- @yang_daxia
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1.文字识别:RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition利用lstm+cnn编码2.transformer 中的位置编码各种transformer编码
需要使用cuda安装。
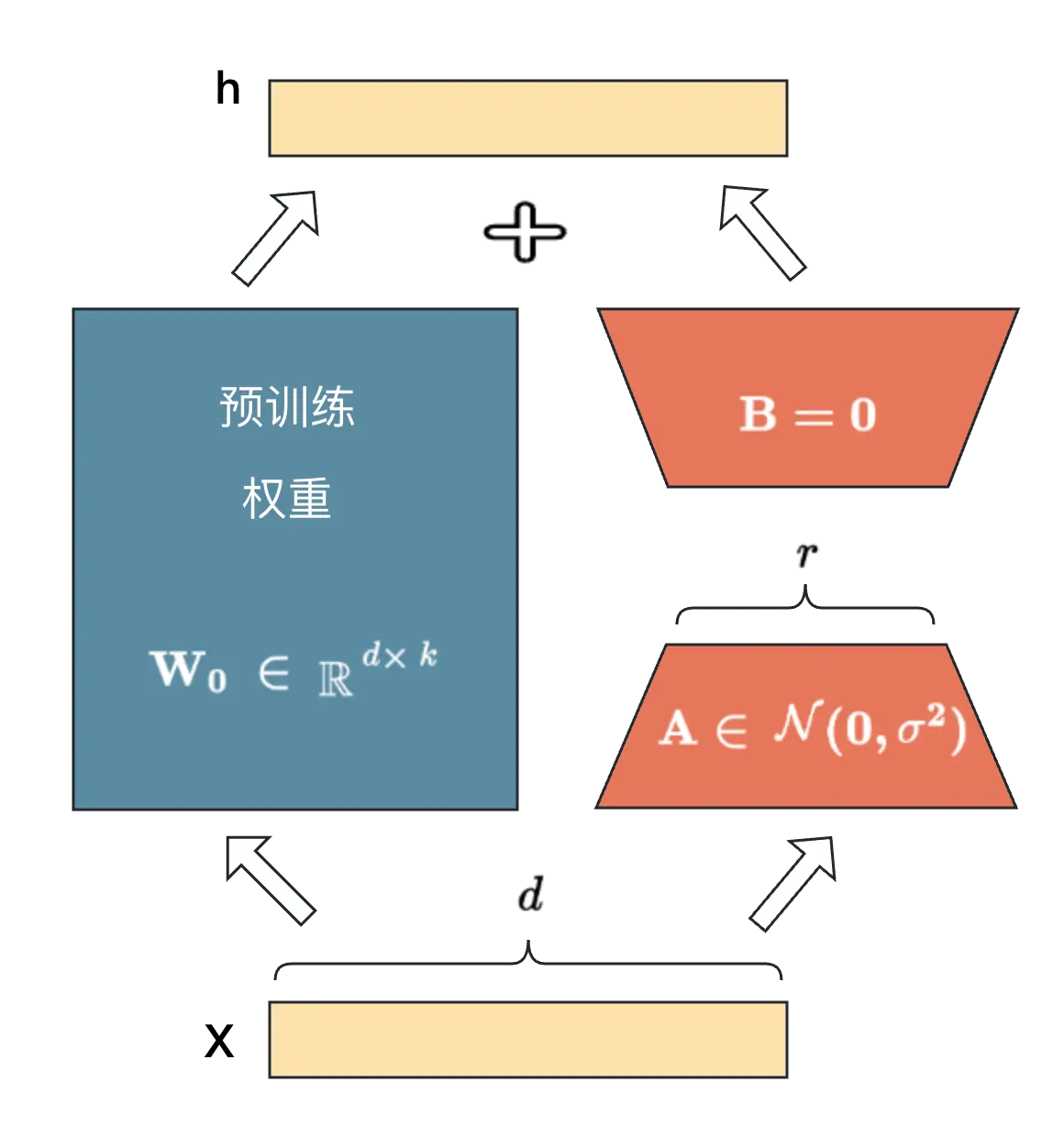
原理:不改变原始大模型参数,只加入一个类似残差分支,先降纬再升纬,因为模型是过参数化的,它们有更小的内在维度,模型主要依赖于这个低的内在维度(low intrinsic dimension)去做任务适配。优势:Lora的训练参数更少。
