- @zyctimes
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
当主 Agent 需要并行处理耗时任务或将工作委托给"助手"时,OpenClaw 提供了**子 Agent(Sub-Agent)**机制。本文深入解析 `sessions_spawn` 的完整生命周期:子 Agent 如何在独立的 session 中运行(`agent:<agentId>:subagent:<uuid>`),为何只能**向父 Agent 汇报**而非对等通信,以及当前架构的**设计

介绍Azure ML Pipeline的使用,并且结合MLFlow一起跟踪ML模型。此章节将通过一个案例详细介绍如何训练,测试,打包和注册模型。MLFlow是一个很好的MLOps管理的开源软件。这里我们可以使用MLFlow的Tracking模块记录和跟踪训练运行指标和模型项目,而不管试验环境是位于本地计算机、远程计算目标、虚拟机还是 Azure Databricks 群集上,并最终将其存储在 Az

当主 Agent 需要并行处理耗时任务或将工作委托给"助手"时,OpenClaw 提供了**子 Agent(Sub-Agent)**机制。本文深入解析 `sessions_spawn` 的完整生命周期:子 Agent 如何在独立的 session 中运行(`agent:<agentId>:subagent:<uuid>`),为何只能**向父 Agent 汇报**而非对等通信,以及当前架构的**设计
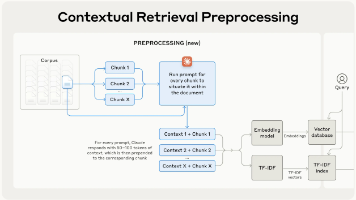
传统 RAG 在分块与向量化时容易丢失文档级上下文,导致检索 recall 不足。Anthropic 提出的 Contextual Retrieval 在嵌入与建 BM25 索引前,用 LLM 为每个块生成简短「情境说明」并拼在块前,然后使用 Contextual Embeddings + Contextual BM25。本文基于Anthropic 原文梳理原理、实现要点与 Prompt Cach
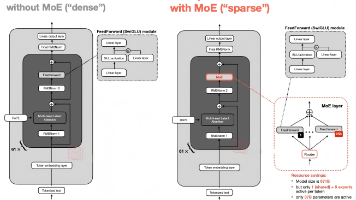
本文在 Decoder-only Transformer 与 Mixture-of-Experts(MoE)的基础上,系统介绍 **DeepSeekMoE** 的架构设计及与 LLaMA、标准 Transformer、GShard 的对比。内容包括:MoE 在 Transformer 中的位置(用 MoE 层替代 FFN)、DeepSeekMoE 的两大策略(细粒度专家切分、共享专家隔离)、数学形
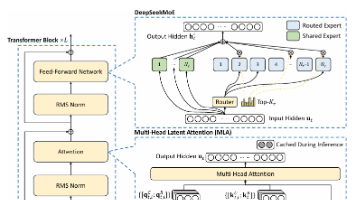
摘要:DeepSeek-V2 是基于 Decoder-only Transformer 架构的 MoE 大模型,通过创新注意力机制(MLA)和稀疏 FFN(DeepSeekMoE)实现高效训练与推理。MLA 采用低秩 K-V 联合压缩和解耦 RoPE,将 KV cache 减少至标准 MHA 的 1/56;DeepSeekMoE 在 236B 总参数下仅激活 21B 参数,达到高性能。相比 Dee
本文在 [Decoder-only Transformer]、[LLaMA 架构]、[DeepSeek LLM]、[DeepSeekMoE] 与 [DeepSeek-V2] 的基础上,系统介绍 **DeepSeek-V3** 的技术报告要点。V3 延续 **Multi-head Latent Attention(MLA)** 与 **DeepSeekMoE** 作为注意力与稀疏 FFN 的核心设计
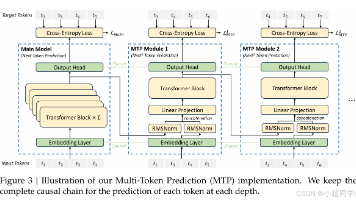
摘要:本文解析Qwen2模型架构,重点说明其相对Qwen1的四大改进:(1) 全系列采用GQA(分组查询注意力)替代MHA;(2) 通过调整RoPE基频(10^4→10^6)、引入YARN和DCA技术,将上下文窗口扩展至128K;(3) 小模型(0.5B/1.5B)使用嵌入绑权策略,大模型(7B/72B/MoE)不绑权;(4) 新增MoE变体(57B总参,激活约14B参数)。文章详细拆解了Toke
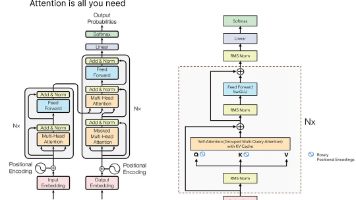
摘要:RoPE(Rotary Position Embedding)通过几何旋转将位置信息编码进注意力分数,替代传统的位置向量加法。其核心设计让点积计算仅依赖相对位置距离,符合自回归模型需求。本文从动机出发,推导二维旋转公式如何实现相对位置编码,并分析其与经典位置编码的差异。进一步探讨长度外推问题,介绍YaRN等方案如何通过调整旋转频率适应长文本场景,并与LLaMA、Qwen等主流架构实现兼容。R
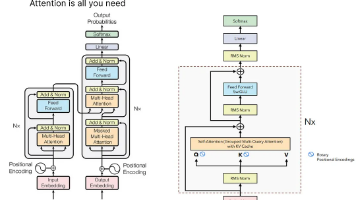
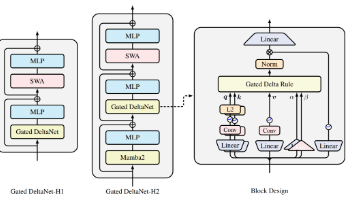
标准 Transformer 的 softmax 自注意力在长上下文上面临 $O(L^2)$ 的计算与显存开销。线性 Transformer 把注意力改写为“线性 RNN + 矩阵状态”的形式,推理可做到近似 $O(L)$,但在**检索**与**长上下文精确记忆**上长期落后。论文 *Gated Delta Networks: Improving Mamba2 with Delta Rule*(I