




- @yihuaixu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
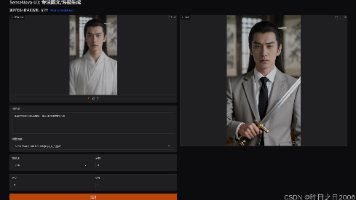
想象一下:你给它一张照片(真人、动漫人物甚至动物),配一段录音(可以是中文或英文),再加点文字描述(如“一个女孩在咖啡店微笑说话”),它就能生成一段嘴巴同步说话、表情自然、全身动作稳定的短视频。相关参数设置页面有说明,视频时长由num segments控制,为(93/25)时长的倍数,具体换算为:93/25=3.7,num segments就设置为2,大概7秒左右,以此类推。支持单人和双人两种生成
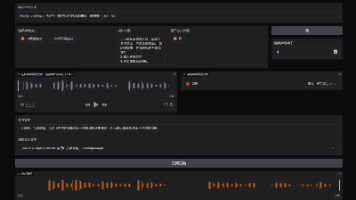
副语言标签:Breathing(呼吸声)、Laughter(笑声)、Suprise-oh(惊讶-哦)、Confirmation-en(确认-嗯)、Uhm(嗯哼)、Suprise-ah(惊讶-啊)、Suprise-wa(惊讶-哇)、Sigh(叹息声)、Question-ei(疑问-诶)、Dissatisfaction-hnn(不满-哼)支持标签:[呼吸声]、[笑声]、[惊讶-哦]、[确认-嗯]、[思

因视频转写效率不如直接音频转写,故新增视频转音频功能,如果是视频文件,建议先将视频转换为音频,再进行转写操作。GLM-ASR 是智谱AI开源的一个语音识别模型,虽然体积小,只有1.5B的参数量,但识别速度快、准确率高,在中文和方言识别上表现非常突出,尤其擅长处理低音量、嘈杂环境下的语音,比很多同类模型更稳健。GLM-ASR 支持 17 种语言,包括日、英、法、德、俄、西等主流语言,甚至连加泰罗尼亚

CosyVoice 3 是阿里巴巴团队推出的一款新一代语音合成模型,它能在没有额外训练的情况下,用多种语言和方言生成自然、富有情感的语音,声音效果接近真人。CosyVoice 3 只需3秒录音,就能让你的声音无缝切换语种、方言与情绪——中、粤、日、英、开心、愤怒......9 种通用语言、18种方言,通通搞定!自然语言控制:上传参考音频,输入需要合成的文字内容,支持喜怒哀乐等多种情感控制,支持十几
近期,腾讯联合上海交通大学开源了一个可控视频生成框架:MimicMotion,类似阿里的全民舞王,只需要上传一张照片,然后再上传一段人物的舞蹈或者动作视频,就可以生成以照片中人物为原型的动作或者舞蹈视频了。

