
写文章




- @zhenwudi
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
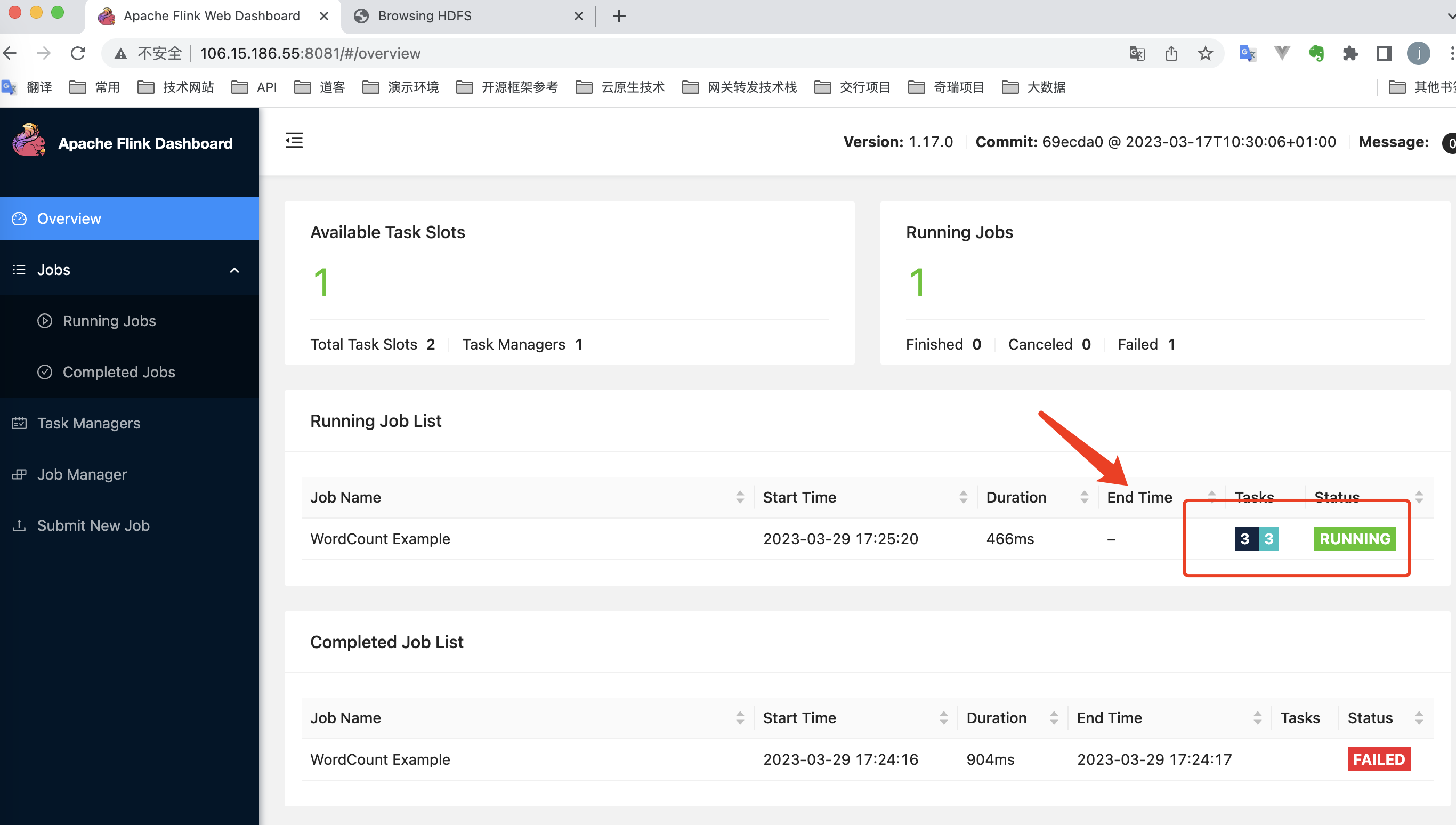
Flink-1.17.0(Standalone)集群安装-大数据学习系列(四)
链接: https://pan.baidu.com/s/1-GAeyyDOPjhsWhIp_VV7yg?链接: https://pan.baidu.com/s/1X_P-Q8O_eLADmEOJ438u5Q?切换到k8s-node1、k8s-node2 验证是否安装成功。切换到k8s-node1机器上操作(分发环境)2.1 在集群(各机器上都执行!2.1 切换到k8s-master执行。2.2 切
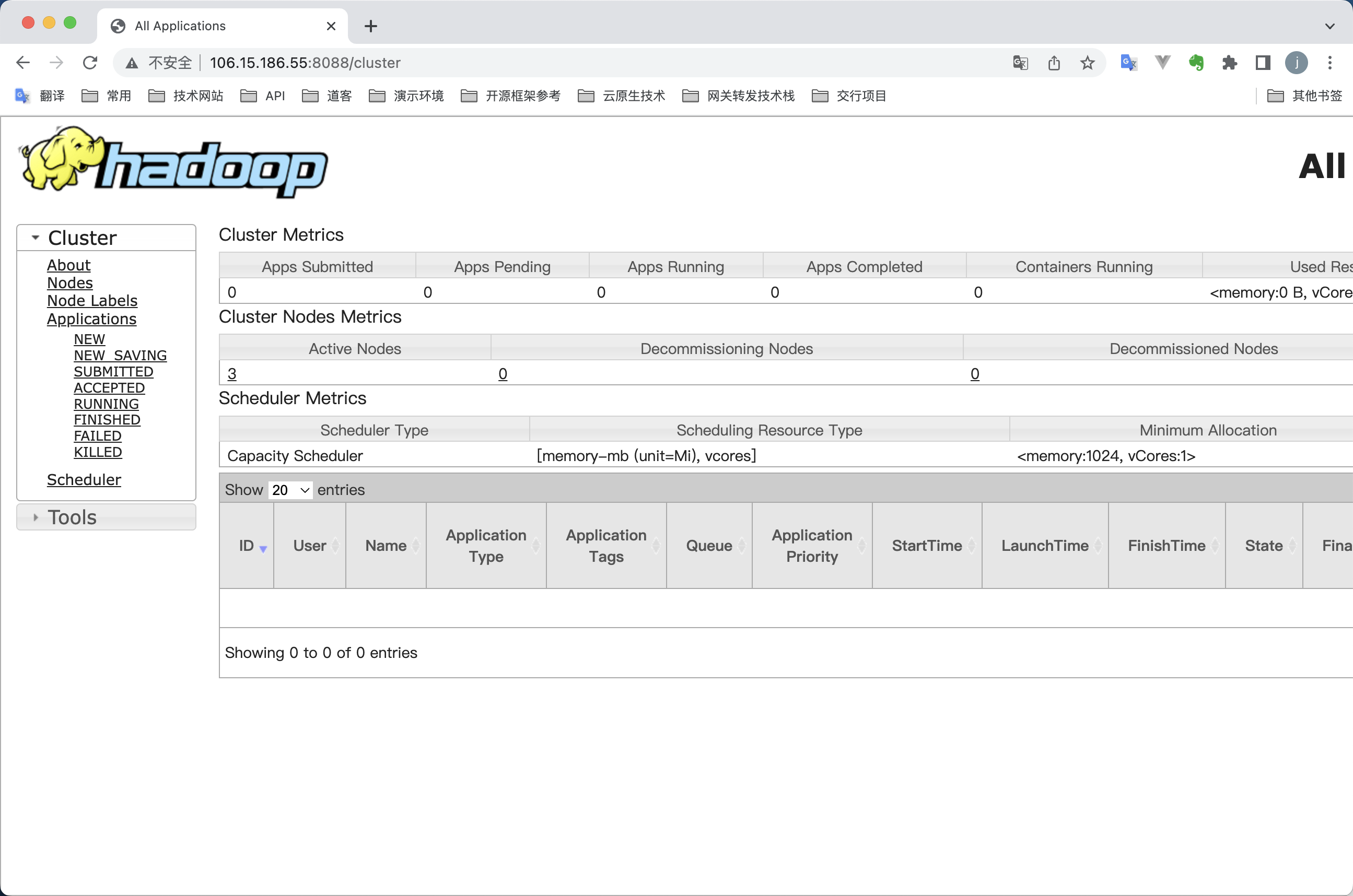
(最新版本)hive4.0.0 + hadoop3.3.4 集群安装(无坑版)-大数据学习系列(一)
网上的找的文档大多残缺不靠谱,所以我整理了一份安装最新版本的hive4..0.0+hadoop3.3.4的学习环境,可以提供大家安装一个完整的hive+hadoop的环境供学习。Hive Metastore是Hive的元数据存储服务,需要确保Metastore服务已经启动,并且在Beeline的配置文件中正确配置了Metastore的地址。HiveServer2是Hive的查询服务,需要确保Hiv
(最新版本)hive4.0.0 + hadoop3.3.4 集群安装(无坑版)-大数据学习系列(一)
网上的找的文档大多残缺不靠谱,所以我整理了一份安装最新版本的hive4..0.0+hadoop3.3.4的学习环境,可以提供大家安装一个完整的hive+hadoop的环境供学习。Hive Metastore是Hive的元数据存储服务,需要确保Metastore服务已经启动,并且在Beeline的配置文件中正确配置了Metastore的地址。HiveServer2是Hive的查询服务,需要确保Hiv
到底了