深度学习系列(一)简介、线性回归与成本函数
机器学习系列(一)一、简介1、什么是机器学习2、机器学习的基本过程3、基本名词解释二、线性回归1、什么是回归2、用于回归的数据集3、什么是线性回归4、我们为什么要研究线性回归5、线性回归模型三、成本函数1、什么是成本函数2、成本函数Mean Square Error(MSE)Mean Absolute Error(MAE)MSE VS.MAE其他损失函数一、简介1、什么是机器学习机器学习就是一种算
机器学习系列(一)
一、简介
1、什么是机器学习
机器学习就是一种算法,这种算法可以从数据中进行学习。
这里有两个关键词,算法和数据。
算法的简单理解就是进行计算的方法,给你一个输入数据,你该如何对这个数据进行计算从而获得结果呢?这个过程其实可以很简单的用一个函数来表示,自变量是输入,因变量是结果,而这个函数式子就是我们需要的算法。
数据,我们为什么需要数据,因为学习需要有参考资料,而数据就是这个参考资料,计算机“看过”大量数据后,通过不断试错改正,拟合出了合适的方程组合以及合适的方程式中的系数。
2、机器学习的基本过程
上面在介绍概念的时候我们已经提到了,机器学习的过程需要数据这个参考资料。所以想要开发出一套适用于某个场景的机器学习系统,我们首先要做的应当是从这个场景中收集到足够多的数据以供机器进行学习。这里涉及到两个方面的问题,第一:数据收集;第二:数据预处理。这两个问题通常也是十分困扰研究人员的问题,对实验的好坏有着关键性作用。
当我们有了足够的数据进行训练之后,我们就可以设计一系列方程来作为机器学习的算法,然后根据这些方程的优劣,挑选出最合适的方程,至此一个机器学习的系统基本搭建完成。
3、基本名词解释
监督学习:这是一种通常的机器学习方式,监督的意思是说用于机器学习的数据都是有标签的(也就是说有明确的结果),因此我们可以通过不断的比较机器计算的结果与原标签比较从而来对整个学习过程起到监督作用。
半监督学习:对比于上面的监督学习,所谓的半监督学习其实就是由于数据量不足,仅有一部分用于机器学习的数据是有标签的。
无监督学习:顾名思义,就是说用于训练的数据均没有标签,或许你可能会感到疑惑,这样的情况下,我们该如何训练算法,事实上,它有其特定的应用场景,比如找出异常点或者找出洗钱活动等等。感兴趣的同学可以自己搜索了解一下。
迁移学习:迁移学习的意思是指,当我有了一个已经训练的很好的机器学习模型时,我可以将这个机器学习模型直接用于类似的场景,不需要在进行训练。
二、线性回归
1、什么是回归
所谓回归其实就是将输入变量与输出变量联系起来,同时可以对新的输入变量进行预测同时理解输入对于输出的影响。
2、用于回归的数据集
在回归中,数据通常是成对 ( x n , y n ) (x_n,y_n) (xn,yn)组成的,其中 y n y_n yn是第n个结果, x n x_n xn是纬度为D的输入向量。
3、什么是线性回归
从刚才回归的例子中,我们不难推测,所谓的线性回归的意思就是说输入与输出之间的关系是线性的。符合这种关系的例子比比皆是,比如某一地区的房屋面积与房子的总价近似是一个正相关的线性关系,房子越大价格越贵。
4、我们为什么要研究线性回归
- 易于理解,使用最广泛,容易推广到非线性模型
- 最重要的是,我们可以进通过回归就学习到几乎所有的机器学习的基础概念
5、线性回归模型
简单的线性回归
- 输入数据的维度为1,我们可以得到简单的线性回归。
D = 1 D=1 D=1 y n ≈ f ( x n ) : = w 0 + w 1 x n 1 y_n \approx f(x_n) := w_0 + w_1x_{n1} yn≈f(xn):=w0+w1xn1 - 这里的 w = ( w 0 ; w 1 ) w = (w_0;w_1) w=(w0;w1)是这个模型的两个参数,他们描述了函数 f f f
多维的线性回归 D > 1 D>1 D>1
- 如果我们的输入数据具有多个维度,我们就获得了多维的线性回归。
y n ≈ f ( x n ) : = w 0 + w 1 x n 1 + . . . + w D x n D = w 0 + x n T ( w 1 . . . w D ) = : X n T ^ W ^ y_n \approx f(x_n) :=w_0+w_1x_{n1}+...+w_Dx_{nD} = w_0 + x_{n}^T\left( \begin{array}{ccc} w_1 \\ .\\ .\\ .\\ w_D \end{array} \right ) =: \hat{X_{n}^T}\hat{W} yn≈f(xn):=w0+w1xn1+...+wDxnD=w0+xnT⎝⎜⎜⎜⎜⎛w1...wD⎠⎟⎟⎟⎟⎞=:XnT^W^
三、成本函数
1、什么是成本函数
之所以有成本函数,就是为了评估参数值W是否合理。成本函数就是被用来评价学习到的参数是否合理,也可以说是我们这个模型的错误有多大。
2、成本函数
Mean Square Error(MSE)
- MSE是最流行的成本函数之一 M S E ( w ) : = 1 N ∑ n = 1 N [ y n − f w ( X n ) ] 2 MSE(w):=\frac{1}{N}\sum_{n=1}^{N}[y_n-f_w(X_n)]^2 MSE(w):=N1∑n=1N[yn−fw(Xn)]2
- 均方误差受离群值(即某一训练数据异常于其他训练数据的值)影响较大,没有很好的鲁棒性。
Mean Absolute Error(MAE)
- M A E ( w ) : = 1 N ∑ n = 1 N ∣ y n − f w ( X n ) ∣ MAE(w):=\frac{1}{N}\sum_{n=1}^{N}|y_n-f_w(X_n)| MAE(w):=N1∑n=1N∣yn−fw(Xn)∣
- 相比于MSE,MAE在面对离群值时有更好的表现
MSE VS. MAE
- 从计算机求解梯度的复杂度来说,MSE优于MAE,而且梯度是动态变化的,能较快准确到达收敛
- 从离群值的角度看,如果离群值是实际数据或重要数据,而且是应该被检测到的异常值,那么我们应该使用MSE
- 反之,如果离群值仅仅代表数据损坏或错误采样,无须给予过多关注,那么我们应该选择MAE作为损失函数。
其他损失函数
除了MSE和MAE之外,还有其他损失函数。
-
Huber loss,它是一种用于回归问题的带参损失函数。他的优点是增强平方误差损失函数对离群值的鲁棒性。
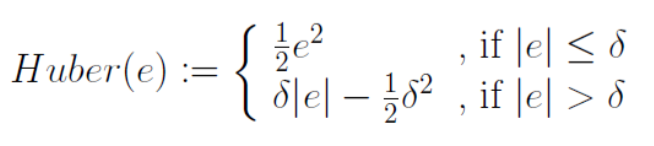
-
Tukey’s biweight损失函数,他是一种非凸损失函数,可以克服回归任务重离群值或样本噪声对整体回归模型的干扰和影响,是回归任务中一种鲁棒的损失函数。
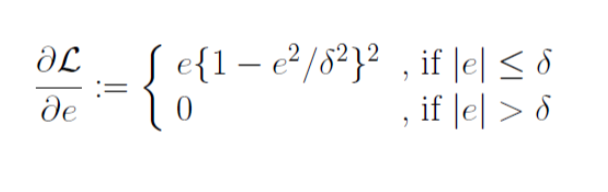

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)