- @zcg1942
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
首先看一下谷歌的开篇论文这篇论文是计算机视觉领域具有的开山之作,由谷歌研究团队(Google Research, Brain Team)在2020年提出,并在2021年的 ICLR 会议上发表。它首次成功地将自然语言处理(NLP)领域大火的架构,直接应用到了图像识别任务中,打破了卷积神经网络(CNN)在视觉领域的长期统治地位。CNN和注意力在。
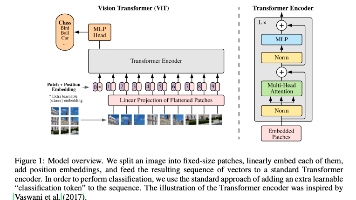
首先看一下谷歌的开篇论文这篇论文是计算机视觉领域具有的开山之作,由谷歌研究团队(Google Research, Brain Team)在2020年提出,并在2021年的 ICLR 会议上发表。它首次成功地将自然语言处理(NLP)领域大火的架构,直接应用到了图像识别任务中,打破了卷积神经网络(CNN)在视觉领域的长期统治地位。CNN和注意力在。
一般来说,数据对的质量很大程度上决定了模型的效果。但干净的数据获得总是很困难的,所以有一些聪明人想出来了一些不需要干净数据的奇思妙想。这里就简单学习一下。Learning image restoration without clean data.ICML 2018,来自英伟达实验室NVlabs生活中的测量,最常用的就是多次测量求平均值。
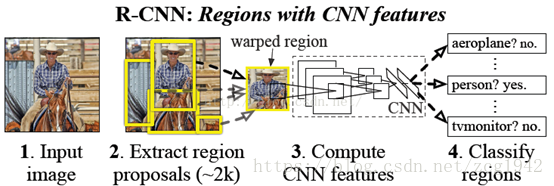
下载链接http://islab.ulsan.ac.kr/files/announcement/513/rcnn_pami.pdfhttp://xueshu.baidu.com/s?wd=paperuri:%286f32e0834ddb27b36d7c5cda472a768d%29&filter=sc_long_sign&tn=SE_xueshusource_2kd
越来越多的手机开始上双摄,首先解释一下双摄的目的,双摄可以达到什么样的效果。首先双摄可以分为两类,一类是利用双摄获得图像中物体到镜头或者焦距的距离,得到景深信息就可以进行后续的3D重建、图像分割、背景虚化等;一类是利用两个摄像头所成的不同图像进行图像融合,获得更多的细节信息,包括RGB镜头和Mono黑白摄像头获得图像的融合,黑白摄像头可以捕捉更多的细节,即解析力更高;还有广角摄像头和长焦摄像...
