
图神经网络(三)—GAT-pytorch版本代码详解
GCN代码详解-pytorch版本1 GAT基本介绍2 代码解析2.1 导入数据2.2 GAT模型框架2.3 评估与训练参考资料写在前面…在研究生的工作中使用到了图神经网络,所以平时会看一些与图神经网络相关的论文和代码。写这个系列的目的是为了帮助自己再理一遍算法的基本思想和流程,如果同时也能对其他人提供帮助是极好的~博主也是在学习过程中,有些地方有误还请大家批评指正!github: https:/
写在前面…
在研究生的工作中使用到了图神经网络,所以平时会看一些与图神经网络相关的论文和代码。写这个系列的目的是为了帮助自己再理一遍算法的基本思想和流程,如果同时也能对其他人提供帮助是极好的~博主也是在学习过程中,有些地方有误还请大家批评指正!
- github: https://github.com/OuYangg/GNNs
1 GAT基本介绍
- 论文标题:Graph attention networks
- 作者:Petar V., Guillem C., Arantxa C., Adriana R., Pietro L., Yoshua B.
注意力机制在机器翻译、机器阅读等领域取得了巨大的成功。基于注意力机制的GCN为不同的邻居赋予不同的权重。
GAT将注意力机制应用在了propagation step,通过关注每个节点的一阶邻居来生成节点的隐藏层状态,其前向传播公式如下
h
v
t
+
1
=
p
(
∑
u
∈
N
v
a
v
u
W
h
u
t
)
,
h^{t+1}_v = p(\sum_{u \in N_v}a_{vu}Wh^t_u),
hvt+1=p(u∈Nv∑avuWhut),
a
v
u
=
e
x
p
(
L
e
a
k
y
R
e
L
U
(
a
T
[
W
h
v
∣
∣
W
h
u
]
)
)
∑
k
∈
N
v
e
x
p
(
L
e
a
k
y
R
e
L
U
(
a
T
[
W
h
v
∣
∣
W
h
k
]
)
)
a_{vu}=\frac{exp(LeakyReLU(a^T[Wh_v || Wh_u]))}{\sum_{k \in N_v}exp(LeakyReLU(a^T[Wh_v || Wh_k]))}
avu=∑k∈Nvexp(LeakyReLU(aT[Whv∣∣Whk]))exp(LeakyReLU(aT[Whv∣∣Whu]))
其中,
W
W
W为参数矩阵,
a
a
a为每个GAT层的参数向量,即注意力系数向量。GAT利用多头注意力来使学习过程变得稳定,其使用K个独立的注意力头矩阵来计算隐藏层,接着将其特征进行组合
h
v
t
+
1
=
∣
∣
k
=
1
K
σ
(
∑
u
∈
N
v
a
v
u
k
W
k
h
u
t
)
,
h^{t+1}_v =||_{k=1}^{K} \sigma(\sum_{u \in N_v}a^k_{vu}W_kh^t_u),
hvt+1=∣∣k=1Kσ(u∈Nv∑avukWkhut),
h
v
t
+
1
=
σ
(
1
K
∑
k
=
1
K
∑
u
∈
N
v
a
v
u
k
W
k
h
u
t
)
h^{t+1}_v =\sigma(\frac{1}{K} \sum_{k=1}^K\sum_{u \in N_v}a^k_{vu}W_kh^t_u)
hvt+1=σ(K1k=1∑Ku∈Nv∑avukWkhut)
特点:1)节点-邻居对的计算是并行的,所以有较高的效率;2)可用于具有不同度值的节点;3)可用于inductive学习。这个多头其实可以理解为从不同的角度来量化一阶邻居节点对于目标节点的贡献。
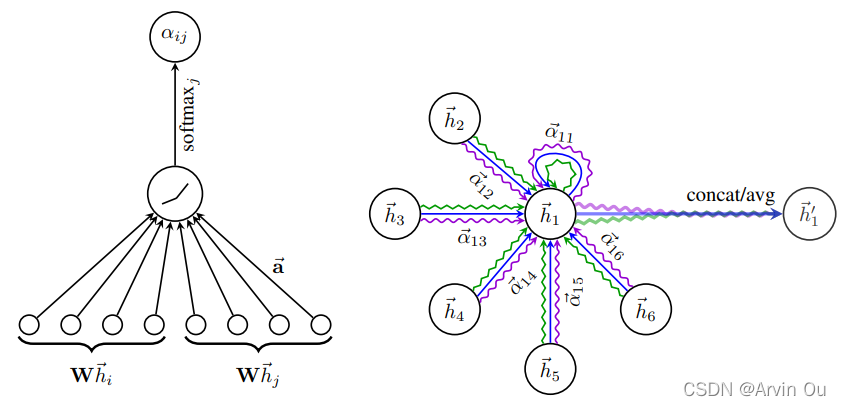
下图左为注意力系数计算可视化,下图右为多头GAT层的前向传播可视化。
2 代码解析
- 代码参考地址:pyGAT
- 导入所需的库
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import argparse
import numpy as np
import random
import scipy.sparse as
2.1 导入数据
def encode_onehot(labels):
classes = set(labels)
classes_dict = {c: np.identity(len(classes))[i, :] for i, c in
enumerate(classes)}
labels_onehot = np.array(list(map(classes_dict.get, labels)),
dtype=np.int32)
return labels_onehot
def normalize_adj(mx):
"""Row-normalize sparse matrix"""
rowsum = np.array(mx.sum(1))
r_inv_sqrt = np.power(rowsum, -0.5).flatten()
r_inv_sqrt[np.isinf(r_inv_sqrt)] = 0.
