

K8S核心网络插件-Flannel的部署04
k8s虽然设计了网络模型,然后将实现方式交给了CNI网络插件,而CNI网络插件的主要目的,就是实现POD资源能够跨宿主机进行通信
常见的网络插件有flannel,calico,canal,但是最简单的flannel已经完全满足我们的要求,故不在考虑其他网络插件
网络插件Flannel介绍:https://www.kubernetes.org.cn/3682.html
1 flannel功能概述
1.1 flannel运转流程
- 首先
flannel利用Kubernetes API或者etcd用于存储整个集群的网络配置,其中最主要的内容为设置集群的网络地址空间。
例如,设定整个集群内所有容器的IP都取自网段“10.1.0.0/16”。 - 接着
flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。
例如,设定本主机内所有容器的IP地址网段“10.1.2.0/24”。 - 然后
flanneld再将本主机获取的subnet以及用于主机间通信的Public IP,同样通过kubernetes API或者etcd存储起来。 - 最后
flannel利用各种backend mechanism,例如udp,vxlan等等,跨主机转发容器间的网络流量,完成容器间的跨主机通信。
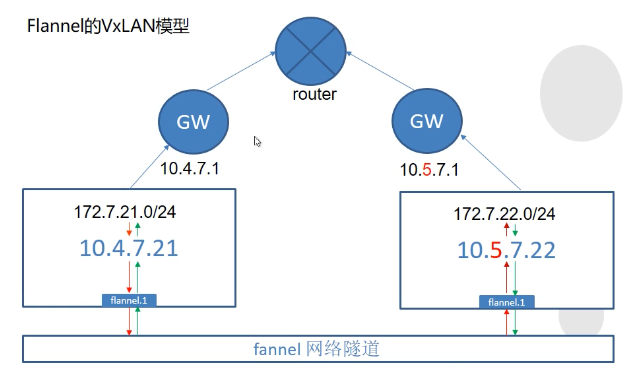
1.2 flannel的网络模型
1.2.1 flannel支持3种网络模型
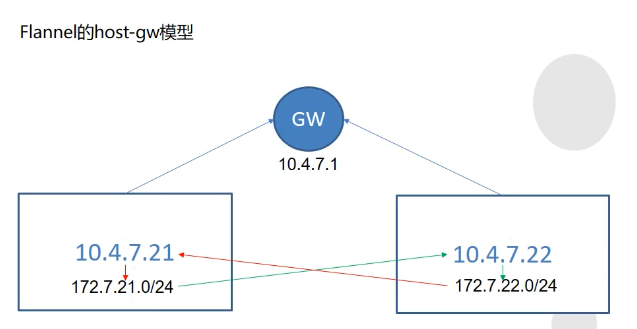
- host-gw网关模型
- {"Network": "xxx", "Backend": {"Type": "host-gw"}}
主要用于宿主机在同网段的情况下POD间的通信,即不跨网段通信.
此时flannel的功能很简单,就是在每个宿主机上创建了一条通网其他宿主机的网关路由
完全没有性能损耗,效率极高
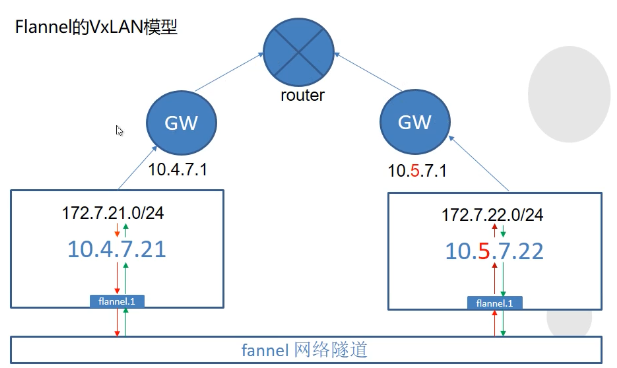
- vxlan隧道模型
- {"Network": "xxx", "Backend": {"Type": "vxlan"}}
主要用于宿主机不在同网段的情况下POD间通信,即跨网段通信.
