- @zhangjiaoshou_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
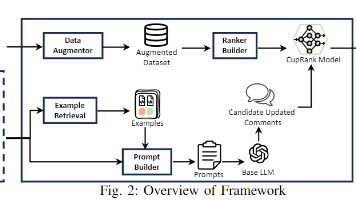
本文介绍了论文《LLMCup: Ranking-Enhanced Comment Updating with LLMs》的核心内容。代码评论常因未及时更新导致过时,现有方法存在准确率低、处理复杂场景能力弱等问题。LLMCup提出“更新-排名”范式,先用LLM生成多样化候选评论,再用CupRank模型筛选最优结果。实验显示,其准确率比现有方法提升49.0%-116.9%,语义贴合度更高,甚至超过人类
本研究采用混合方法,以挪威公共部门敏捷组织NAV IT为对象,探究GitHub Copilot对开发者活动与感知生产力的影响。研究分析2年间703个仓库的26,317次非合并提交,对比25名Copilot用户与14名非用户的周级开发数据,并结合13次访谈与63份调查的定性反馈。结果显示:Copilot用户在工具引入前已显著更活跃(提交频率约为非用户2倍),工具使用后客观提交活动无统计显著变化;尽管

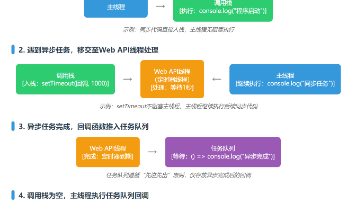
本文围绕JavaScript异步编程展开,因JS单线程特性,同步操作易阻塞主线程致页面卡顿,异步编程成为核心技能。文章介绍其演进历程:回调函数实现简单但易陷“回调地狱”;Promise以链式调用优化结构,支持统一错误处理;async/await基于Promise实现同步化写法,可读性最佳。还提及Promise.all()等实战技巧,对比各方案优缺点与适用场景,指出“async/await+Prom
JavaScript中this的指向规则是核心难点,普通函数和箭头函数的this行为差异显著。普通函数的this动态绑定,取决于调用对象(如对象方法、全局调用或构造函数实例);箭头函数的this静态继承外层作用域,定义即固定。关键区别在于:普通函数遵循"谁调用指向谁",箭头函数遵循"定义时继承谁"。实际开发中,对象方法用普通函数,嵌套回调用箭头函数。通过对比

摘要: JavaScript函数是代码复用的核心工具,支持多种定义方式(函数声明和表达式)。函数参数灵活,支持默认值、剩余参数和arguments对象。匿名函数和箭头函数提供简洁写法,但箭头函数的this指向不同。函数作为"一等公民",可赋值、传参、返回和动态创建,实现高阶函数和回调,是JS强大灵活性的关键特性。掌握这些概念能显著提升代码复用性和可维护性。

JavaScript变量是存储数据的核心容器,文章从基础概念到TypeScript进阶全面解析了变量知识。主要内容包括:1) 变量基础概念,对比let、const和var的差异,推荐优先使用const;2) 变量命名规则与常见编程命名风格对比;3) JavaScript数据类型,包括基本类型(String、Number、Boolean等)和引用类型,特别区分null与undefined的差异;4)

Java变量类型判断与判等实战避坑指南 本文系统梳理了Java中变量类型判断和判等的核心方法及常见陷阱。类型判断包含4种方式:instanceof(考虑继承)、getClass()(精确匹配)、基本类型编译时确定和反射场景的isInstance()。判等操作需区分基本类型(==比较值)和引用类型(==比较地址,equals()比较内容)。特别强调: String判等需注意常量池机制 自定义类必须同
本文通过生活化的比喻讲解了Java面向对象编程的核心概念:类与对象(以月饼模具为例)、封装(手机电池设计)、继承(动物与狗的关系)、多态(USB设备兼容性)和抽象类(形状图纸)。每个概念都配有可运行的代码示例,帮助初学者理解Java面向对象编程的基本思想,包括如何定义类、创建对象、实现封装、继承与多态,以及使用抽象类强制子类实现特定方法。这些概念共同构成了Java面向对象编程的基础框架。

Java控制语句详解:代码中的生活逻辑 本文通过生活化案例讲解Java三大控制结构:顺序结构(如冲咖啡步骤)、分支结构(如带伞决策、成绩评级)和循环结构(如跑步记录、减肥计划)。顺序结构是代码的默认执行方式;分支结构(if/switch)用于条件选择;循环结构(for/while/do-while)处理重复任务。每种结构都配有生活场景类比和代码示例,帮助初学者理解程序流程控制的基本原理。控制语句本

本文详细介绍了在VSCode中搭建Java企业开发环境的完整流程。首先需要安装JDK(建议JDK 11或17)并配置环境变量,然后安装VSCode和Maven。接着安装必要的VSCode插件,包括Java Extension Pack、Spring Boot Extension Pack和Lombok插件。最后通过命令面板创建Maven项目,填写项目信息完成搭建。该教程不仅适用于VSCode,也适