r_mat_inv_sqrt = sp.diags(r_inv_sqrt)
return mx.dot(r_mat_inv_sqrt).transpose().dot(r_mat_inv_sqrt)
def normalize(mx):
"""Row-normalize sparse matrix"""
rowsum = np.array(mx.sum(1))
r_inv = np.power(rowsum, -1).flatten()
r_inv[np.isinf(r_inv)] = 0.
r_mat_inv = sp.diags(r_inv)
mx = r_mat_inv.dot(mx)
return mx
def accuracy(output, labels):
preds = output.max(1)[1].type_as(labels)
correct = preds.eq(labels).double()
correct = correct.sum()
return correct / len(labels)
def sparse_mx_to_torch_sparse_tensor(sparse_mx):
"""Convert a scipy sparse matrix to a torch sparse tensor."""
sparse_mx = sparse_mx.tocoo().astype(np.float32)
indices = torch.from_numpy(
np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))
values = torch.from_numpy(sparse_mx.data)
shape = torch.Size(sparse_mx.shape)
return torch.sparse.FloatTensor(indices, values, shape)
def load_data(path="./cora/", dataset="cora"):
"""读取引文网络数据cora"""
print('Loading {} dataset...'.format(dataset))
idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset),
dtype=np.dtype(str)) # 使用numpy读取.txt文件
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32) # 获取特征矩阵
labels = encode_onehot(idx_features_labels[:, -1]) # 获取标签
# build graph
idx = np.array(idx_features_labels[:, 0], dtype=np.int32)
idx_map = {j: i for i, j in enumerate(idx)}
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset),
dtype=np.int32)
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape)
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),
shape=(labels.shape[0], labels.shape[0]),
dtype=np.float32)
# build symmetric adjacency matrix
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
features = normalize(features)
adj = normalize_adj(adj + sp.eye(adj.shape[0]))
idx_train = range(140)
idx_val = range(200, 500)
idx_test = range(500, 1500)
features = torch.FloatTensor(np.array(features.todense()))
labels = torch.LongTensor(np.where(labels)[1])
adj = torch.FloatTensor(np.array(adj.todense()))
idx_train = torch.LongTensor(idx_train)
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
return adj, features, labels, idx_train, idx_val, idx_test
2.2 GAT模型框架
class GATLayer(nn.Module):
"""GAT层"""
def __init__(self,input_feature,output_feature,dropout,alpha,concat=True):
super(GATLayer,self).__init__()
self.input_feature = input_feature
self.output_feature = output_feature
self.alpha = alpha
self.dropout = dropout
self.concat = concat
self.a = nn.Parameter(torch.empty(size=(2*output_feature,1)))
self.w = nn.Parameter(torch.empty(size=(input_feature,output_feature)))
self.leakyrelu = nn.LeakyReLU(self.alpha)
self.reset_parameters()
def reset_parameters(self):
nn.init.xavier_uniform_(self.w.data,gain=1.414)
nn.init.xavier_uniform_(self.a.data,gain=1.414)
def forward(self,h,adj):
Wh = torch.mm(h,self.w)
e = self._prepare_attentional_mechanism_input(Wh)
zero_vec = -9e15*torch.ones_like(e)
attention = torch.where(adj > 0, e, zero_vec) # adj>0的位置使用e对应位置的值替换,其余都为-9e15,这样设定经过Softmax后每个节点对应的行非邻居都会变为0。
attention = F.softmax(attention, dim=1) # 每行做Softmax,相当于每个节点做softmax
attention = F.dropout(attention, self.dropout, training=self.training)
h_prime = torch.mm(attention, Wh) # 得到下一层的输入
if self.concat:
return F.elu(h_prime) #激活
else:
return h_prime
def _prepare_attentional_mechanism_input(self,Wh):
Wh1 = torch.matmul(Wh,self.a[:self.output_feature,:]) # N*out_size @ out_size*1 = N*1
Wh2 = torch.matmul(Wh,self.a[self.output_feature:,:]) # N*1
e = Wh1+Wh2.T # Wh1的每个原始与Wh2的所有元素相加,生成N*N的矩阵
return self.leakyrelu(e)
