基于MATLAB语音信号的说话人识别[声纹识别]
基于语音信号的说话人识别摘 要语音是人类相互交流和通信最方便快捷的手段。如何高效地实现语音传输存储或通过 语音实现人机交互,是语音信号处理领域中的重要研究课题。语音信号处理涉及数字信号处理、语音学、语言学、生理学、心理学、计算机科学以及模式识别、人工智能等诸多学科领域,是目前信息科学技术学科中发展最为迅速的一个领域。关键字:语音识别、清音、浊音、短时平均能量、倒谱、短时平均过零率目 录第一章 绪论
基于语音信号的说话人识别
摘 要
语音是人类相互交流和通信最方便快捷的手段。如何高效地实现语音传输存储或通过 语音实现人机交互,是语音信号处理领域中的重要研究课题。语音信号处理涉及数字信号处理、语音学、语言学、生理学、心理学、计算机科学以及模式识别、人工智能等诸多学科领域,是目前信息科学技术学科中发展最为迅速的一个领域。
关键字:语音识别、清音、浊音、短时平均能量、倒谱、短时平均过零率
目 录
第一章 绪论
1.1语音识别技术的发展历史
1.2语音识别研究的现况与难点
第二章 方案比较
第三章 软件介绍
3.1 MATLAB 介绍
3.2 GUI界面设计介绍
第四章 模块设计
4.1语音端点检测
4.1.1 原理
4.1.2 源程序
4.2短时能量
4.2.1 用途
4.2.3 问题
4.2.3 解决方法
4.2.4 程序
4.3 短时平均过零率
4.3.1 原理
4.3.2 程序
4.4 短时平均过零率
4.5 倒谱
4.6主程序
4.7 实验结果
第五章 设计中的问题
第六章 收获与体会
第七章 参考文献
第一章 绪 论
1.1 语音识别技术的发展历史
语音识别技术的研究工作开始于20世纪的50年代,第一个可以用来识别10个英文数字的语音识别系统一Audry系统是在AT&Bell实验室研制成功的。20世纪60年代,计算机的应用推动了语音识别的发展。在这个阶段主要是提出了线性预测分析(LP)和动态规划(DP),主要解决了语音信号的产生模型问题。Bell实验室的S.Pruzanskay提出了基于模式匹配和概率统计来进行语音识别,这对语音识别的发展产生了深远的影响.
20 世纪70年代,语音识别技术得到了快速发展。具体表现在:理论上,线性预测分析得到进一步的发展,动态时间弯度(DTW)技术基本成熟,特别提出了矢量量化(VQ)和隐马尔可夫模型(HMM)理论。在实践上,实现了基于线性预测倒谱和DTW技术的特定人孤立词汇的识别系统。
20世纪80年代,语音识别技术得到了进一步发展。其中显著的特征是HMM模型和人工神经网络(ANN)在语音识别中得到应用。经过AT&Bell实验室Rabiner等科学家的共同研究,把原来HMM的纯数学模型工程化,从而得到推广。经过实验证明,采用HMM和ANN模型建立的语音识别系统,性能很好。进入 20 世纪90年代,随着多媒体时代的来临,迫切需要语音识别系统从实验室走向实用。许多发达国家如美国、日本、韩国及IBM. Apple. AT&T. NTT等著名的公司都为语音识别系统的研究投入大量的资金121而 AR M 技术发展就比较迟,ARM公司成立于1990年11月,全称为Advanced
RISC Machines Ltd,它是由英国的Acorn公司提供技术支持,美国苹果等公司出资合作的美英公司。ARM公司本身不直接从事芯片生产,也不销售芯片,靠转让设计许可,由合作伙伴生产出各种特色的芯片。
1.2 语音识别研究的现况与难点
