




- @xiaoxiaomo_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一直到写下这篇笔记开始,基于Swin的模型仍在paperwithcode上仍然霸榜Object Detection等多个榜单。很多博客都已经介绍的非常详细了,这里只记录一下自己学习过程中遇到的困惑。Swin与ViT的对比,ViT将image划分为固定大小的patch,以patch为单位进行attention计算,计算过程中的feature map 分辨率是保持不变的,并且ViT为了保持与NLP的一
import numpy as np#直接读取a=np.loadtxt("D:/Desktop/a.txt")print(type(a),a,np.shape(a))#自己编一个读取data_list=[]tmep=[]with open("D://Desktop//a.txt","r") as f:file = f.readlines()#print(file)for line in file:
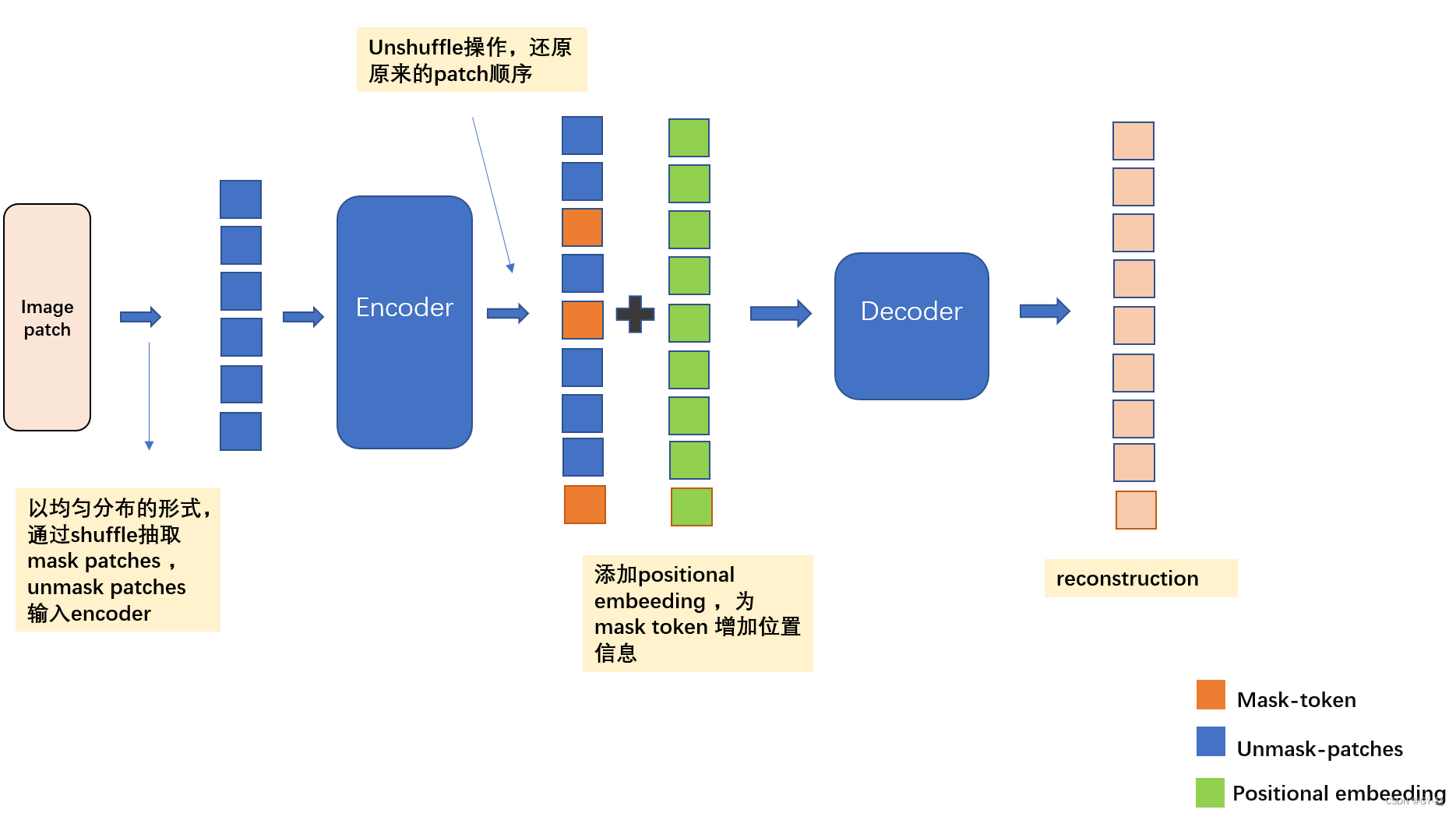
作者开门见山说明了深度学习结构拥有越来越大的学习容量和性能的发展趋势,在一百万的图像数据上都很容易过拟合,所以常常需要获取几百万的标签数据用于训练,而这些数据公众通常是难以获取的。MAE的灵感来源是DAE(denosing autoencoder),去噪自编码器就是encoder的输入部分加上噪声作为输入,decoder还原真实的输入,其损失函数为decoder的输出与真实输入之间的均方误差,相比
17.2中使用designe outline 代替outline,放置电路板外观,及Design Outline,这个和17.2之前的版本不一样,不能使用画线的方式添加Designe Outline,因为画线时在Board Geometry类中并未能找到Design Outline或Cutout子类。只能通过添加shape的方式添加。当使用outline时,会提示你推荐优先使用de......
import numpy as np#直接读取a=np.loadtxt("D:/Desktop/a.txt")print(type(a),a,np.shape(a))#自己编一个读取data_list=[]tmep=[]with open("D://Desktop//a.txt","r") as f:file = f.readlines()#print(file)for line in file: