分类模型评估、模型的选择与调优与决策树分类算法
模型的选择与调优1、交叉验证交叉验证过程交叉验证:将拿到的数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。2、网格搜索超参数搜索-网格搜索交叉验证是和网格搜索配合使用的:超参数搜索-网格搜索API还是拿K-近邻的代码来举例,加入了交叉验证和网格搜索:def knn
文章目录
分类模型的评估

上面我已经用了,estimator就是代表的某一个预估器,请看贝叶斯那里的代码,预测准确率的语句!!

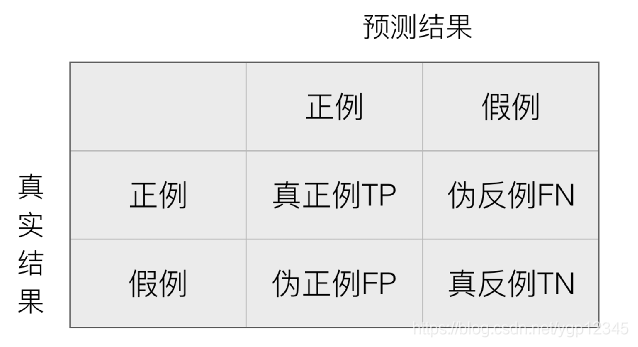
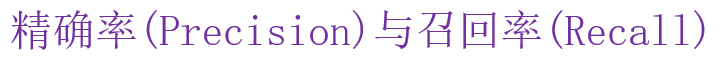
精确率:预测结果为正例样本中真实为正例的比例(查得准)
召回率:真实为正例的样本中预测结果为正例的比例(查的全,对正样本的区分能力)
举个例子:
我们通常是提高召回率,比如真实的有20个人得癌症,也就是TP+FN=20,然后我预测有10个人得癌症,那么召回率是三分之2,显然我们漏掉了10个得癌症的人,这样是不好的。于是我们提高召回率,如预测19个人得癌症,那么漏掉了一个,这样就比较好了。
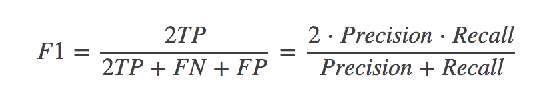



下面是精确率与召回率的API应用!
print("每个类别的精确率和召回率:", classification_report(y_test, y_predict, target_names=news.target_names))
结果如下: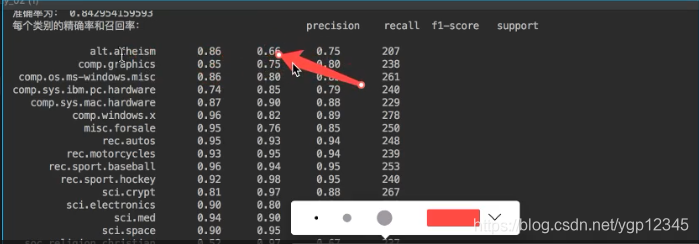
模型的选择与调优
1、交叉验证

交叉验证过程
交叉验证:将拿到的数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。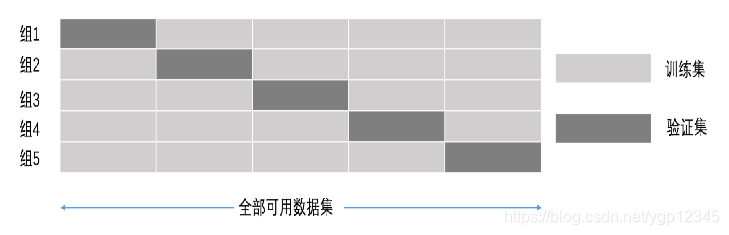
2、网格搜索
超参数搜索-网格搜索

