SQL数据分析之数据提取、数据查询、数据清洗【MySQL速查】
使用SQL进行数据分析时的步骤,是常用的数据分析岗位必须具备的技能。本文主要介绍一些最基本、使用的sql在数据分析中的各种用法,包括:数据提取、数据查询、数据清洗、数据分组和连接查询。其中最重要的数据查询包括以下5个方面,1、选取数据(select)2、筛选(where)3、范围匹配(IN)4、排序(order by)5、条件筛选(case when)。
文章目录
一、数据提取
1、获得用户表、启动表与功能表
(1)用户表:用户个人信息与订单信息
(2)启动表:日期、时间等
(3)功能表:是否成功、功能、渠道、耗时等
注意:当进入数据分析岗位,需要向数据部门获得数据时必须把关键字段列出来,数据部门才会将相应字段下的数据发给我们。
2、获取数据字典(desc)
数据字典指的就是数据表中的关键字段与关键字段信息;
语法示例:desc user_info; --分号不能少;
也就是宏观查看数据字段。
二、数据查询
1、选取数据(select)
(1)语法示例:select * from user_info; --选取用户信息表中的所有数据
以上的*代表所有内容,关于SQL语句的具体语法规则与详细分析,请参阅:
MySQL数据库基础(数据表的SELECT操作)
(2)查询特定行数(limit)
语法示例:select * from user_info limit 10; --查看数据表前10行数据,无排序
2、筛选(where)
(1)语法结构:select 字段名 from 表名 where 筛选条件;
(2)精准匹配:>、<、=、>=、<=
(3)单条件筛选:
select * from d_function where if_install='install';
--从功能表中找出所有软件已经安装的行
(4)筛选的逻辑操作符:AND表示且(两真才真),OR表示或(一真即真)
(5)多条件筛选:
select * from d_function where if_install='install' AND date='2022-4-15';
--从功能表中找出条件为软件已安装 且 日期为2022年4月15日的行
(6)注意:当在MySQL中同时用到AND和OR时,AND的执行优先级高于OR。也就是说,在没有小括号()的限制下,总是优先执行AND语句,再执行OR语句。因此,条件很多时为了防止弄混,建议加上小括号()进行优先级限制。
(7)having的用法
①having和where的区别:
having对分组过后的数据进行过滤(而where是分组之前的),不过能用where的地方都可以用having替换
②having用法示例:
--用name分组过后,求每一组jquery的成绩总和,最后筛选jQuery成绩总和大于150的成绩对应的name
select name, sum(jQuery) from ExamResult group by name having sum(jQuery)>150;
--统计JS成绩大于80的name的个数
select count(name) from ExamResult where JavaScript>80;
--计算所有name的JS平均分:JavaScript总分/name个数
select sum(JavaScript)/count(name) from ExamResult;
(8)逻辑运算符
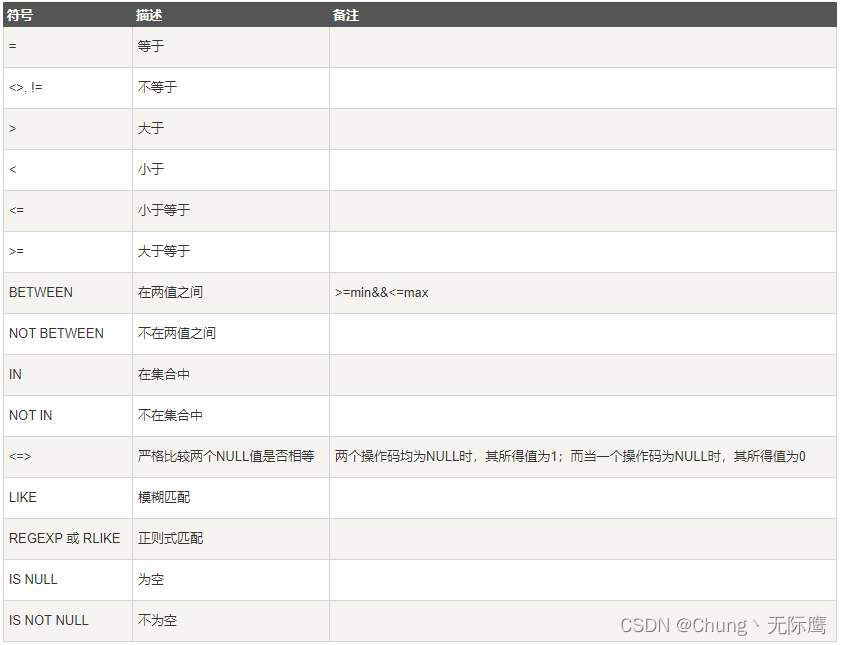
3、范围匹配(IN)
(1)作用:让SQL能返回某个变量部分指定值的结果
(2)格式:IN(值1,值2,值…值n),满足任一值,即满足了where的筛选条件
(3)语句示例(IN实现):
select * from d_function where if_install IN ('install','uninstall') AND date='2022-4-15';
--从功能表中找出所有满足“已安装或未安装,且日期未2022年4月15日”的行
(4)上述示例的OR实现:
