
解决二分类问题正确率始终在50%的解决办法(CatDog超详细)
一、前提:使用环境:Anaconda虚拟环境python3.6pytorch 1.4.0##主要依赖包:torch,numpy,torchvision,matplotlib,time,os,torchnet数据集:从kaggle比赛官网 下载所需的数据集DogCat,解压并把训练集和测试集分别放在一个文件夹中借鉴代码:《深度学习框架PyTorch入门与实践》 第六章编程实践 陈...
一、前提:
使用环境:
Anaconda虚拟环境
python3.6
pytorch 1.4.0
主要依赖包:
torch,numpy,torchvision,matplotlib,time,os,torchnet
数据集:
从kaggle比赛官网 下载所需的数据集DogCat,解压并把训练集和测试集分别放在一个文件夹中
借鉴代码:
《深度学习框架PyTorch入门与实践》 第六章编程实践 陈云
链接:《深度学习框架PyTorch入门与实践》
代码缺点
因为代码是几年前的,所以pytorch版本为0.4,有些方法已经废弃,需要自己稍加修改,Variable方法和变量皆已经废弃
正确率始终在50%,或者loss始终在0.69徘徊or不变
Epoch0/2
----------
train Loss: 0.7112 Acc: 53.6000
val Loss: 0.7369 Acc: 47.0000
Training time is:2m 14s
Epoch1/2
----------
train Loss: 0.7010 Acc: 55.8000
val Loss: 0.7341 Acc: 46.0000
Training time is:1m 52s
epoch:0, lr:0.001, loss:0.6992731217492435,
train_cm:[[3765 4933][4007 4795]], #一个劲瞎蒙
val_cm:[[ 0 3802][ 0 3698]] #啥都看做狗
epoch:1, lr:0.001, loss:0.6932097386834396,
train_cm:[[1382 7316] [1457 7345]], #还是瞎蒙
val_cm:[[ 0 3802] [ 0 3698]] #啥都看成狗
二、问题出现的可能原因:
- 训练数据需要打乱,要检查每此batch是否都是一个类别,如果是,则没有办法优化;
- 检查网络是不是没有回传梯度,而是只做了前向运算;
- 检查输入数据是否有做标准化,可能直接传入 0∼255 像素进去了;
- 二分类问题中 0.5 的 acc接近随机猜测的值,可以检查下标签是否标错;
- 检查参数有没有初始化;
- 检查第一层的卷积输出是否正常,是不是全 0 之类的;
- 尝试不同的 Learning Rate;
- 检查是否在 logit 那层加了激活函数,导致 logits 有问题,例如全为 0,经过 softmax后就是 0.5了
结论:一般原因都是因为没有对参数进行初始化,但是也有可能是某些低级的错误,具体筛查解决办法详情如下
三、原因筛查:
因为原始的训练集数据量庞大:训练集25000张,测试集12500张。每一次修改代码查看效果,如果实在cpu上,都需要几十分钟乃至几个小时,对于代码的debug十分不方便。所以可以自己在此数据集的基础上选取几百张制作一个类似的轻量级的数据集,并使用jupyt notebook交互式编程,可以方便找出代码的问题之处。
1. 训练数据是否shuffle
首先下载好的数据集可以发现在./train下的图片共25000张,命名方式为
cat.0.jpg至cat.12500.jpg和dog…jpg至dog.12500.jpg,代码中自定义的dataset类加载图片后增添代码:
#shuffle imgs
np.random.seed(100)
imgs = np.random.permutation(imgs)
并且在利用DataLoder加载数据集时,shuffle=True
此外还可以自定义图片查看函数,将每一个batch的图片显示出来,看看是都确实是随机采集
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
inputs, classes = next(iter(dataloaders['train']))
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
可以发现验证集的正确率还是相当于50%,输出的混淆矩阵表明:虽然实际的猫狗比例为1:1,但是预测结构要么都认为是猫,要么都是狗,完全没有训练的效果可言。
2. 梯度是否回传
是个有点深度学习基础的人都知道BP算法,所以这个问题基本上不太可能,确认代码里有这段代码:
if phase == 'train':
loss.backward()
optimizer.step()
3. 输入数据标准化
只要你的transform代码里面有这两句就没问题
self.transforms = T.Compose([
T.Resize(224),
T.CenterCrop(224),
**T.ToTensor(),** #将数据归一化到[0, 1]
normalize]) #将数据归一化到[-1, 1]
4. 检查标签是否贴错
A: label = 1 if 'dog' in img_path.split('/')[-1] else 0
B: class_names = data_image["train"].classes # 按文件夹名字分类
classes_index = data_image["train"].class_to_idx #文件夹名字对应的链值
A和B两种写法都是OK的,到这里都可以确认这四种情况都不是导致二分类问题正确率始终在50%的原因
5. 检查是否在 logit 那层加了激活函数
检查模型代码,在利用nn.Sequantial()定义不同卷积神经网络时,最后一层
nn.Linear(4096, num_classes),后面是否还跟了激活函数。一般正常代码也不会出现如此low的错误
6. 尝试不同的learning rate
A 这是在特征提取层feature layer设置较小的学习率,在分类器器层classifier layer设置较大的学习率
optimizer =optim.SGD([{'params': net.features.parameters()},
{'params': net.classifier.parameters(), 'lr': 1e-2}], lr=1e-5)
这种方式可以私人订制在某些层上面的学习率
special_layers = nn.ModuleList([net.classifier[0], net.classifier[3]])
special_layers_params = list(map(id, special_layers.parameters()))
base_params = filter(lambda p: id(p) not in special_layers_params, net.parameters())
optimizer = t.optim.Adam([
{'params': base_params},
{'params': special_layers.parameters(), 'lr': 0.01}
], lr=0.001 )
如果损失值不降反而上升,则学习率以0.95的速度递减
if loss_meter.value()[0] > previous_loss:
lr = lr * opt.lr_decay #一般取0.95
#this way minus lr: without loss of moment and other information