交叉验证是和网格搜索配合使用的: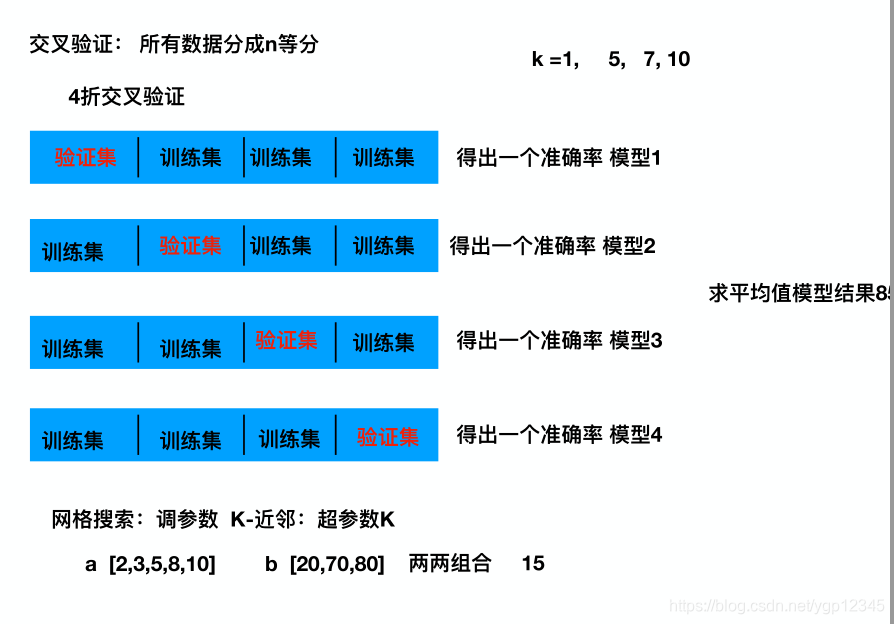
超参数搜索-网格搜索API

还是拿K-近邻的代码来举例,加入了交叉验证和网格搜索:
def knncls():
"""
K-近邻预测用户签到位置
:return:None
"""
# 读取数据
data = pd.read_csv("./data/FBlocation/train.csv")
# print(data.head(10))
# 处理数据
# 1、缩小数据,查询数据晒讯
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 处理时间的数据
time_value = pd.to_datetime(data['time'], unit='s')
print(time_value)
# 把日期格式转换成 字典格式
time_value = pd.DatetimeIndex(time_value)
# 构造一些特征
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday
# 把时间戳特征删除
data = data.drop(['time'], axis=1)
print(data)
# 把签到数量少于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'], axis=1)
# 进行数据的分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 特征工程(标准化)
std = StandardScaler()
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 进行算法流程 # 超参数
knn = KNeighborsClassifier()
# # fit, predict,score
# knn.fit(x_train, y_train)
#
# # 得出预测结果
# y_predict = knn.predict(x_test)
#
# print("预测的目标签到位置为:", y_predict)
#
# # 得出准确率
# print("预测的准确率:", knn.score(x_test, y_test))
# 构造一些参数的值进行搜索
param = {"n_neighbors": [3, 5, 10]}
# 进行网格搜索
gc = GridSearchCV(knn, param_grid=param, cv=2)
gc.fit(x_train, y_train)
# 预测准确率
print("在测试集上准确率:", gc.score(x_test, y_test))
print("在交叉验证当中最好的结果:", gc.best_score_)
print("选择最好的模型是:", gc.best_estimator_)
print("每个超参数每次交叉验证的结果:", gc.cv_results_)
return None
运行结果: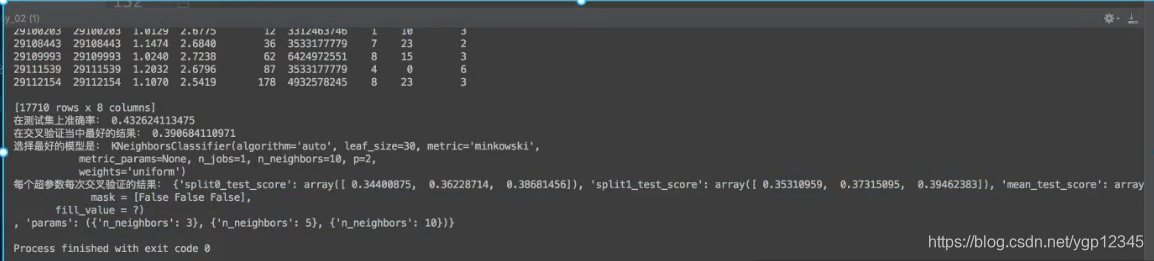
总结
网格搜索里面的cv=2表示二折交叉验证,就是把一组数据平均分成两份,一份训练集一份验证集,然后算出一组概率,然后第二轮的时候将第一轮的两个集角色互换,再算出一组概率,最后取平均值!!同理,三折,。。。n折都是这样依次角色互换,总之,验证集只需一份即可!网格搜索里面的参数列表的意思就是如k-近邻的k取哪些值??然后依次去执行,看哪个值准确率最高,如果有多个超参数,那就排列组合挨个试!!!
分类算法-决策树、随机森林
决策树