class GAT(nn.Module):
"""GAT模型"""
def __init__(self,input_size,hidden_size,output_size,dropout,alpha,nheads,concat=True):
super(GAT,self).__init__()
self.dropout= dropout
self.attention = [GATLayer(input_size, hidden_size, dropout=dropout, alpha=alpha,concat=True) for _ in range(nheads)]
for i,attention in enumerate(self.attention):
self.add_module('attention_{}'.format(i),attention)
self.out_att = GATLayer(hidden_size*nheads, output_size, dropout=dropout, alpha=alpha,concat=False)
def forward(self,x,adj):
x = F.dropout(x,self.dropout,training=self.training)
x = torch.cat([att(x,adj) for att in self.attention],dim=1)
x = F.dropout(x,self.dropout,training=self.training)
x = F.elu(self.out_att(x,adj))
return F.log_softmax(x,dim=1)
2.3 评估与训练
def train(epoch):
t = time.time()
model.train()
optimizer.zero_grad()
output = model(features,adj)
loss_train = F.nll_loss(output[idx_train],labels[idx_train])
acc_train = accuracy(output[idx_train], labels[idx_train])
loss_train.backward()
optimizer.step()
model.eval()
output = model(features, adj)
acc_val = accuracy(output[idx_val],labels[idx_val])
loss_val = F.nll_loss(output[idx_val], labels[idx_val])
print('Epoch: {:04d}'.format(epoch+1),
'loss_train: {:.4f}'.format(loss_train.data.item()),
'acc_train: {:.4f}'.format(acc_train.data.item()),
'loss_val: {:.4f}'.format(loss_val.data.item()),
'acc_val: {:.4f}'.format(acc_val.data.item()),
'time: {:.4f}s'.format(time.time() - t))
return loss_val.data.item()
def compute_test():
model.eval()
output = model(features, adj)
loss_test = F.nll_loss(output[idx_test], labels[idx_test])
acc_test = accuracy(output[idx_test], labels[idx_test])
print("Test set results:",
"loss= {:.4f}".format(loss_test.data.item()),
"accuracy= {:.4f}".format(acc_test.data.item()))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--lr',type=float,default=0.005,help='learning rate')
parser.add_argument('--hidden',type=int,default=8,help='hidden size')
parser.add_argument('--epochs',type=int,default=1000,help='Number of training epochs')
parser.add_argument('--weight_decay',type=float,default=5e-4,help='Weight decay')
parser.add_argument('--nheads',type=int,default=8,help='Number of head attentions')
parser.add_argument('--dropout', type=float, default=0.6, help='Dropout rate (1 - keep probability).')
parser.add_argument('--alpha', type=float, default=0.2, help='Alpha for the leaky_relu.')
parser.add_argument('--patience', type=int, default=100, help='Patience')
parser.add_argument('--seed',type=int,default=17,help='Seed number')
args = parser.parse_args()
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
adj, features, labels, idx_train, idx_val, idx_test = load_data()
model = GAT(input_size=features.shape[1],hidden_size=args.hidden,output_size=int(labels.max())+1,dropout=args.dropout,nheads=8,alpha=args.alpha)
optimizer = optim.Adam(model.parameters(),lr=args.lr,weight_decay=args.weight_decay)
t_total = time.time()
loss_values = []
bad_counter = 0
best = 1000+1
best_epoch = 0
for epoch in range(1000):
loss_values.append(train(epoch))
if loss_values[-1] < best:
best = loss_values[-1]
best_epoch = epoch
bad_counter = 0
else:
bad_counter += 1
if bad_counter == args.patience:
break
print("Optimization Finished!")
print("Total time elapsed: {:.4f}s".format(time.time() - t_total))
compute_test()
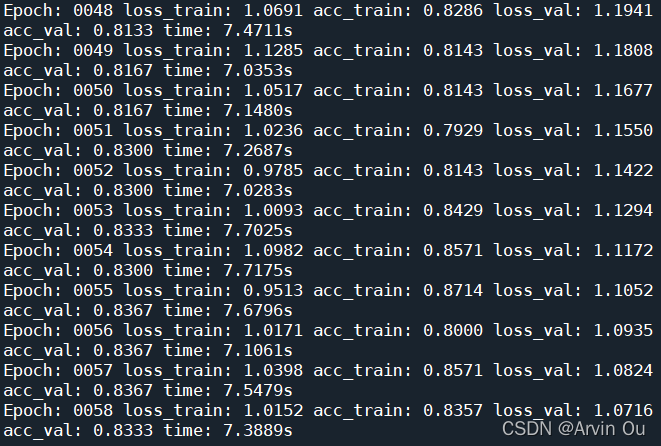
结果如下:
参考资料
[1] Graph attention networks
[2] Pytorch-GAT

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)