select * from d_function where (if_install='install' OR if_install='uninstall') AND date='2022-4-15';
--从功能表中找出所有满足“已安装或未安装,且日期未2022年4月15日”的行
通过对比可以发现,IN实现就是OR的简便写法,当有很多个条件需要进行OR筛选时,则可以都放进IN的参数中进行条件判断。
4、排序(order by)
(1)作用:将特定字段进行排序
(2)语法结构:select 字段名 from 表名 order 字段名;
(3)默认是升序排序,加上desc则为降序
(4)在已安装软件中按照日期进行降序排序:
select * from d_function
where if_install='install'
order by date desc;
5、条件筛选(case when)
(1)作用:根据是否满足语句中的判断条件选取不同的取值,可以对数据进行重新分类、整理和命名。
(2)语法结构:
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
ELSE 默认结果
END
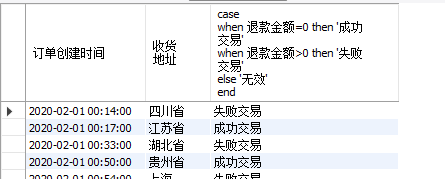
(3)筛选成功交易和失败交易的所有订单创建时间和收货地址:
select 订单创建时间,收货地址,
case
when 退款金额=0 then '成功交易'
when 退款金额>0 then '失败交易'
else '无效'
end
from 天猫订单;
注意:这里的case…when筛选语句是在select下面的,因此筛选结果会将case…when的筛选结果新建一列进行显示。
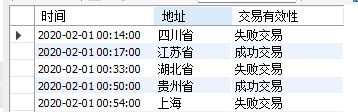
(4)AS变量重命名
主要用于分组之后进行命名。
如将上面示例中case…when筛选的结果列命名为交易有效性,订单创建时间命名为 时间,收货地址命名为地址:
select 订单创建时间 AS 时间,收货地址 AS 地址,
case
when 退款金额=0 then '成功交易'
when 退款金额>0 then '失败交易'
else '无效'
end AS 交易有效性
from 天猫订单;
三、数据清洗
1、主要工作
检查数据异常、使用代码进行数据清洗,也就是常用的增(insert)、删(delete)、改(update),其中insert较少使用,实际工作中是根据< CheckList >中的要求进行数据清洗。
2、update更新表中具体字段信息
(1)语法结构:update 表名 set 字段=‘更新内容’ where 条件;
(2)用处:当数据非常多、不清楚正确值时,就可以使用delete将异常值删除
(3)操作步骤:
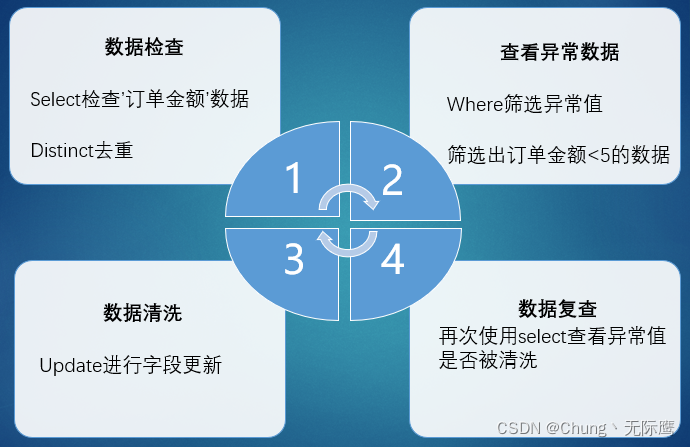
(4)代码示例:
#数据检查
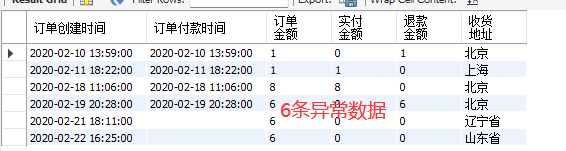
select DISTINCT 订单金额 from 天猫订单;
#查看异常数据
select * from 天猫订单 where 订单金额<10;
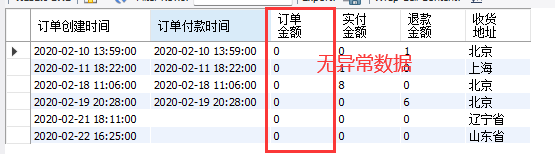
#使用update进行字段更新:将异常数据改为0
update 天猫订单 set 订单金额=0 where 订单金额<10;
#数据复查
select DISTINCT 订单金额 from 天猫订单; #所有数据检查
select * from 天猫订单 where 订单金额<10; #是否存在异常
(5)注意
执行update时可能遇到的问题:
Error Code: 1175. You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column To disable safe mode, toggle the option in Preferences -> SQL Editor and reconnect.