经过近50年的发展,语音识别己经发展到一个较高的水平,并从实验室走向市场,进入了一个实用化阶段。由于 矢 量 量化,HMM和人工网络等技术被用于语音信号处理,并经过不断改革与完善,使语音信号处理技术产生突破性的发展。英语的连续数字语音识别的正确率已经达到了99%以上,而具有高度混淆的英语字母的识别也达到了97%以上。目前对语音识别的研究主要是一方面对语音学的统计模型的研究,对语音段的建模方法及HMM 与人工网络。另外一方面是为了语音识别的实用化的需要,讲者自适应,听觉模型,快速搜索识别算法以及进一步语音模型的研究。语音识别研究中也存在下面几个难题:
1、 语音识别的一种重要应用是自然语言的识别和理解。这一工作要解决的问题首先是因为连续语音中的因素、音节或单词之间的调音结合引起的音变,使基本模型的边界变的不明确.其次要建立一个理解语法和语义的规则的专家系统。
2、 语音信息变化很大。语音模型不仅对不同的讲话者是不同的,而且对于同一个讲话者也是不同的。例如,同一个说话者在随便说话和认真说话时的语音信息也不同;即使同一说话者用相同的方式说话时,其语音模式也受时间的影响,即今天及一个月后,同一个说话者说相同的话时候,语音信息也不相同。
3、 语音的模糊性。说话者在讲话时,不同的语音听起来很相似。这一点不仅仅在汉语中体现,在其他语言也有说体现。
4、 在强噪声的环境下语音识别困难。语音数据都是在接近理想的条件下采集而成的,然而当语音从实验室走向实际应用时,环境噪声所带来的问题就显得越来越重要了。
第二章 方案比较及选择
方案一,基于HMM的与文本有关的说话人识别

方案二
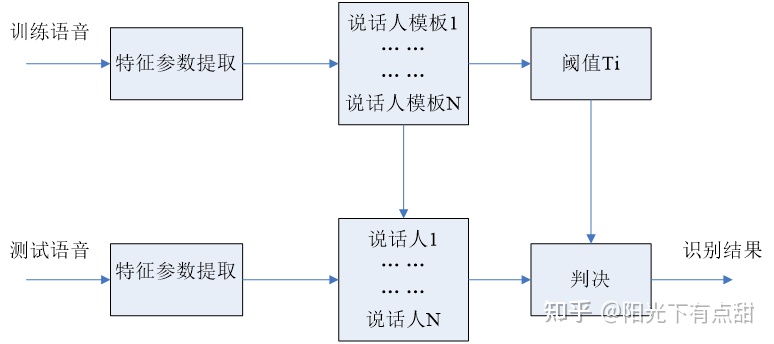
选择方案二
第三章 软件介绍
3.1 MATLAB介绍[略]
第四章 模块设计
4.1 预处理
语音信号的预处理模块一般包括预滤波、采样和量化、分帧、加窗、预加重、端点检测等。在不同的系统中对各子模块会有不同的要求,如在嵌入式语音识别系统中一般要求有防混叠滤波电路[5]、A/D转换电路和采样滤波电路等,而在计算机上实验时则可由音频采集卡完成,无需实验者亲自动手。
4.2 语音端点检测
4.2.1 原理
在语音处理中,常常涉及到语音的端点检测问题。例如在移动通信系统的语音终端中,常常要进行话音激活检测(VAD),判断当前是否有语音,若无语音输入时不编码,这样可以减少发射功率并节省信道资源。在语音识别时,特别是孤立词识别系统中,准确检测每个词的起点和终点对于模板匹配并提高识别率是相当重要的。
对要检测的语音进行分帧处理。若抽样频率为8kHz,即窗函数长度N=80。分别采用
Mn=∑|x(n)|w(n-m)和
Zn=∑{|sgn[x(n)-T]-sgn[x(n-1)-T]|+ |sgn[x(n)+T]-sgn[x(n-1)+]|}w(n-m)计算每帧语音的短时平均幅度和短时平均过门限率。由于语音一般都存在能量较高浊音段,因此考察语音的平均幅度轮廓可以设定一个较高的门限T1,使语音的起点和终点落在T1和Mn所确定的时间间隔AB之外。然后根据背景噪声的平均幅度确定一个门限较低的T2,并从A点往起点方向、从B点往终点方向搜索,分别找到与门限T2相交的两个点C、D。这样我们就用双门限完成了第一级粗判。第二级判决要利用短时平均过门限率。同样根据背景噪声的Zn可以设定一个较低的门限T3,从C和D分别向起点和终点方向搜索,可以找到与门限挺相交的两个点E、F。这样就确定出了语音的端点E、F。
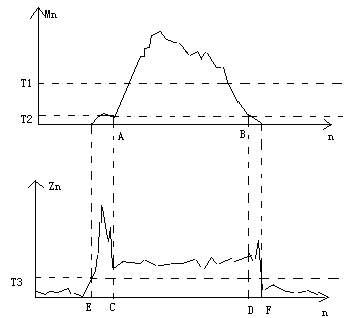
利用能量和过零的语音端点检测
4.2.2 源程序:
x1 = 0;
x2 = 0;
for n=1:length(zcr)
goto = 0;
switch status
case {0,1} % 0 = 静音, 1 = 可能开始
