfig, “Config center configuration cannot be null.”);
ConfigCenter result = newService(configCenterConfig.getType(), configCenterConfig.getProperties());
result.init(configCenterConfig);
return result;
}
}
那么它是如何实现的呢? 首先,ConfigCenterServiceLoader 类通过 NewInstanceServiceLoader.register(ConfigCenter.class) 语句将所有 ConfigCenter 注册到系统中,这一步会通过 JDK 的 ServiceLoader 工具类加载类路径中的所有 ConfigCenter 实例。
我们可以看到在上面的 load 方法中,通过父类 TypeBasedSPIServiceLoader 的 newService 方法,基于类型创建了 SPI 实例。
以 ApolloConfigCenter 为例,我们来看它的使用方法。在 sharding-orchestration-config-apollo 工程的 META-INF/services 目录下,应该存在一个名为 org.apache.shardingsphere.orchestration.config.api.ConfigCenter 的配置文件,指向 ApolloConfigCenter 类:

Apollo 代码工程中的 SPI 配置
其他的 ConfigCenter 实现也是一样,你可以自行查阅 sharding-orchestration-config-zookeeper-curator 等工程中的 SPI 配置文件。
至此,我们全面了解了 ShardingSphere 中的微内核架构,也就可以基于 ShardingSphere 所提供的各种 SPI 扩展点提供满足自身需求的具体实现。
从源码解析到日常开发
在日常开发过程中,我们一般可以直接使用 JDK 的 ServiceLoader 类来实现 SPI 机制。当然,我们也可以采用像 ShardingSphere 的方式对 ServiceLoader 类进行一层简单的封装,并添加属性设置等自定义功能。
同时,我们也应该注意到,ServiceLoader 这种实现方案也有一定缺点:
-
一方面,META/services 这个配置文件的加载地址是写死在代码中,缺乏灵活性。
-
另一方面,ServiceLoader 内部采用了基于迭代器的加载方法,会把配置文件中的所有 SPI 实现类都加载到内存中,效率不高。
所以如果需要提供更高的灵活性和性能,我们也可以基于 ServiceLoader 的实现方法自己开发适合自身需求的 SPI 加载 机制。
总结
微内核架构是 ShardingSphere 中最核心的基础架构,为这个框架提供了高度的灵活度,以及可插拔的扩展性。微内核架构也是一种同样的架构模式,本课时我们对这个架构模式的特点和组成结构做了介绍,并基于 JDK 中提供的 SPI 机制给出了实现这一架构模式的具体方案。
ShardingSphere 中大量使用了微内核架构来解耦系统内核和各个组件之间的关联关系,我们基于解析引擎和配置中心给出了具体的实现案例。在学习这些案例时 ,重点在于掌握 ShardingSphere 中对 JDK 中 SPI的封装机制。
这里给你留一道思考题:ShardingSphere 中使用微内核架构时对 JDK 中的 SPI 机制做了哪些封装?
本课时的内容就到这里,下一课时,我们将继续探索 ShardingSphere 中的基础设施,并给出分布式主键的设计原理和多种实现方案,记得按时来听课。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 1
1 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)