信息量,可以说就是在将信息量化。首先信息的相对多少是有切实体会的,有的人一句话能包含很多信息,有的人说了等于没说。我们还可以直观地感觉到信息的多少和概率是有关的,概率大的信息也相对低一些。为了量化信息,一个做法就是找到一个单位,比如说抛硬币就是一个基本单位,或者说我们使用01编码。先看等概率的情况,种类数越多,那么需要编码的长度就越大,很显然是log的指数关系。因为是等概,所以概率和种类数目就是倒

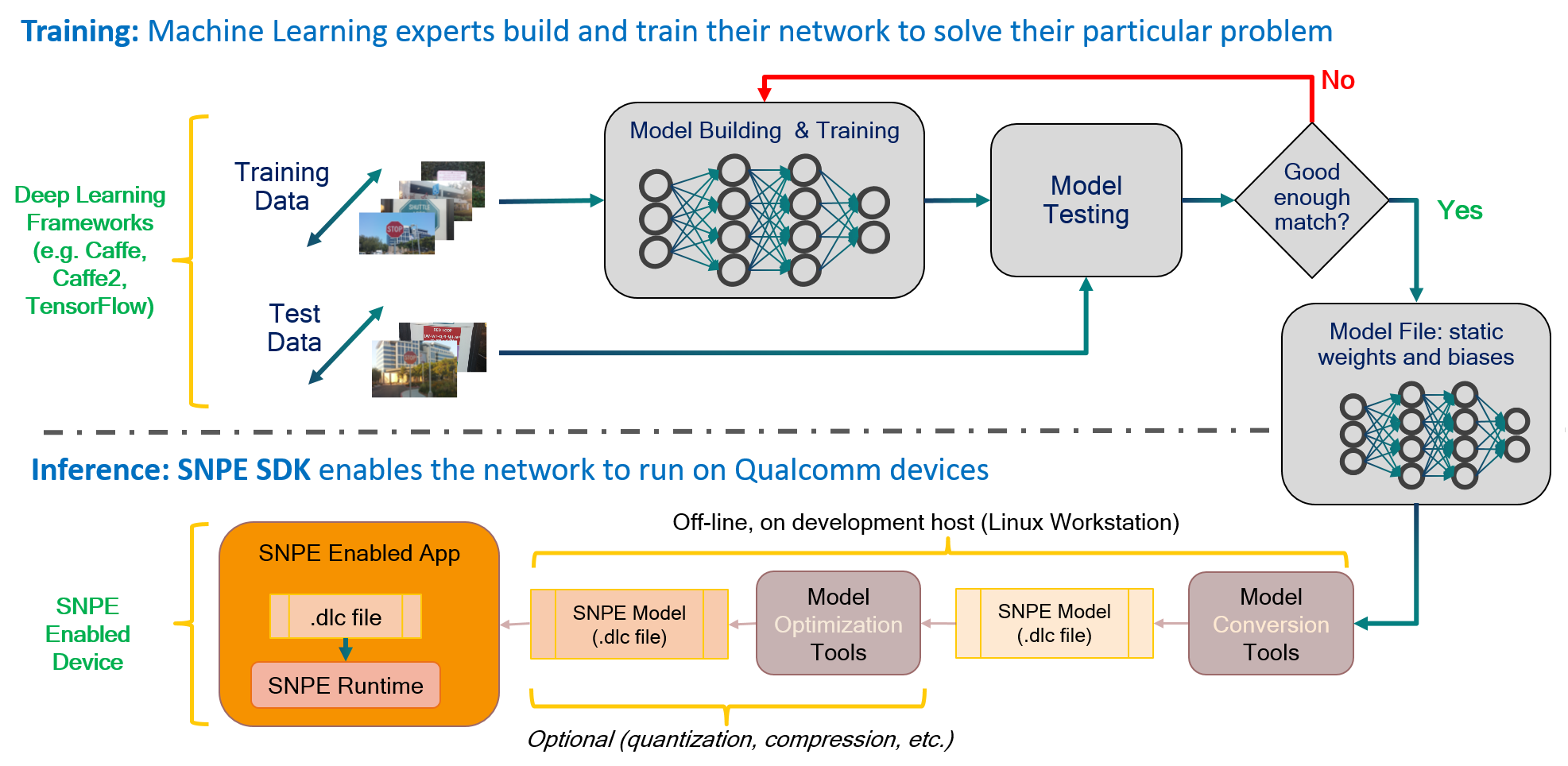
The Snapdragon Neural Processing Engine (SNPE)是高通骁龙为了加速网络模型设计的框架。但它不只支持高通,SNPE还支持多种硬件平台,ARM平台、Intel平台等。支持的深度学习框架也有包括Caffe、TensorFlow和ONNX等。SNPE可以前向运行模型,但需要先将模型转换为Deep Learning Container (DLC) file才可以加
一般来说,数据对的质量很大程度上决定了模型的效果。但干净的数据获得总是很困难的,所以有一些聪明人想出来了一些不需要干净数据的奇思妙想。这里就简单学习一下。Learning image restoration without clean data.ICML 2018,来自英伟达实验室NVlabs生活中的测量,最常用的就是多次测量求平均值。
这种格式的文件只保存模型的权重,而不包含优化器状态或其他信息,这也就意味着它通常用于模型的最终版本,当我们只关心模型的性能,而不需要了解训练过程中的详细信息时,这种格式便是一个很好的选择。二是模型的体积较大,一般真人版的单个模型的大小在7GB左右,动漫版的在2-5GB之间。这是因为 .ckpt 为了让我们能够从之前训练的状态恢复训练,好比从50%这个点位重新开始训练,从而保存了比较多的训练信息,比
大模型除了dreamshaper,还有Stable diffusion v1.4,Stable diffusion v1.5,Realistic Vision,majicMIX realistic,Deliberate v2,F222等。上半身特写,一位女孩,单人,Q版(或“迷你角色”/“简笔画风格可爱小人”,根据“chibi”具体语境调整),长发,面带笑容,开怀大笑,抱着泰迪熊,注视着观众,舞姿