if amp(n) > amp1 % 确信进入语音段
x1 = max(n-count-1,1);
status = 2;
silence = 0;
count = count + 1;
elseif amp(n) > amp2 | ... % 可能处于语音段
zcr(n) > zcr2
status = 1;
count = count + 1;
else % 静音状态
status = 0;
count = 0;
end
case 2, % 2 = 语音段
if amp(n) > amp2 | ... % 保持在语音段
zcr(n) > zcr2
count = count + 1;
else % 语音将结束
silence = silence+1;
if silence < maxsilence % 静音还不够长,尚未结束
count = count + 1;
elseif count < minlen % 语音长度太短,认为是噪声
status = 0;
silence = 0;
count = 0;
else % 语音结束
status = 3;
end
end
case 3,
break;
end
end 4.3短时能量
4.3.1 用途
短时平均能量特征主要用途如下:
- 可以作为区分清音段和浊音段的特征参数。实验结果表明浊音段的能量En明显高于清音段。通过设置一个能量门限值,可以大致判定浊音变为清音或者清音变为浊音的时刻,同时也可以大致划分为浊音区间和清音区间。
- 在信噪比较高的情况下,短时能量还可以作为区分有声和无声的依据。
- 可以作为辅助的特征参数用于语音识别中。
4.3.2 问题
短时能量函数的一个主要问题是En对信号电平值过于敏感。由于需要计算信号样值的平方和,在定点实现时很容易产生溢出。
4.2.3 解决方法
为了克服这个缺点,采用以下的框图。

短时平均幅度实现框图
4.3.4 程序
amp = sum(abs(enframe(filter([1 -0.9375], 1, x), FrameLen, FrameInc)), 2);
4.4 短时平均过零率
4.4.1 原理
过零率可以反映信号的频谱特性。当离散时间信号相邻两个样点的正负号异号时,我们称为“过零率”。
短时平均过零率可以粗略估计语音的频谱特性。根据语音产生的模型可知,发浊音时,声带振动,尽管声道有多个共振峰,但由于声门波引起了频谱的高频衰落,因此浊音能量集中于3kHz以下。但是对于清音而言,由于声带不振动,由声道的某些部位阻塞气流产生类白噪声,多数能量集中在较高的频率上。高频率对应着高过零率,低频率对应着低过零率。
4.4.2 程序
tmp1 = enframe(x(1:end-1), FrameLen, FrameInc);
tmp2 = enframe(x(2:end) , FrameLen, FrameInc);
signs = (tmp1.*tmp2)<0;%相邻两帧为异号的个数
diffs = (tmp1 -tmp2)>0.02;
zcr = sum(signs.*diffs, 2);
4.5 倒谱
4.5.1 原理
以倒谱为基础的语音估计,其原理相当简单:首先计算语音的倒谱,然后在可能出现的基音周期附近寻找峰值。如果峰值超过了预先设置的门限,则输入语音段判为浊音,………
4.5.2窗函数的选择
矩形窗的主瓣宽度最小(4×PI/N)因此它具有较高的频谱分辨率,但是它的旁瓣峰值较大(-13db),因此其频谱泄漏比较严重。
4.5.3 源程序
4.5.4倒谱流程图

4.6主程序
4.6.1 源程序
disp('正在计算参考模板的参数...')
