语音识别 Speech recognition 中的 CTC cost,CTC损失函数(学习心得)
seq2seq 模型在语音识别方面的应用让人激动!什么是语音识别问题呢?气压随着时间推移不断变化,产生了音频人的耳朵可以衡量不同频率和强度的声波输入整个原始的音频片段 raw audio clip生成一个声谱图 generate a spectrogram(横轴是时间,纵轴是声音的频率,颜色显示声波能量的大小)伪空白输出 false blank outputs:经常用于预处理步骤,在输入到神经网络
seq2seq 模型在语音识别方面的应用让人激动!
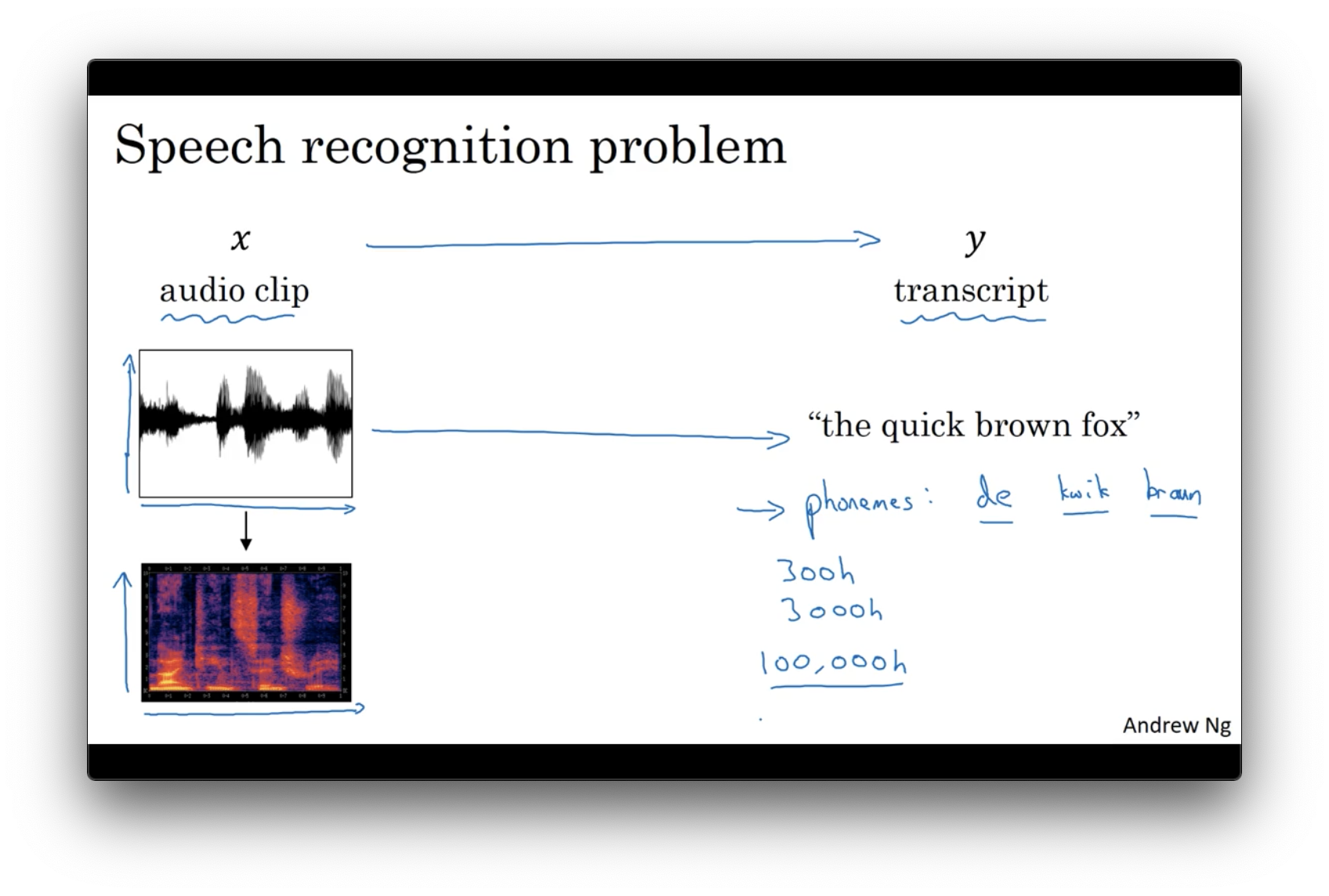
什么是语音识别问题呢?
气压随着时间推移不断变化,产生了音频
人的耳朵可以衡量不同频率和强度的声波
输入整个原始的音频片段 raw audio clip
生成一个声谱图 generate a spectrogram(横轴是时间,纵轴是声音的频率,颜色显示声波能量的大小)
- 伪空白输出 false blank outputs:经常用于预处理步骤,在输入到神经网络之前
过去一段时间,语音识别是基于音位 phonemes 来构建的
而音位是由人工设计而成 hand-engineered
但是在 end-to-end 的神经网络中,音位已经不再需要了
我们只需要一个很大的数据集
学术研究中需要 300 小时的音频,专业研究中,可能超过 3000 小时,都是合理的大小
最好的商业系统,已经训练了超过1万小时的数据,甚至超过10万,而且还在变得更大!

如何建立一个语音识别系统呢?
比如,我们可以利用注意力模型

另外一种效果不错的方法:CTC cost (利用 CTC 损失函数)
CTC:Connectionist Temporal Classification
这是由 Alex Graves, Santiago Fernandes, Faustino Gomez, Jurgen Schmidhuber 提出
假设语音片段内容是某人说的一句话
我们建立一个网络结构,输入 x 和输出 y 的数量都一样(其实就是个简单的单向 RNN,但是实践中,更可能是一个双向 LSTM 结构/ GRU 结构,并且是 deeper model)
值得注意的是,time step 在语音识别中会非常大,而且输入的时间步 要比输出大很多
比如 10 秒的音频,特征是 100 赫兹(即每秒100个样本),那一共是 1000 个输入
但是我们的输出,可能并没有 1000 个字母
这怎么处理呢?
CTC cost function 解决了这一问题
比如下面这种输出:
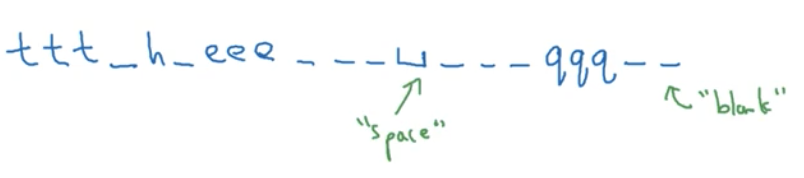
CTC 允许 RNN 生成输出空白符 blank character,上面是用下划线表示
并将空白字符间 重复的字符 折叠,得到:
t h e q the\ q the q
所以即使我们得到1000个输出,但是最终得到的文本会更短

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)