报错原因:现在是在mysql的safe-updates模式中,如果where后跟的条件不是主键,就会出现这种错误。
解决方案1:在where后面加上主键的条件;
解决方案2:改模式:执行SET SQL_SAFE_UPDATES = 0; 建议改模式,简单快捷。
3、delete删除表中具体字段信息
(1)语法结构:delete from 表名 where 条件;
(2)用处:当知道正常值、删除异常值对数据整体有影响时,需要使用update进行更新,不影响正常值
(3)清洗掉id长度异常的值
#检查id长度是否异常
select DISTINCT length(user_id) from user_info; #数据检查
select * from user_info where length(user_id)=29; #查看异常值:异常长度29
delete from user_info where length(user_id)=29; #数据清洗
select DISTINCT length(user_id) from user_info; #数据复查
四、数据分组
1、GROUP BY语句
可以实现按照特定字段包含的分类进行进行 汇总计算 的效果;
如:求最小值,最大值,平均值,求和等。
2、语法结构
select 函数名(字段名) from 表名 GROUP BY 字段名;
3、求交易成功的不同<付款日期>的<订单量>和<实付金额>,即日销售额,并按<付款日期>降序排序:
#查看交易成功的订单量,即不发生退款的订单量
select count(实付金额) from t1.order where 退款金额=0;
#求交易成功的不同<付款日期>的<订单量>和<实付金额>,即日销售额,并按<付款日期>降序排序
select 订单付款日期 AS 日期,count(实付金额) AS 订单量,sum(实付金额) AS 日销售额
from t1.order
where 退款金额=0
group by 订单付款日期
order by 订单付款日期 desc;
4、注意SQL语句的顺序:
select…
from…
where…
group by…
order by…
五、连接查询
1、join连接概念
SQL join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。连接查询是另一种类型的多表查询。连接查询对多个表进行JOIN运算,简单地说,就是先确定一个主表作为结果集,然后,把其他表的行有选择性地“连接”在主表结果集上。
JOIN语句可将两张数据表进行拼接查询,一般的连接字段都是主键,常为各种编号。
最常用三种连接:JOIN 、LEFT JOIN、RIGHT JOIN
2、语法结构
select 字段1
from 表1
JOIN 表2
ON 表1.字段3=表2.字段3
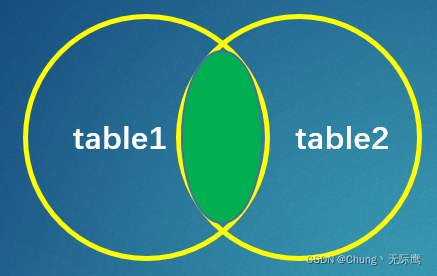
3、内连接(inner join 或 join)
内连接是等值连接,它使用“=、>、<、<>”等运算符根据每个表共有的列的值匹配两个表中的行。
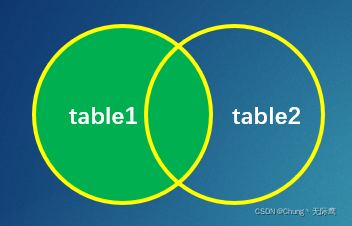
4、左连接(left join 或 left outer join)
左连接又称左向外连接,查询的结果集包括SQL语句中左表的所有行,右表中匹配的行。如果左表的某行在右表中没有匹配行,则用空值表示
5、右连接(right join 或 right outer join)
右连接也成右向外连接,查询的结果集包括SQL语句中右表的所有行,左表中匹配的行。如果右表的某行在左表中没有匹配的行,则用空值表示
6、完全外连接(full join 或 full outer join)
完全外连接,查询的结果集包括SQL语句中左表和右表的所有行。如果某行在另一个表中没有匹配行时,则用空值表示。
7、补充:JOIN中的ON和where的区别
(1)on条件是在生成临时表时候使用的,先做笛卡尔乘积生成临时表1,按照on条件生成临时表2,再添加左表中 ON 子句过滤时完全未匹配到的行,最终形成查询结果;
(2)where条件是在临时表(已经on,left join之后)生成好之后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)