for param_group in optimizer.param_groups:
param_group['lr'] = lr
7.优化器Adam变为SGD
将优化器变换一下,并没有什么卵用。但是可以发现loss的值一直在0.69徘徊的原因:根据softmax的计算公式,带入数值:
-0log0.5 - 1log0.5 = 0.69
8.检查参数是否初始化
我发现我的模型就是因为参数没有教好的初始化,检查出来的原因是我利用torch官网上的Transfer learning教程,链接在此:transferLearning,正好那个教程也是二分类问题关于蜜蜂和蚂蚁的分类。所以将代码简单的修改一下,传入自己制作的轻量级的DogCat数据集,发现经过10个epoch后:
train Loss: 0.3152 Acc: 0.8580
val Loss: 0.1906 Acc: 0.9400
Training complete in 15m 42s
Best val Acc: 0.940000
而这个代码和陈云大佬的代码最大的区别就是,此代码利用了fine tune,加载预训练好的模型结构和参数,只对最后一层全连接层的输出类别进行简单的更改,变为实际训练集的class_num即可。
在pytorch中,不同类型的layers的weight和bias的初始化都是有对应公式的,这一点可以在官方手册上查看,可以发现每一层也进行了较为科学的权重初始化。以卷积层为例:

全连接层:

此外,我也在原代码上尝试了对模型的linear layer的weight进行初始化,代码如下,在加载完模型后进行。然而还是没有什么卵用???
# 对本篇文章二分类模型的所有参数进行初始化
from torch.nn import init
for name, params in net.named_parameters():
if (name.find('classifier') != -1) and (name.find('weight') != -1): #如果字符串没有包含指定的子字符串就返回-1
nn.init.kaiming_normal_(params, mode='fan_out', nonlinearity='relu')#何凯明正态分布
#以下为与本文无关的一些初始化方法,分享给大家:
# 利用nn.init初始化
from torch.nn import init
linear = nn.Linear(3, 4)
t.manual_seed(1) # 等价于 linear.weight.data.normal_(0, std)
init.xavier_normal_(linear.weight)
# 直接初始化
import math
t.manual_seed(1)
# xavier初始化的计算公式
std = math.sqrt(2)/math.sqrt(7.)
linear.weight.data.normal_(0, std)
# 对模型的所有参数进行初始化
for name, params in net.named_parameters():
if name.find('linear') != -1: # init linear
params[0] # weight
params[1] # bias
elif name.find('conv') != -1:
pass
elif name.find('norm') != -1:
pass
此时我决定把fine tune的参数和自己网络结构的参数打印出来,进行对比分析。代码参考《PyTorch提取中间层的特征(Resnet)》
以具体一张图片为代表,查看模型初始化参数对其影响,应尽量确保transform对图像的作用一致,具体查看了以下参数层: [“conv1”, “layer1”, “avgpool”, “fc”],以conv1为例,从图中可以发现权重值有较大的差异。对于全连接层fc,fine tune的模型输出为[[-1.4247, 0.4660]],而自己构建的模型为[[ 1.0413, -0.0841]]看起来好像没有什么差别。
from PIL import Image
# 中间层特征提取
class FeatureExtractor(nn.Module):
def __init__(self, submodule, extracted_layers):
super(FeatureExtractor, self).__init__()
self.submodule = submodule
self.extracted_layers = extracted_layers
# 自己修改forward函数
def forward(self, x):
outputs = []
for name, module in self.submodule._modules.items():
if name is "fc":
x = x.view(x.size(0), -1)
x = module(x)
if name in self.extracted_layers:
outputs.append(x)
return outputs
extract_list = ["conv1", "layer1", "avgpool", "fc"]
img_path = "./cat.jpg"
img = Image.open(img_path)
img = data_transforms['train'](img)
saved_path = "./cat1.txt"
x = torch.Tensor(torch.unsqueeze(img, dim=0).float()) #[1, 3, 224, 224]
extract_result = FeatureExtractor(model_ft, extract_list)
print(extract_result(x)[0]) # [0]:conv1 [1]:layer1 [2]:avgpool [4]:fc
![对于与训练好的模型,参数在[-1, 1]之间较为均匀的分布](https://img-blog.csdnimg.cn/20200304001552795.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ0NzIyMTc0,size_16,color_FFFFFF,t_70)

四、其他结论
1. Adam和SGD对二分类正确率影响很大
在同一份代码,使用resnet18为预加载的模型的transfer learning中,只对使用的优化方法进行了修改,在使用Adam,lr=1e-3的情况下,迭代10次,验证集最高准确率73%
train Loss: 0.5770 Acc: 0.7180
val Loss: 0.5081 Acc: 0.7300
而在使用SGD的优化算法下,可以达到96%,
train Loss: 0.3379 Acc: 0.8420
val Loss: 0.1662 Acc: 0.9600
为什么有这么大的差别,照理说Adam应该是万能的,是SGD的改进版本。解释链接:一文看懂各种神经网络优化算法
2. pytorch交叉熵损失计算方式和常规不同
我怎么感觉pytorch里面计算交叉熵损失函数并没有用到onehot编码。
从官方手册对其描述,可以发现要求输入的inputs.size(batch_size, class_num),target.size(batch_size)。实际上进行的操作分两步:先进行logsoftmax( )对模型最后一层的输出计算每个类别的得分,这个时候该输出还是[batch_size, class_Num],然后再进NLLLoss取标签对应的那个类别的得分输出[batch_size],和常规的交叉熵不一样呢?