此时flannel会在宿主机上创建一个flannel.1的虚拟网卡,用于和其他宿主机间建立VXLAN隧道
跨宿主机通信时,需要经由flannel.1设备封包、解包,因此效率不高
- 混合模型
- {"Network": "xxx", "Backend": {"Type": "vxlan","Directrouting": true}}
在既有同网段宿主机,又有跨网段宿主机的情况下,选择混合模式
flannel会根据通信双方的网段情况,自动选择是走网关路由通信还是通过VXLAN隧道通信
1.2.2 实际工作中的模型选择
很多人不推荐部署K8S的使用的flannel做网络插件,不推荐的原因是是flannel性能不高,然而
- flannel性能不高是指它的VXLAN隧道模型,而不是gw模型
- 规划K8S集群的时候,应规划多个K8S集群来管理不同的业务
- 同一个K8S集群的宿主机,就应该规划到同一个网段
- 既然是同一个网段的宿主机通信,使用的就应该是gw模型
- gw模型只是创建了网关路由,通信效率极高
- 因此,建议工作中使用flannel,且用gw模型
2. 部署flannel插件
2.1 在etcd中写入网络信息
以下操作在任意etcd节点中执行都可以
/usr/local/etcd/etcdctl set /coreos.com/network/config '{"Network": "172.7.0.0/16", "Backend": {"Type": "host-gw"}}'
# 查看结果
[root@server02 ~]# /usr/local/etcd/etcdctl get /coreos.com/network/config
{"Network": "172.7.0.0/16", "Backend": {"Type": "host-gw"}}
2.2 部署准备
2.2.1 下载软件
wget https://github.com/coreos/flannel/releases/download/v0.11.0/flannel-v0.11.0-linux-amd64.tar.gz
mkdir /usr/local/flannel-v0.11.0
tar xf flannel-v0.11.0-linux-amd64.tar.gz -C /usr/local/flannel-v0.11.0/
ln -s /usr/local/flannel-v0.11.0/ /usr/local/flannel
2.2.2 拷贝证书
因为要和apiserver通信,所以要配置client证书,当然ca公钥自不必说
cd /usr/local/flannel
mkdir cert
scp 10.11.0.210:/opt/certs/ca.pem cert/
scp 10.11.0.210:/opt/certs/client.pem cert/
scp 10.11.0.210:/opt/certs/client-key.pem cert/
2.2.3 配置子网信息
# vim /usr/local/flannel/subnet.env
FLANNEL_NETWORK=172.7.0.0/16
FLANNEL_SUBNET=172.7.207.1/24
FLANNEL_MTU=1500
FLANNEL_IPMASQ=false
注意:subnet子网网段信息,每个宿主机都要修改
2.3 启动flannel服务
2.3.1 创建flannel启动脚本
# vim /usr/local/flannel/flanneld.sh
#!/bin/sh
./flanneld \
--public-ip=10.11.0.207 \
--etcd-endpoints=https://10.11.0.207:2379,https://10.11.0.208:2379,https://10.11.0.209:2379 \
--etcd-keyfile=./cert/client-key.pem \
--etcd-certfile=./cert/client.pem \
--etcd-cafile=./cert/ca.pem \
--iface=eth0 \
--subnet-file=./subnet.env \
--healthz-port=2401
# 授权
chmod u+x /usr/local/flannel/flanneld.sh
注意:
public-ip为节点IP,注意按需修改
iface为网卡,若本机网卡不是eth0,注意修改
2.3.2 创建supervisor启动脚本
# vim etc/supervisord.d/flannel.ini
[program:flanneld]
command=/bin/bash /usr/local/flannel/flanneld.sh
numprocs=1
directory=/usr/local/flannel
