




- @yuuuuuuuk
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
大模型推理性能优化的一个常用技术是KV Cache,该技术可以在不影响任何计算精度的前提下,通过空间换时间思想,提高推理性能。生成式generative模型的推理过程很有特点,我们给一个输入文本,模型会输出一个回答(长度为N),其实该过程中执行了N次推理过程。即GPT类模型一次推理只输出一个token,输出token会与输入tokens 拼接在一起,然后作为下一次推理的输入,这样不断反复直到遇到终

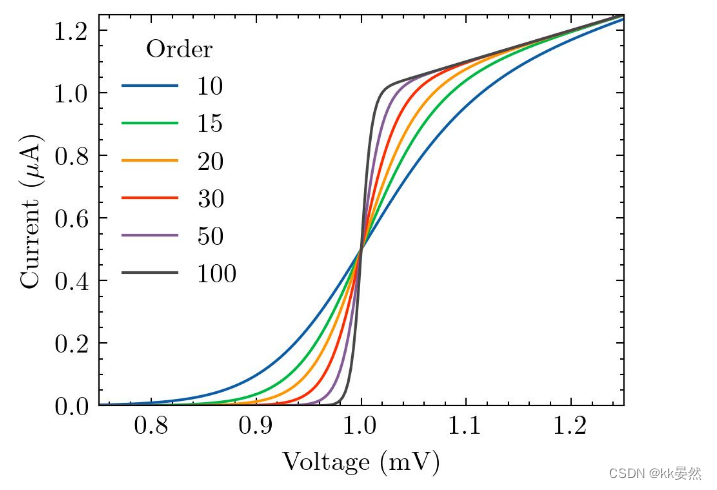
模块在线绘图工具效果展示:在线latex公式工具:公式识别:公式编辑:效果展示:折线对比绘画工具:效果展示:解决适配中文字体问题:
ORPO 是一种新颖微调(fine-tuning)技术,它将传统的监督微调(supervised fine-tuning)和偏好对齐(preference alignment)阶段合并为一个过程。这减少了训练所需的计算资源和时间。此外,实证结果表明,ORPO 在各种模型规模和基准测试(benchmarks)上优于其他对齐方法。在本文中,我们将使用 ORPO 和 TRL 库对新的 Llama 3 8

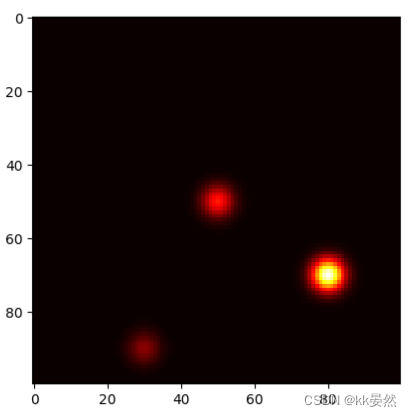
heatmap_smooth = gaussian_filter(heatmap, sigma=1)决定整体热力大小。效果展示:heatmap[y, x] = random.random()决定每个点概率。代码参考chatgpt生成。
ORPO 是一种新颖微调(fine-tuning)技术,它将传统的监督微调(supervised fine-tuning)和偏好对齐(preference alignment)阶段合并为一个过程。这减少了训练所需的计算资源和时间。此外,实证结果表明,ORPO 在各种模型规模和基准测试(benchmarks)上优于其他对齐方法。在本文中,我们将使用 ORPO 和 TRL 库对新的 Llama 3 8
大模型推理性能优化的一个常用技术是KV Cache,该技术可以在不影响任何计算精度的前提下,通过空间换时间思想,提高推理性能。生成式generative模型的推理过程很有特点,我们给一个输入文本,模型会输出一个回答(长度为N),其实该过程中执行了N次推理过程。即GPT类模型一次推理只输出一个token,输出token会与输入tokens 拼接在一起,然后作为下一次推理的输入,这样不断反复直到遇到终
大模型框架是指用于训练、推理和部署大型语言模型(LLMs)的软件工具和库。这些框架通常提供了高效的计算资源管理、分布式训练、模型优化和推理加速等功能,以便更好地利用硬件资源(如GPU和TPU)来处理庞大的数据集和复杂的模型结构。大模型框架的优点高效性:通过优化计算和内存管理,这些框架能够显著提高训练和推理的速度。可扩展性:支持分布式训练,可以在多个GPU或TPU上运行,适用于大规模数据集和复杂任务

ORPO 是一种新颖微调(fine-tuning)技术,它将传统的监督微调(supervised fine-tuning)和偏好对齐(preference alignment)阶段合并为一个过程。这减少了训练所需的计算资源和时间。此外,实证结果表明,ORPO 在各种模型规模和基准测试(benchmarks)上优于其他对齐方法。在本文中,我们将使用 ORPO 和 TRL 库对新的 Llama 3 8
PlutoSDR【入门软件无线电(SDR)】PySDR:使用 Python 的 SDR 和 DSP 指南

大模型框架是指用于训练、推理和部署大型语言模型(LLMs)的软件工具和库。这些框架通常提供了高效的计算资源管理、分布式训练、模型优化和推理加速等功能,以便更好地利用硬件资源(如GPU和TPU)来处理庞大的数据集和复杂的模型结构。大模型框架的优点高效性:通过优化计算和内存管理,这些框架能够显著提高训练和推理的速度。可扩展性:支持分布式训练,可以在多个GPU或TPU上运行,适用于大规模数据集和复杂任务