【已解决】Python_sklearn_svm报错 ValueError: The number of classes has to be greater than one; got 1 class
网上(百度)能找到的报错答疑比较少,所以来贴个帖子。同为分享故,减少后来人的坑。运行sklearn.svm函数预测时,报错 ValueError: The number of classes has to be greater than one; got 1 class找到报错原因了,因为y只有一种可能的值,1.接下来,是要找到为什么y的赋值只有1.—— —— ——先附函数代码:```python
网上(百度)能找到的报错答疑比较少,所以来贴个帖子。同为分享故,减少后来人的坑。
运行sklearn.svm函数预测时,报错 ValueError: The number of classes has to be greater than one; got 1 class
找到报错原因了,因为y只有一种可能的值,1.
接下来,是要找到为什么y的赋值只有1.
—— —— ——
先附函数代码:
```python
data.sort_index(0,ascending=False,inplace=True)
dayfeature=150
featurenum=5*dayfeature
x=np.zeros((data.shape[0]-dayfeature,featurenum+1))
y=np.zeros((data.shape[0]-dayfeature))
for i in range(0,data.shape[0]-dayfeature):
x[i,0:featurenum]=np.array(data[i:i+dayfeature][[u'收盘价',u'最高价',u'最低价',u'开盘价',u'成交量']]).reshape((1,featurenum))
x[i,featurenum]=data.ix[i+dayfeature][u'开盘价']
for i in range(0,data.shape[0]-dayfeature):
if data.ix[i+dayfeature][u'收盘价']>=data.ix[i+dayfeature][u'开盘价']:
y[i]=1
else:
y[i]=0
clf=svm.SVC(kernel='rbf')
result = []
for i in range(5):
# x_train, x_test, y_train, y_test = cross_validation.train_test_split(x, y, test_size = 0.2)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
clf.fit(x_train, y_train)
result.append(np.mean(y_test == clf.predict(x_test)))
print("svm classifier accuacy:")
print(result)
```python
附图1:运行sklearn.svm函数预测时,报错:
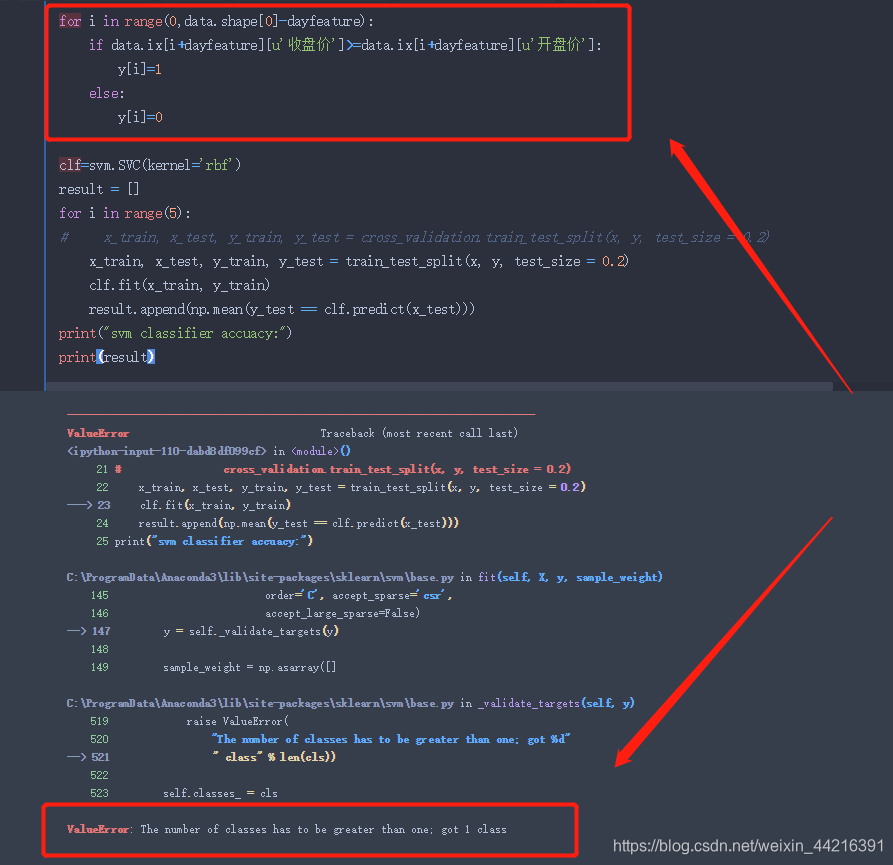
附图2:往回看 y的赋值过程及结果,y全是1.

附图3:再往回看 y的赋值来源data(见下图)
抽查了一下,还真是收盘价都大于等于开盘价。。。那就是没发现什么前后矛盾的地方,y目前为止还都是1。。。

1990年还是市场经济开始飞速发展的时候,指数直上可以理解。那我们排个序看看最近波动不停的股指。。。
然而,看最近几天的,还是收盘价>=开盘价(见下图)。突然闪过一个念头:我是不是在更新列名的时候,把收盘价和开盘价,更新成了最高价和最低价,所以,因为最高价永远>=最低价,所以更换错的收盘价也永远>=开盘价。
那接下来看看是不是这个原因。

果然,乌龙找出来了(见下图)。
列命名的时候错乱了,把最低价当成开盘价(见以下命名代码)。那就是,不管收盘价是哪个数值,都会比“最低价”高,所以y就全部是1,所以sklearn.svm模型就报错。
那接下来,把列名更新改正,重跑一遍试试。
colNameDict = {
'open':'收盘价',
'high':'最高价',
'close':'最低价',
'low':'开盘价',
'vol':'成交量'} #将‘源数据列名’改为‘新列名’

成功(下图)。


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)