一般神经网络最后一层的输出:
1 得到每个类别的得分score
2 经过softmax或者sigmoid获得概率输出
3 预测概率和真实值标签经过oneHot编码计算交叉熵损失
经过代码验证,只是步骤不一样,实际上作用效果相同。logsoftmax()就是在softmax公式最外层加了log函数,而正常的交叉熵计算公式,取标签对应的One Hot编码计算loss。因为除了正确标签的one hot编码为1,其他类别都为0。所以相当于只取正确标签所对应的-logsoftmax()。也就是上一段的计算方式,殊途同归,可以捕捉模型的差异。
3 二分类问题利用混淆矩阵计算正确率
在二分类问题中,如果样本的比例失衡,那么单纯的使用将所有正确率相加除以总样本数的方式,来衡量模型的好坏是不科学的。因为如果样本比例:猫:狗= 2:1, 那么模型将所有的结果都预测为猫,正确率可以达到66%。但实际上模型根本没有学到任何东西。混淆矩阵的定义(摘自百度百科):
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。
[1] 在人工智能中,混淆矩阵(confusion
matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。混淆矩阵是通过将每个实测像元的位置和分类与分类图像中的相应位置和分类相比较计算的。
在pytorch的代码里要引入混淆矩阵需要导入meter模块。创建trian和val的混淆矩阵,通过AverageValueMeter()可以获取batch损失值的mean和std。而通过混淆矩阵又可以计算每一个 epoch后的accuracy。最后通过visdom可视化到端口8907。下面方式一代码是通过混淆矩阵的方式计算loss和acc。
from torchnet imaport meter
train_loss = meter.AverageValueMeter() #to measure the average loss over a collection of examples
train_cm = meter.ConfusionMeter(class_num)
val_cm = meter.ConfusionMeter(class_num)
if phase == 'train': # backward + optimize only if in training phase
loss.backward() # 求导和更新参数是两个独立的过程
optimizer.step()
train_loss.add(loss.item())
train_cm.add(outputs.detach(), labels.detach())
else:
val_cm.add(outputs.detach().squeeze(), labels.detach())
cm_value = val_cm.value() #compute every epoch
val_acc = 100. * (cm_value[0][0] + cm_value[1][1]) / (cm_value.sum())
vis.plot('val accracy', val_acc)
vis.log("epoch:{epoch}, loss:{loss}, train_cm:{train_cm}, val_cm:{val_cm}".format(
epoch=epoch, loss=train_loss.value()[0], val_cm=str(val_cm.value()),
train_cm=str(train_cm.value())))
为了对比看出普通的正确率计算方式和混淆矩阵的计算方式,我在代码里也添加了方式二,计算loss和acc的代码:
running_loss = 0.0
running_corrects = 0
# put in dataloder iter
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels.long())
running_loss += loss.item() * batch_size #compute every mini-batch
running_corrects += torch.sum(preds == labels.data)
#put in every epoch
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
将打印的结果显示出来(图1在jupyter notebook中print显示,图2在visdom窗口log显示):
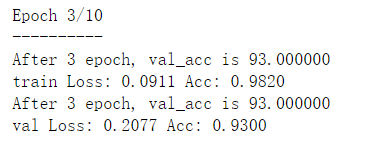

可以发现,两种的计算方式还是有差异的。方式一显示训练集的train_acc=(677+689)/(677+73+61+689) = 94.6%,测试集的val_acc = (98+87) / (98+87+2+13 ) = 92.5% 而方式二表明
train_acc = 98.2%,val_acc = 93%。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 37
37 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)