举个例子: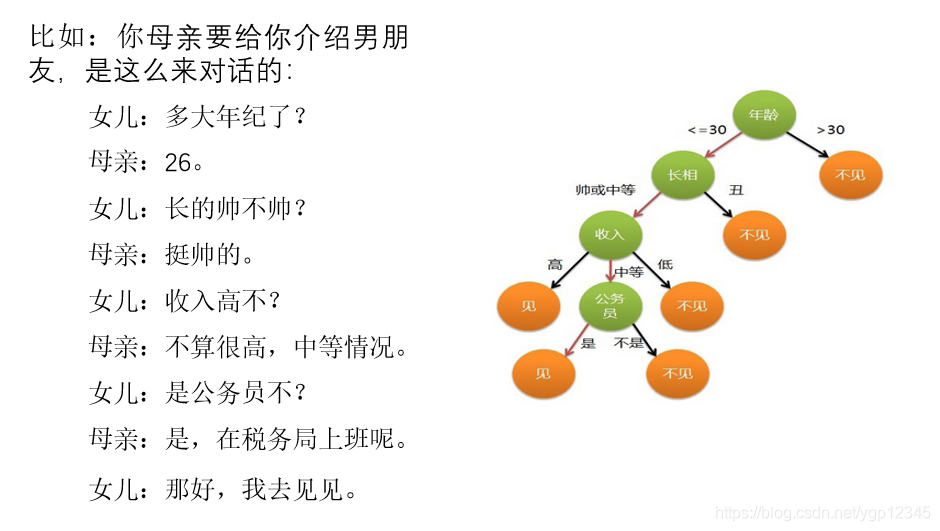
上图的对话对于人来说,每一句条件符不符合关系到下一步到底见不见?也就是我们人要通过经验来判断到底有没有必要相亲!
决策树就可以帮我们做这件事,对于相亲来说一般最重要的是年龄,我们就可以把年龄放在根节点,只要不满足,后面没得谈,满足的话再看接下来得条件!
再来个例子:银行贷款数据
像以前去贷款,都是由人通过对贷款人的信息做一个经验判断,该不该贷款,现在我们把这个事交给决策树判断。至于哪个特征重要,可由项目具体问题具体分析。比如下图所示: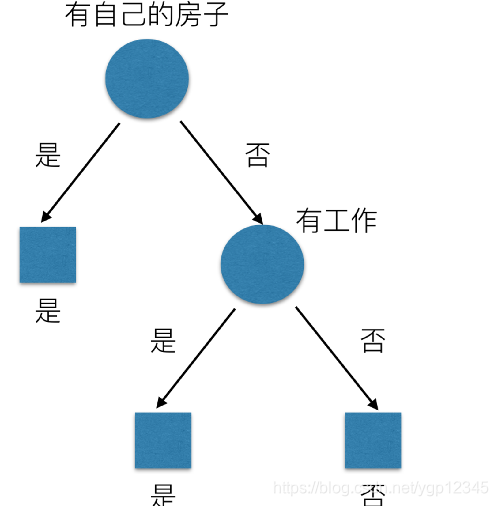
从上图可以看出,有没有房子最重要,没有房子也没关系,但要有工作才能贷款!
信息的度量和作用

猜谁是冠军?假设有32支球队,如果我没有以往的交手记录,那么32只球队获得冠军的几率将会是等价的!当我知道了越来越多的历史交手信息,那么我预测的也会越来越准!在我不知道历史交手记录的情况下,用下述方法去询问结果:


信息熵

H的专业术语称之为信息熵,单位为比特。
公式: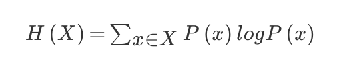
当这32支球队夺冠的几率相同时,对应的信息熵等于5比特。
我们可以看到上图如果开放了一些信息,那么信息熵肯定是小于5的,我们可以得知信息和消除不确定性是相联系的,信息越详细信息熵越小,不确定性也越小!!!、
决策树的划分依据之一-信息增益