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=root
redirect_stderr=true
stdout_logfile=/data/logs/flanneld/flanneld.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=4
stdout_capture_maxbytes=1MB
;子进程还有子进程,需要添加这个参数,避免产生孤儿进程
killasgroup=true
stopasgroup=true
supervisor的各项配置不再备注,有需要的看K8S二进制安装中的备注
2.3.3 启动flannel服务并验证
启动服务
mkdir -p /data/logs/flanneld
supervisorctl update
supervisorctl status
将配置好的其中一台flannel拷贝到另外一个节点,修改配置并启动即可
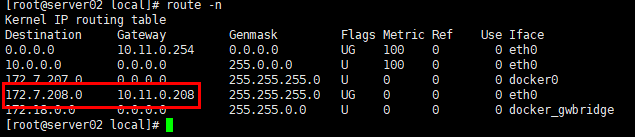
验证路由
# route -n|egrep -i '172.7|des'
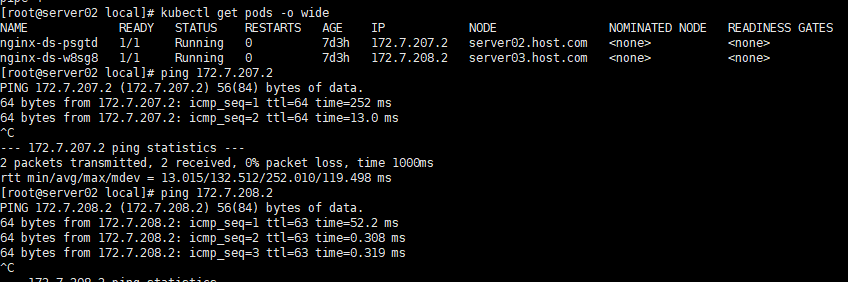
验证通信结果

架构原理:
之所以能够通信,是因为flannel添加了静态路由
实验:
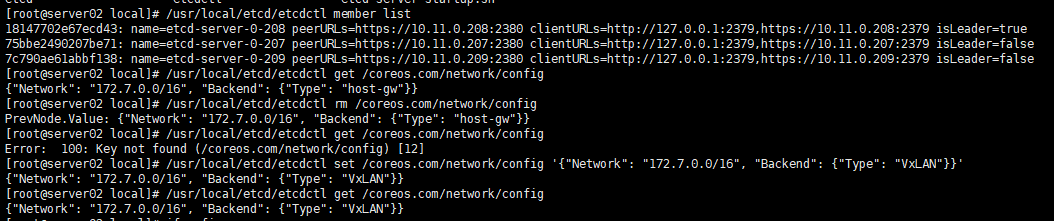
将flannel的网络模型变更为vxlan
# /usr/local/etcd/etcdctl rm /coreos.com/network/config
# /usr/local/etcd/etcdctl get /coreos.com/network/config
Error: 100: Key not found (/coreos.com/network/config) [12]
# /usr/local/etcd/etcdctl set /coreos.com/network/config '{"Network": "172.7.0.0/16", "Backend": {"Type": "VxLAN"}}'
# /usr/local/etcd/etcdctl get /coreos.com/network/config
重启flannel进程
# supervisorctl restart flanneld:*
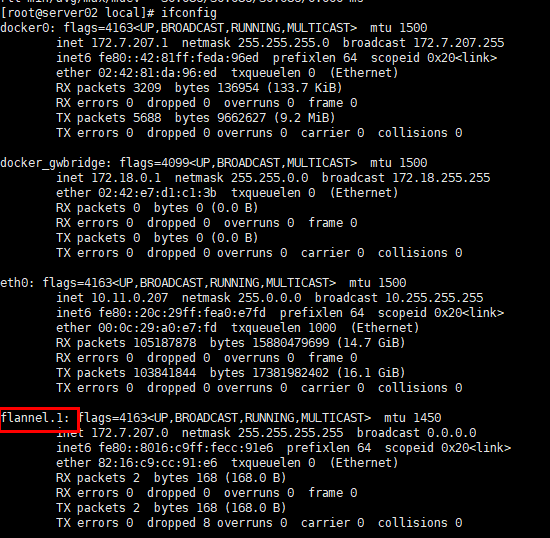
实际在操作的过程中发现在设置成vxlan以后,再次重新调整回来后网络不通了,路由什么的配置也都在,发现 flanneld1:1 这个网卡一直存在,于是重启了两台kubectl主机,然后发现etcd不通,于是 iptables -F,重启docker,再次设置 host-gw ,重启etcd,flanneld,问题解决
3 优化iptables规则
3.1 前因后果
3.1.1 优化原因说明
我们使用的是gw网络模型,而这个网络模型只是创建了一条到其他宿主机下POD网络的路由信息.因而我们可以猜想:
- 从外网访问到B宿主机中的POD,源IP应该是外网IP
- 从A宿主机访问B宿主机中的POD,源IP应该是A宿主机的IP
- 从A的POD-A01中,访问B中的POD,源IP应该是POD-A01的容器IP
此情形可以想象是一个路由器下的2个不同网段的交换机下的设备通过路由器(gw)通信
然后遗憾的是:
- 前两条毫无疑问成立
- 第3条理应成立,但实际不成立
不成立的原因是:
- Docker容器的跨网络隔离与通信,借助了iptables的机制
- 因此虽然K8S我们使用了ipvs调度,但是宿主机上还是有iptalbes规则
- 而docker默认生成的iptables规则为:
若数据出网前,先判断出网设备是不是本机docker0设备(容器网络)
如果不是的话,则进行SNAT转换后再出网,具体规则如下 - # iptables-save |grep -i postrouting|grep docker0
-A POSTROUTING -s 172.7.207.0/24 ! -o docker0 -j MASQUERADE
由于gw模式产生的数据,是从eth0流出,因而不在此规则过滤范围内
- 就导致此跨宿主机之间的POD通信,使用了该条SNAT规则
解决办法是:
- 修改此IPTABLES规则,增加过滤目标:过滤目的地是宿主机网段的流量
3.1.2 问题复现
- 在 0.207 宿主机中,访问172.7.208.2
curl 172.7.208.2
- 在 0.207 宿主中和进入容器中分别访问172.7.22.2
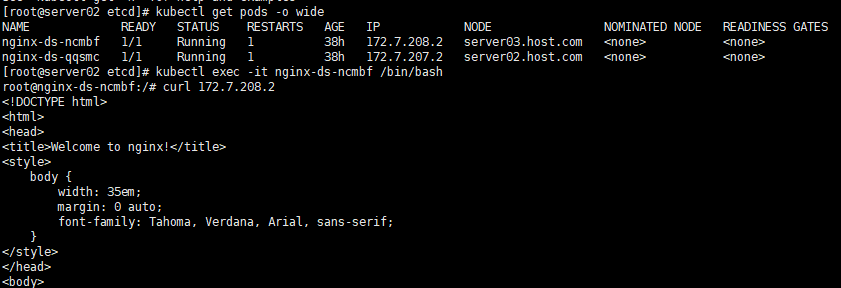
查看 0.208 宿主机上启动的nginx容器日志