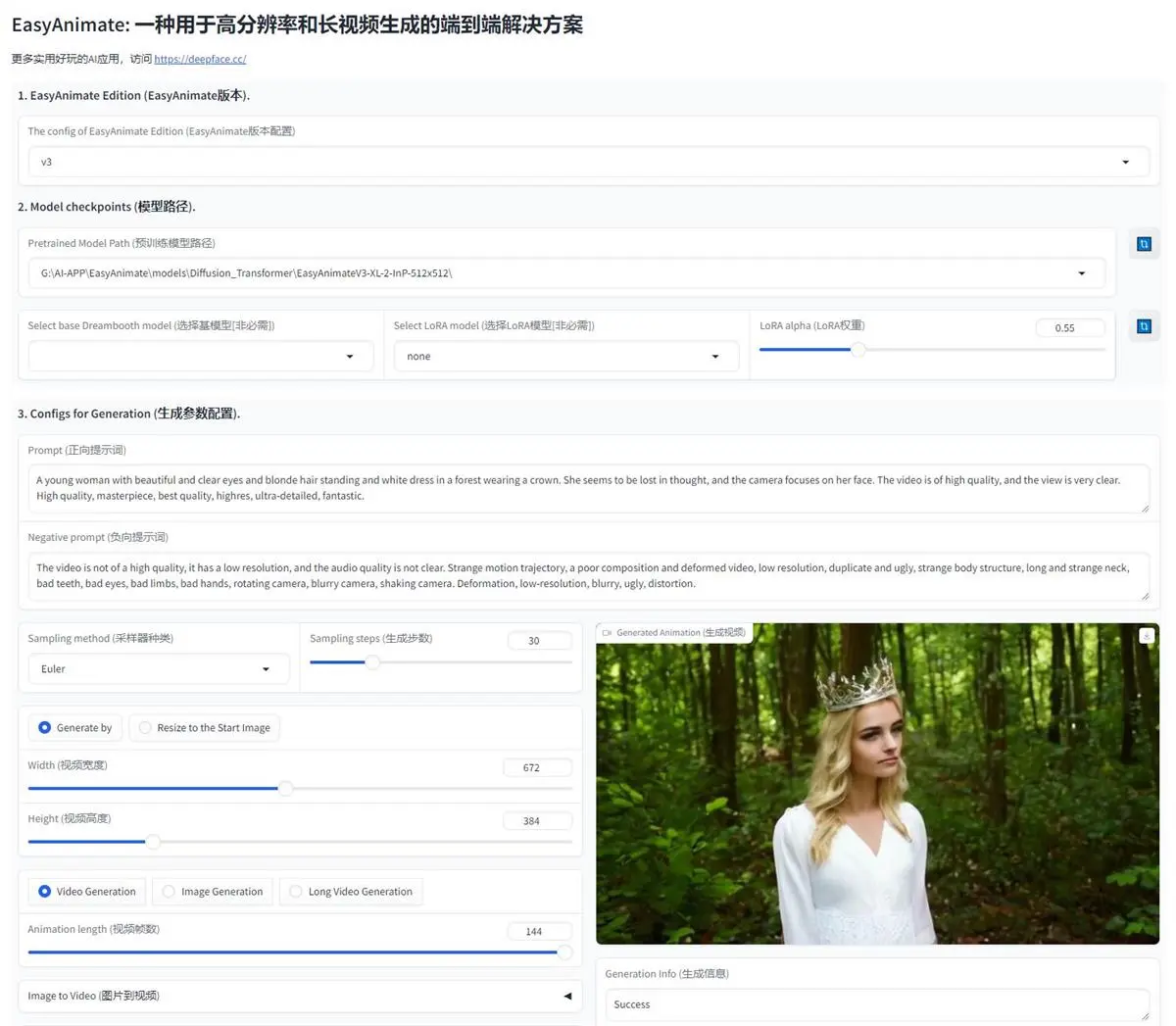
EasyAnimate是阿里云人工智能平台PAI自主研发的DiT-based视频生成框架,它提供了完整的高清长视频生成解决方案,包括视频数据预处理、VAE训练、DiT训练、模型推理和模型评测等
今天分享的 ClearerVoice V4版 ,根据部分会员建议制作了GUI界面,并新增了批量处理功能,支持 “语音增强、语音分离、语音超分辨率和音视频说话人提取 ” 四大功能批量处理,使用和之前的WebUI完全一样。它能帮你处理各种“脏乱差”的音频,让语音听得更清楚、更干净。ClearVoice 就是让“听不清”变成“听得清”的AI神器,不管你是普通用户想清理一段录音,还是开发者要做语音产品,都
同样支持WebUI和ComfyUI两种模式,WebUI支持简单的文生图和图像编辑,ComfyUI支持更多功能,比如图像理解、思考模式。图像生成支持多种模式,比如image_modes设置为interleave,设置提示词,可生成连贯的图文画本,interleave_max为生成的图片数量。双击启动,根据需要选择文生图频或图像编辑,不上传图像即为文生图(上传图像即为图像编辑),输入提示词,设置相关参
好部署:基于标准 Llama 架构,兼容 vLLM、SGLang、Ollama、llama.cpp、LM Studio 等主流工具,还有 GGUF、MLX 等量化版本,手机/电脑本地跑都很方便。MiniCPM5-1B 就是目前最强的小模型之一,专为“本地跑、不想依赖云端”的人设计,在体积和能力之间找到了很好的平衡,特别适合个人开发者、隐私场景和资源受限的环境。1B级别最强(SOTA):在同等大小的
参数 2B(20亿):基于 Qwen2.5 等大模型架构,结合了语义编码器、LLM(大语言模型)和流匹配(flow-matching)技术。零样本/少样本语音克隆:只需几秒钟的参考音频(甚至不需要对应文字),就能模仿出很像的说话人声音,支持“延续克隆”(带文字参考)和纯音色克隆。全连续、无离散 token:不像很多老模型那样把声音切成“碎片”处理,它全程用连续的音频信号处理,声音更自然、连贯,少了