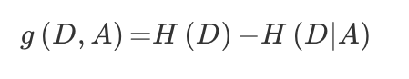
注:信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度
信息增益的计算
信息熵的计算: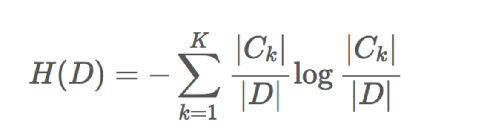

条件熵的计算: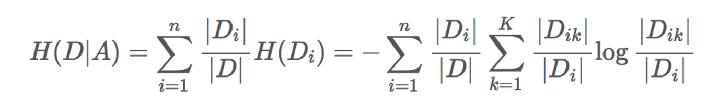
这些公式看着有些头大,我们就拿贷款的例子算一下: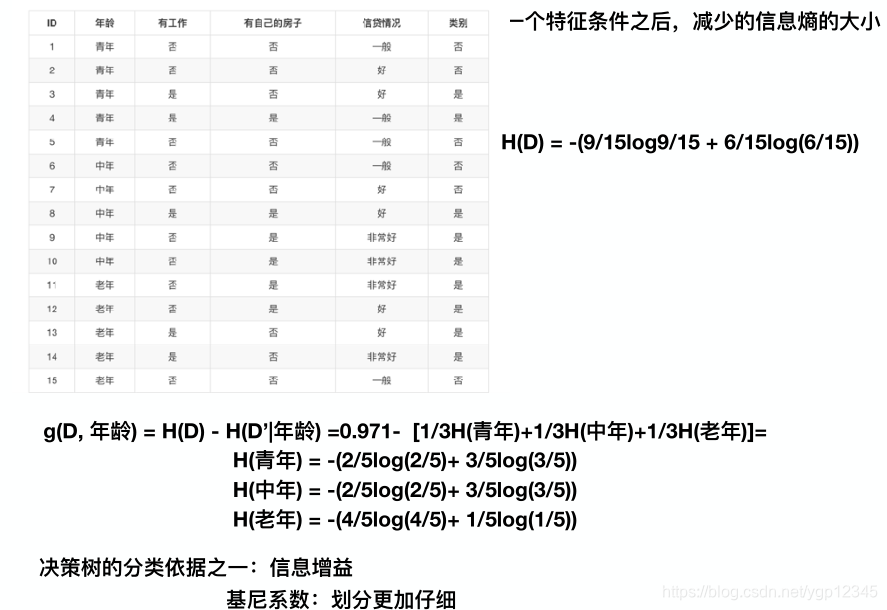

常见决策树使用的算法

决策树API:

决策树案例:预测泰坦尼克号乘客的生死

数据如下:
代码如下:
def decision():
"""
决策树对泰坦尼克号进行预测生死
:return: None
"""
# 获取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
# 处理数据,找出特征值和目标值
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
print(x)
# 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# 分割数据集到训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 进行处理(特征工程)特征-》类别-》one_hot编码
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
x_test = dict.transform(x_test.to_dict(orient="records"))
##orient="records"默认是一行一行的以字典显示
print(x_train)
# 用决策树进行预测
# dec = DecisionTreeClassifier()
#
# dec.fit(x_train, y_train)
#
# # 预测准确率
# print("预测的准确率:", dec.score(x_test, y_test))
#
# # 导出决策树的结构
# export_graphviz(dec, out_file="./tree.dot", feature_names=['年龄', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])
# 随机森林进行预测 (超参数调优)
rf = RandomForestClassifier()
param = {"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]}
# 网格搜索与交叉验证
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("准确率:", gc.score(x_test, y_test))
print("查看选择的参数模型:", gc.best_params_)
return None
结果如下: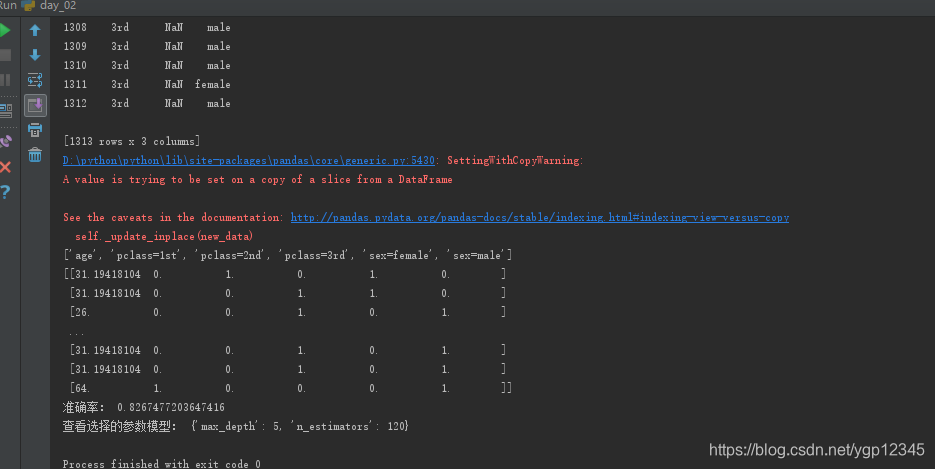
决策树的结构、本地保存