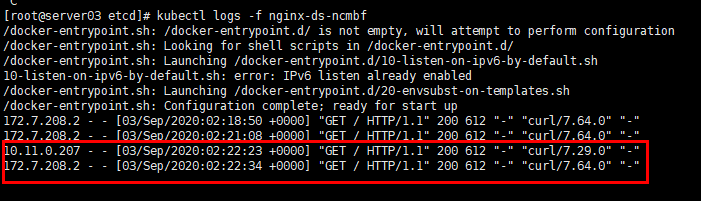
[root@server03 etcd]# kubectl logs nginx-ds-ncmbf --tail=2
10.11.0.207 - - [03/Sep/2020:02:22:23 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.29.0" "-"
172.7.208.2 - - [03/Sep/2020:02:22:34 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.64.0" "-"
第一条日志为对端宿主机访问日志
第二条日志为对端容器访问日志
可以看出源IP是宿主机的IP,和本机器中 容器 的IP地址
3.2 具体优化过程
3.2.1 先查看iptables规则
[root@server02 etcd]# iptables-save |grep -i postrouting |grep docker0
-A POSTROUTING -s 172.7.207.0/24 ! -o docker0 -j MASQUERADE

3.2.2 安装iptables并修改规则(需要在kubectl的所有节点中操作才有效)
yum install iptables-services -y
# 删除之前的规则
[root@server02 etcd]# iptables -t nat -D POSTROUTING -s 172.7.207.0/24 ! -o docker0 -j MASQUERADE
# 重新添加规则:即 如果目的是 源头是 172.7.207.0 目标是 172.7.0.0 则不作地址伪装
[root@server02 etcd]# iptables -t nat -I POSTROUTING -s 172.7.207.0/24 ! -d 172.7.0.0/16 ! -o docker0 -j MASQUERADE

# 验证规则并保存配置
[root@server02 etcd]# iptables-save | grep -i postrouting|grep docker0
-A POSTROUTING -s 172.7.207.0/24 ! -d 172.7.0.0/16 ! -o docker0 -j MASQUERADE
[root@server02 etcd]# iptables-save > /etc/sysconfig/iptables
最终的效果:容器之间互相访问的时候获取的ip是容器的内部ip,而不是伪装后的IP地址
3.2.3 注意: 如果docker重启后需要再次确保该规则生效
docker服务重启后,会再次增加该规则,要注意在每次重启docker服务后,删除该规则
验证:
修改后会影响到docker原本的iptables链的规则,所以需要重启docker服务
[root@hdss7-21 ~]# systemctl restart docker
[root@hdss7-21 ~]# iptables-save |grep -i postrouting|grep docker0
-A POSTROUTING -s 172.7.21.0/24 ! -o docker0 -j MASQUERADE
-A POSTROUTING -s 172.7.21.0/24 ! -d 172.7.0.0/16 ! -o docker0 -j MASQUERADE
# 可以用iptables-restore重新应用iptables规则,也可以直接再删
~]# iptables-restore /etc/sysconfig/iptables
~]# iptables-save |grep -i postrouting|grep docker0
-A POSTROUTING -s 172.7.21.0/24 ! -d 172.7.0.0/16 ! -o docker0 -j MASQUERADE
3.2.4 结果验证
# 对端启动容器并访问
[root@hdss7-21 ~]# docker run --rm -it busybox sh
/ # wget 172.7.22.2
# 本端验证日志
[root@hdss7-22 ~]# kubectl logs nginx-ds-j777c --tail=1
172.7.21.3 - - [xxxx] "GET / HTTP/1.1" 200 612 "-" "Wget" "-"
容器内部之间通信要看到真实的pod IP地址
安装iptables-services 服务,然后删除 reject 规则,优化伪装规则
这样就可以做到docker之间,k8s内部系统是没有做伪装的




 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)