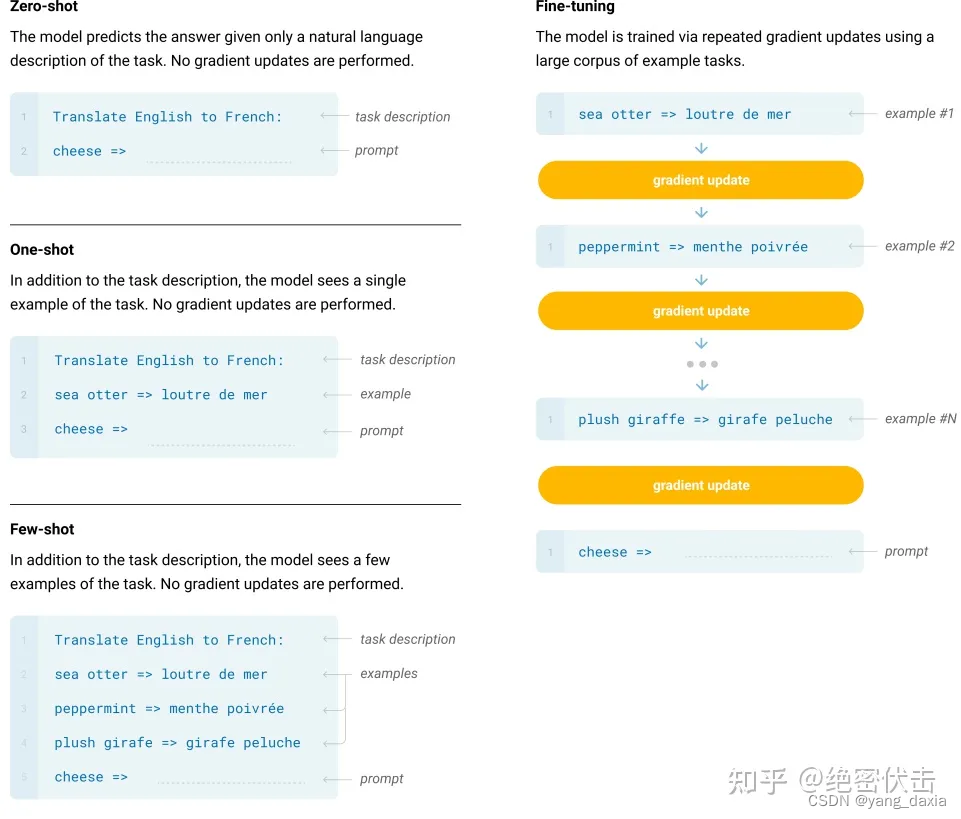
将问题分解为多个子问题,然后将子问题的答案加入到提示中,继续prompt,可以理解为更细化的多步step-by-step。1、Zero-shot、One-shot、Few-shot 与fintune。3、多数投票提高CoT性能——自洽性(Self-consistency)其次,思维链的应用领域是有限的。prompt的时候给出例子答案,然后再让模型回答。6、用大模型的CoT指导小模型,提升小模型的能
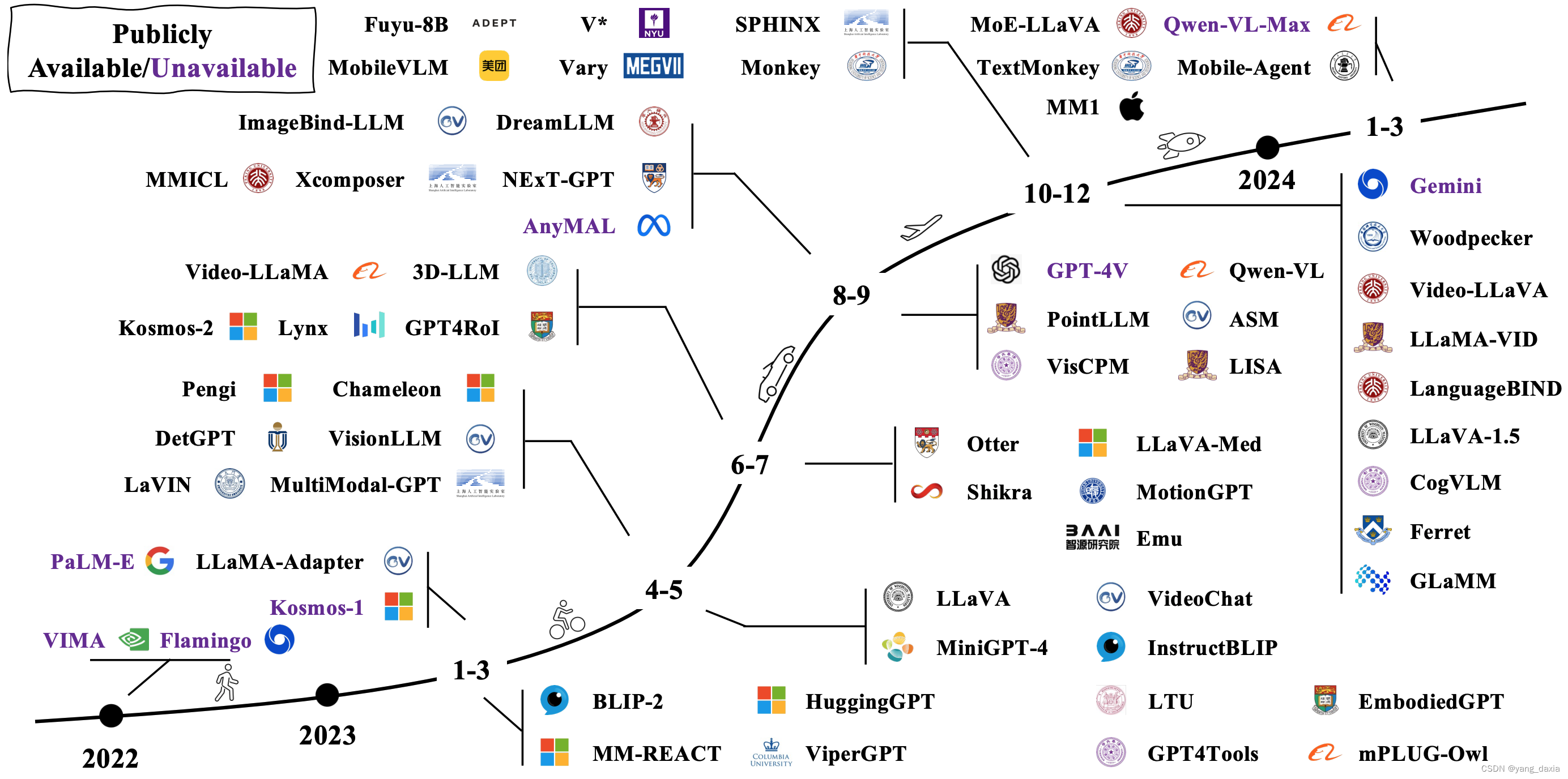