这段显示决策树结构的代码我写到上面泰坦尼克号里的,注释了。我们来看看该决策树的结构,默认是基尼系数搞得。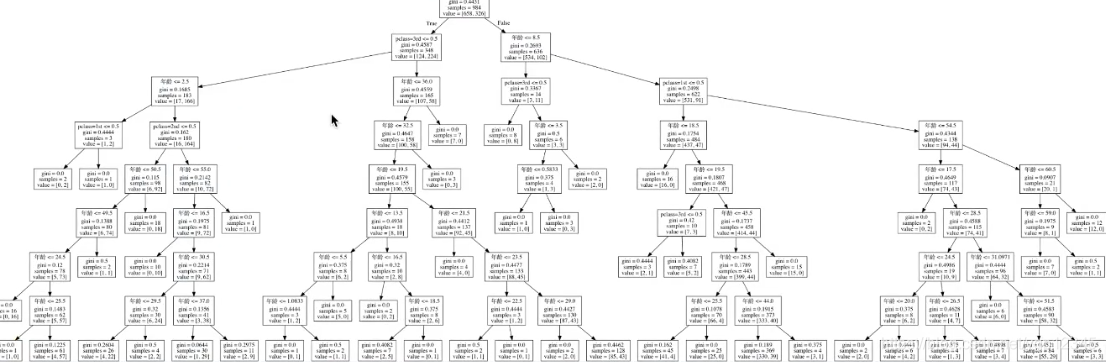
很明显,这树太复杂,基尼系数本身就会使决策很细致,这会导致训练得时候某几个异常点也会被画个分支,导致测试集不够准确!极端得例子就是一个样本就占用了一个叶子结点,这样是不对的,我怎么可能因为这一个点去走这一个分支。。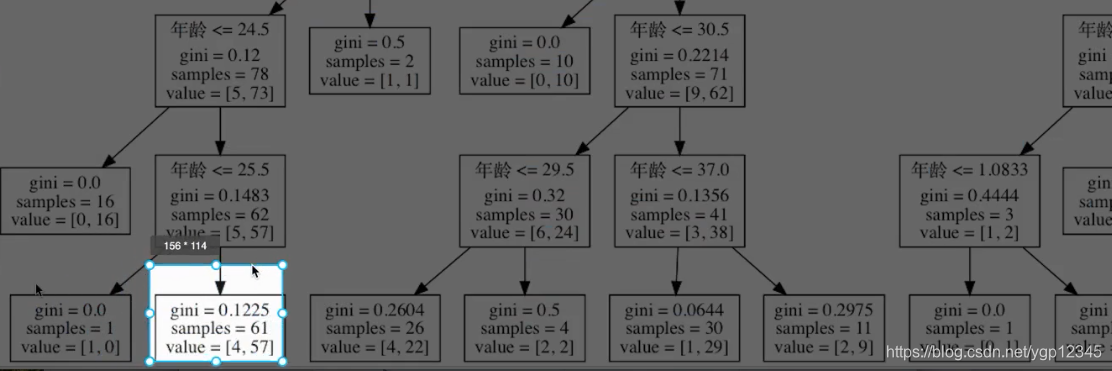
sample是样本数!!
决策树的优缺点以及改进


剪枝顾名思义就是剪去那些异常点!!
这里着重说随机森林!剪枝后面再补充
集成学习方法-随机森林

什么是随机森林




集成学习API
随机森林的优点
代码还是在泰坦尼克号那里!!

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容








所有评论(0)