Flink 概述
Flink 概述Flink 的应用电商和市场营销物联网(IOT)物流配送和服务业银行和金融业流式数据处理流处理和批处理传统事务处理有状态的流处理事件驱动型(Event-Driven)应用数据分析(Data Analysis)型应用数据管道(Data Pipeline)型应用Lambda 架构FlinkFlink 的特性分层 API底层 API核心 APITable APISQLFlink vs S
·
Flink 概述
概述
Flink : 框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算
- 目标 : 数据流上的有状态计算
- 官网: https://flink.apache.org/
Flink 处理流程 :
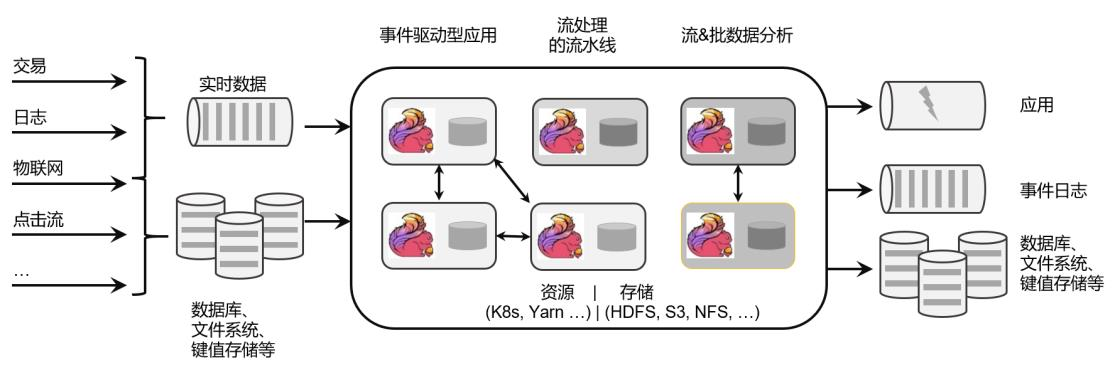
Flink 特性 :
- 高吞吐和低延迟 : 每秒处理数百万个事件,毫秒级延迟
- 结果的准确性 : 提供了事件时间(event-time)和处理时间(processing-time)语义
- 精确一次(exactly-once)的状态一致性保证
- 能连接常用的存储系统,如 : Apache Kafka、 Apache Cassandra、 Elasticsearch、JDBC、 Kinesis、 HDFS、 S3
- 高可用 : 与 K8s, YARN 和 Mesos 集成,能快速恢复和动态扩展任务的能力,做 7× 24 全天候运行
分层 API
Flink 不同级别 API :
- 底层 API : 提供有状态流,将底层处理函数 (Process Function) 嵌入 DataStream API
- 核心API : 提供通用模块,如 : 连接(joins)、聚合(aggregations)、窗口(windows)
- Table API : 表类似的操作 , 如 : select、 join、 group-by、 aggregate
- SQL : SQL 查询数据

流
- 有界数据流 : 明确了的开始和结束
- 无界数据流 : 有头没尾 , 来一条就处理一条

Flink/Spark
- 批处理领域 Spark 称王
- 流处理领域 Flink 称王
Spark : 一个通用大规模数据分析引擎。提出了内存计算,从 Hadoop 繁重的 MapReduce 程序中解脱出来
- 批处理(Spark SQL)
- 流处理(Spark Streaming)
- 机器学习(Spark MLlib)
- 图计算(Spark GraphX)
Flink :
- Flink 的延迟是毫秒级别,而 Spark Streaming 的延迟是秒级延迟
- Flink 提供了严格的精确一次性语义保证
- Flink 的窗口 API 更加灵活、语义更丰富
- Flink 提供事件时间语义,可以正确处理延迟数据
- Flink 提供了更加灵活的对状态编程的 API
点击阅读全文

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容
目录

所有评论(0)