for i=1:10
fname = sprintf('%da.wav',i-1);%备注:该部分就是要录制的语音样本(0-9的数字录音)该例程中用了20个.wav格式的录音:0a.wav,1a.wav....,9a.wav,0b.wav,1b.wav......,9b.wav,分别保存了0到9的发音前10个用于参考训练,后10个作为测试。
x = wavread(fname);
[x1 x2] = vad(x);
m = mfcc(x);
m = m(x1-2:x2-2,:);
% m = m(x1:x2-4,:);
ref(i).mfcc = m;
end
disp('正在计算测试模板的参数...')
for i=1:10
fname = sprintf('%db.wav',i-1);
x = wavread(fname);
[x1 x2] = vad(x);
m = mfcc(x);
m = m(x1-2:x2-2,:);
test(i).mfcc = m;
end
disp('正在进行模板匹配...')
dist = zeros(10,10);
for i=1:10
for j=1:10
dist(i,j) = dtw(test(i).mfcc, ref(j).mfcc);
end
end
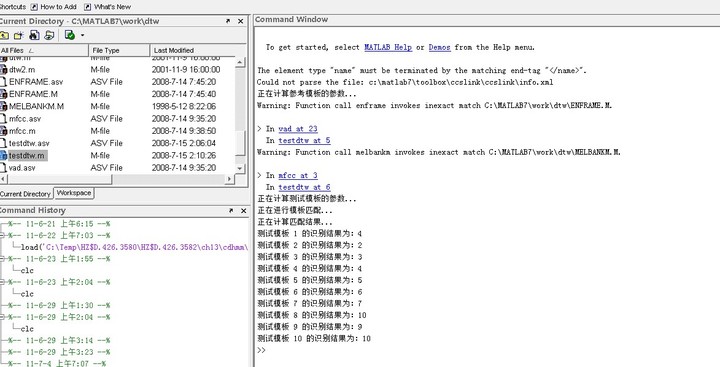
disp('正在计算匹配结果...')
for i=1:10
[d,j] = min(dist(i,:));
fprintf('测试模板 %d 的识别结果为:%d\n', i, j);
end4.6.2 试验结果
4.6.3 主程序流程图
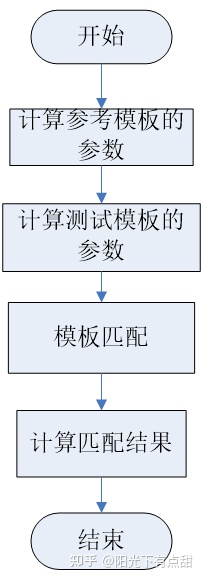
主程序流程图

4.7 实验结果
第五章 设计中的问题
5.1方案的选择
目前,用语音语音识别的方法有基于动态时轴规整(DTW)技术的模板匹配方法,基于概率统计的HMM法和基于人工神经网络(ANN)的最优搜索法。
因为本设计要求简单,又由于DTW算法本身既简单又有效,在训练中几乎不需要额为的运算,所以我们选择了DTW算法。
5.2 语音格式的选择
因为MATLAB环境只识别.WAV格式的语音信号,由于调试之前没有了解,所以在语音信号处理时-1遇到不少问题,多次犯错、且经过查阅资料才得知结论。并且语音信号要求是无损压缩的.WAV格式。通过在网上查询资料得知,Cool Edit Pro2.1软件对语音信号处理后可得到满足条件的语音信号。
第七章 参考文献
[1] 张雄伟,陈亮,杨吉斌.现代语音处理技术及应用.北京:机械工业出版社,2013.8
[2] 维纳·K·恩格尔,约翰·G·普罗克斯.数字信号处理.西安:西安交通大学出版社,2012.6
[3] 吴大正,高西全等.MATALAB及其在电子信息工程中的应用.北京:电子工业出版社,2016.3
[4] 郭仕剑,王宝顺等.MATLAB7.x数字信号处理.北京:人民邮电出版社,2016.12
[5] 易克初,田斌,付强.语音信号处理.北京:国防工业出版社,2010
[6] 杨行峻,迟惠生等.语音信号数字处理.北京:电子工业出版社.2010
[7] 袁保宗.“语音处理”、“语音增强”、“语音理解”词条,中国大百科全书(电信分册)
[8] 边肇祺,张学工等.模式识别.北京:清华大学出版社.2010.1

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)