




- @xiaonuonuoya
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
首先给出第一大类的metric,其实就是state value的加权平均,它是策略的函数,不同的策略对应的它的值也不同,所以我们就可以去优化,找到一个最优的策略,使其最大。下面可以把它写成更简洁的两个向量的内积,后面在求解梯度的时候有用:那么接下来我们来看一下如何选择 d(s),这里要分两种情况,第一种就是d(s) 和 Π是没有关系的,相互独立,这种比较简单,第二种就是d(s) 依赖于Π。先来看第

我们要首先定义目标函数,然后再不断地优化目标函数。这里S是随机变量,所以它就一定要遵守概率分布,应该是哪种呢?在这里介绍两种:首先第一种就是均匀分布,也就是我给每一个状态都赋予同样的概率,这是最简单的做法。但是也有缺点,target state 及其附近状态显示是更重要的,这种分布无法体现出状态之间的区别,第二种方法stationary distribution 能够很好的解决这个问题:到现在为止
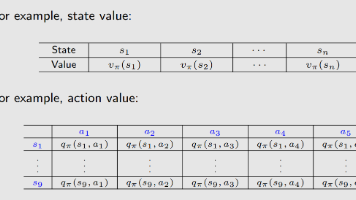
我们要首先定义目标函数,然后再不断地优化目标函数。这里S是随机变量,所以它就一定要遵守概率分布,应该是哪种呢?在这里介绍两种:首先第一种就是均匀分布,也就是我给每一个状态都赋予同样的概率,这是最简单的做法。但是也有缺点,target state 及其附近状态显示是更重要的,这种分布无法体现出状态之间的区别,第二种方法stationary distribution 能够很好的解决这个问题:到现在为止
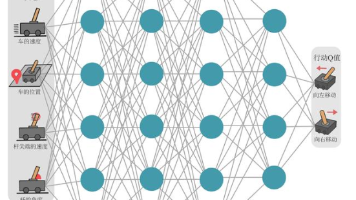
在前面介绍的Q-learning算法中,我们以矩阵的方式建立了一张存储每个状态下所有动作Q值的表格,表格中的每一个动作价值 Q (s,a) 表示在状态s下选择动作a然后继续遵循某一策略预期能够得到的期望回报。然而,这种用表格存储action value的做法只在环境的状态的动作都是离散的,并且空间都比较小的情况下适用。当状态或者动作数量非常大的时候,这种做法就不适用了。例如,当状态是一张RGB图像
为了降低实时处理时间,采用粗暴地边读边插值的方法,如果当前数据包间隔上一个数据包超过100,就插值。