在单模态的基础上,加了新的模态,encoder后,通过mlp或者其他方式与text对齐,再输入大模型。如果需要生成新的膜套,可以再通过生成器。(此处与SD不太一样),chatGPT不会生成图片,可以对图片进行理解。LLM 辅助的视觉推理:利用 LLM 强大的内嵌知识与能力,并借助其他工具,设计各种视觉推理系统,解决各种现实问题。多模态幻觉:可以增加图像分辨率、提高数据质量,图像token表征、图像
删除动态连接库/usr/local/cuda-12.5/targets/x86_64-linux/lib里面多的一些库就可以了。现象nvidia-smi可以正常显示,但是多了一个 CUDA version ERR!重新装nviida-smi也不能解决问题。原因:lib多了一些东西。

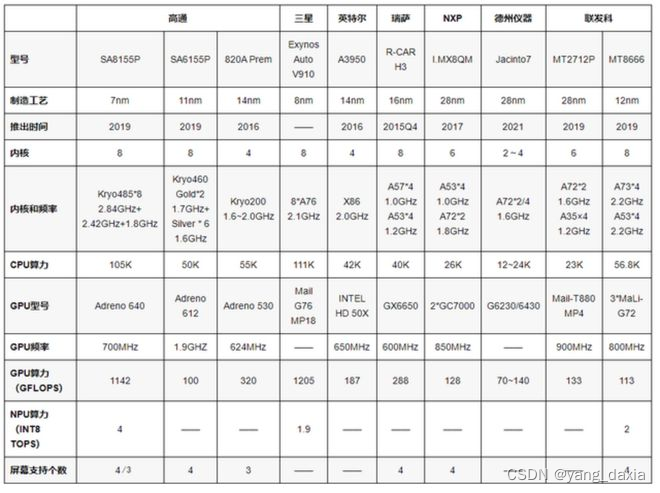
高通8155,mtk8666
在单模态的基础上,加了新的模态,encoder后,通过mlp或者其他方式与text对齐,再输入大模型。如果需要生成新的膜套,可以再通过生成器。(此处与SD不太一样),chatGPT不会生成图片,可以对图片进行理解。LLM 辅助的视觉推理:利用 LLM 强大的内嵌知识与能力,并借助其他工具,设计各种视觉推理系统,解决各种现实问题。多模态幻觉:可以增加图像分辨率、提高数据质量,图像token表征、图像
高通8155,mtk8666
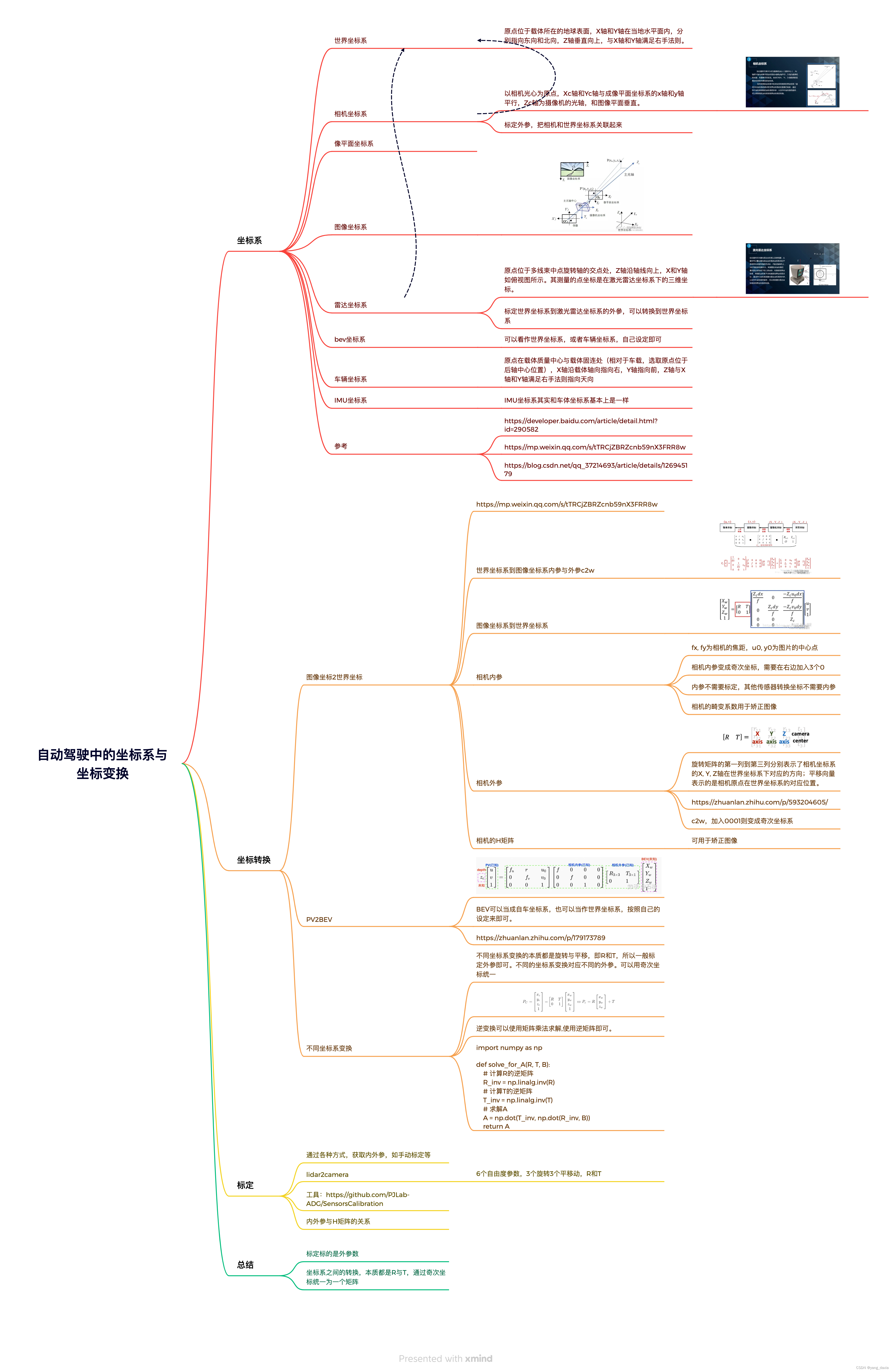
各种坐标系id=290582。