




- @yqwang75457
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文详细介绍了在 Windows 系统下安装 Ollama 并运行 DeepSeek - R1 模型的步骤。首先,进入 Ollama 官网下载约 745MB 的 OllamaSetup.exe 安装程序,默认安装到 C 盘,安装后通过 ollama -v 命令验证。启动后任务栏出现图标表明服务正常。接着再次访问官网,搜索 deepseek - r1,本地测试建议选 1.5b 版本。在命令提示符输入

本文详细阐述了 Qwen2.5-Omni-7B 模型的部署及演示运行过程。首先介绍了使用 modelscope 下载 Qwen/Qwen2.5-Omni-7B 模型至指定目录,以及拉取 qwenllm/qwen-omni:2.5-cu121 的 docker 镜像。接着说明了安装 NVIDIA Docker 工具包(nvidia-docker2)并重启 docker 的操作,以确保能在 Docke
本文详细阐述了 Qwen2.5-Omni-7B 模型的部署及演示运行过程。首先介绍了使用 modelscope 下载 Qwen/Qwen2.5-Omni-7B 模型至指定目录,以及拉取 qwenllm/qwen-omni:2.5-cu121 的 docker 镜像。接着说明了安装 NVIDIA Docker 工具包(nvidia-docker2)并重启 docker 的操作,以确保能在 Docke
本文详细介绍了在 Windows 系统下安装 Ollama 并运行 DeepSeek - R1 模型的步骤。首先,进入 Ollama 官网下载约 745MB 的 OllamaSetup.exe 安装程序,默认安装到 C 盘,安装后通过 ollama -v 命令验证。启动后任务栏出现图标表明服务正常。接着再次访问官网,搜索 deepseek - r1,本地测试建议选 1.5b 版本。在命令提示符输入
添加依赖:<!-- google图片处理 --><dependency><groupId>net.coobird</groupId><artifactId>thumbnailator</artifactId><version>0.4.11</version></dependency>代码pa
通过脚本,可以快速地部署和配置Kubernetes环境,省去了各插件手动部署、配置的繁琐过程。修改集群节点规划、软件版本信息后,执行“./install-k8s.sh”命令,即可完成集群环境搭建!脚本中各软件版本:docker_version="24.0.7"cri_dockerd_version="0.3.9"k8s_version="v1.28.2"

原始需求:某个员工提交xxxxx申请,需要领导审批,领导收到待办通知。问:领导从收到审批待办开始,到执行审批操作,用了多少分钟?(有效工作时长)类似问题:你开发某个功能,从xx开始,到xx做好发布,一共用了多少有效工作时长?那何为有效工作时长?答:就是按实际上班时间嘛,比如上午几点上班,几点开始午休,下午几点上班,几点下班?公司是否是双休?。。。。。之类的参数举例:1.每天上班时间,如:A、不定义
本文介绍了使用Python的pdfminer库提取PDF文档大纲的完整方法。主要内容包括:1)PDF大纲的概念和作用;2)准备工作(安装pdfminer和chardet库);3)核心代码实现,通过递归算法处理大纲层级结构,智能解码PDF字符串;4)输出效果展示,完整保留大纲层级关系并关联页码;5)关键技术解析,包括递归处理、页面定位和编码处理策略;6)常见问题解答和扩展应用场景。该方法可有效提取P
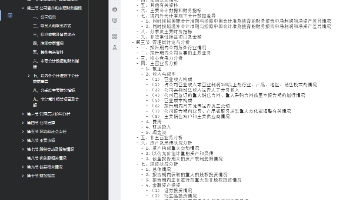
本文介绍了使用Python的pdfminer库提取PDF文档大纲的完整方法。主要内容包括:1)PDF大纲的概念和作用;2)准备工作(安装pdfminer和chardet库);3)核心代码实现,通过递归算法处理大纲层级结构,智能解码PDF字符串;4)输出效果展示,完整保留大纲层级关系并关联页码;5)关键技术解析,包括递归处理、页面定位和编码处理策略;6)常见问题解答和扩展应用场景。该方法可有效提取P
本文介绍了使用Python的pdfminer库提取PDF文档大纲的完整方法。主要内容包括:1)PDF大纲的概念和作用;2)准备工作(安装pdfminer和chardet库);3)核心代码实现,通过递归算法处理大纲层级结构,智能解码PDF字符串;4)输出效果展示,完整保留大纲层级关系并关联页码;5)关键技术解析,包括递归处理、页面定位和编码处理策略;6)常见问题解答和扩展应用场景。该方法可有效提取P