




- @ziyuankeji88
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
支持 Windows / Linux /macOS 全平台。适合数学、物理、工科、科研人员日常公式推导与验证。的符号计算库,无需复杂环境、无需编译,专门用于。
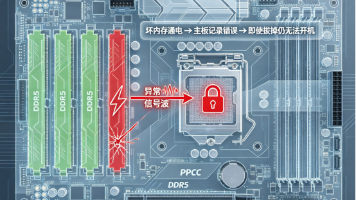
现在的主板不管是家用DDR4/DDR5,还是服务器主板,开机都会进行内存训练,自动检测内存电压、时序、总线信号,并临时储存硬件状态。哪怕拔掉坏内存,主板依旧保留故障判定,直接锁死内存总线,所以全部好内存也无法点亮。单条内存负载最低、干扰最小,主板会强制清除错误记录,重新完成内存训练重置参数。这也是服务器、工作站必须用ECC纠错内存的原因,更强的容错性,适配长期不间断运行。✅ 最离谱:插过一次坏内存
当体育产业全面数字化、出海业务全球铺开、线下大型活动常态化,一套稳定、分层、弹性、分布式的服务器架构,早已不是加分项,而是业务稳定运转的刚需底线。进球瞬间,数百万用户同时刷新比分、发送评论、回放精彩镜头,数据库服务器、应用服务器、缓存服务器形成三层架构,负载均衡自动分流流量,弹性伸缩应对瞬时峰值,避免网站宕机、购票卡顿。16 座场馆分散美、加、墨三国,美国承办 78 场核心赛事,加拿大、墨西哥各

V100:32GB HBM2 ECC,专业驱动认证,FP64 算力 7.8 TFLOPS(4090 仅 1.3)!·32GB HBM2 显存,轻松跑 LLaMA-7B 微调、Stable Diffusion 高分辨率训练;·LLaMA-7B 微调(QLoRA):batch_size=4,显存占用 28GB,训练稳定无 OOM。·4090:24GB GDDR6X,无 ECC 显存,不支持 NVLin

甲骨文官宣采购数十万颗Vera CPU,用于AI智能体云端训练,这是英伟达首次大规模切入服务器CPU市场。行云集成电路公布自研国产GPU架构,优化推理成本,将企业本地AI部署成本从百万压缩至十万区间,主打轻量化私有部署,填补低端国产推理算力缺口。呼和浩特移动智算中心对外披露,总算力达19000PFlops,智能算力占比82%,为国内头部商用算力节点。成都天府智算中心正式投运,当地持续发放算力券、模
属于定制机型,大众知名度低,受限部分涉密、重大项目品牌准入要求;全国线下上门售后门店少,硬件故障以远程诊断 + 寄件换修为主;针对 VASP、Gaussian、LAMMPS 等仿真软件预编译调优,系统、调度工具、监控面板预装,开箱即用;硬件按需灵活搭配,标配 ECC 内存、冗余电源,7×24 小时运行稳定;同配置较一线品牌便宜 15%-35%,无品牌溢价,适配高校经费报账;技术团队深耕科研算力,远

机房标准机架机型,可直接上架学校公共机房,不占用实验室桌面空间。25万档位不要买原厂品牌整机,戴尔/浪潮整机溢价高达40%,高校渠道定制装机+官方联保,性价比直接拉满,报账资质完全一致。遵循这个逻辑,下面四档预算全部按照该比例配置,拒绝网红畸形整机(比如低价大显存弱CPU、大内存垃圾电源这种智商税机器)。普通课题组几乎用不上,一般为重点实验室、国家级项目、院级公共算力平台采购,不推荐小课题组盲目跟

在各大高校实验室中,使用 ANSYS、ABAQUS 开展有限元仿真早已成为机械、土木、材料等专业研究生与导师的日常科研手段。但绝大多数科研人都会遇到同款仿真痛点:模型体量并不算庞大,求解却动辄耗时数小时甚至通宵达旦;明明升级多核处理器,仿真运算速度却毫无提升;仿真运行中途频繁闪退崩溃,频频弹出内存不足、磁盘空间写满等报错……其实这类问题大多并非软件操作失误、模型收敛性差,核心根源在于硬件配置与有限

ECC(Error-Correcting Code)内存能自动检测并修正内存中的单比特错误,防止因宇宙射线、电压波动导致的数据损坏。“这款卡有24G显存,FP64性能强,支持ECC,算力高达XX TFLOPS!今天用最直白的语言,拆解四个高频术语,帮你精准判断:哪些是刚需,哪些可忽略。显存是 GPU 自带的高速存储,用于存放模型参数、激活值、中间计算结果。——深入对比HBM带宽、ECC支持、驱动兼

甲骨文官宣采购数十万颗Vera CPU,用于AI智能体云端训练,这是英伟达首次大规模切入服务器CPU市场。行云集成电路公布自研国产GPU架构,优化推理成本,将企业本地AI部署成本从百万压缩至十万区间,主打轻量化私有部署,填补低端国产推理算力缺口。呼和浩特移动智算中心对外披露,总算力达19000PFlops,智能算力占比82%,为国内头部商用算力节点。成都天府智算中心正式投运,当地持续发放算力券、模