- @wx_xtyx66
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
网盘链接】2024 NVIDIA GTC 大会(198演讲PPT+80电子海报)【网盘链接】2024 NVIDIA GTC 大会(198演讲PPT+80电子海。【网盘链接】2024 NVIDIA GTC 大会(198。【网盘链接】2024 NVIDIA GTC 大会(19。DIA GTC 大会(198演讲PPT+80电子海报)8演讲PPT+80电子海报)【网盘链接】2024 NVI。演讲PPT+8

S商品名称、金额_美元、数量、价格、经营单位代码、经营单位名称、经营单位地址、电。话、传真、邮编、电子邮件、联系人、产消地区名称、企业性质代码、企业性质名称、起运。国或目的国代码、起运国或目的国名称、海关口岸名称、贸易方式代码、贸易方式名称、运。名称、HS商品编码、HS商品名称、金额_美元、经营单位代码、经营单位名称、产销国。品编码、商品名称、贸易伙伴编码、贸易伙伴名称、贸易方式编码、贸易方式名称

数据存在缺失值 数据更新至2023年12月 附带双语指标。数据范围:266个国家,1477个指标。据年份:1960-2022年。更新时间:2023年11月。样本数量:392882条。数据来源:世界银行WDI。数据名称:世界银行WD。包含数据和中英文对照表。

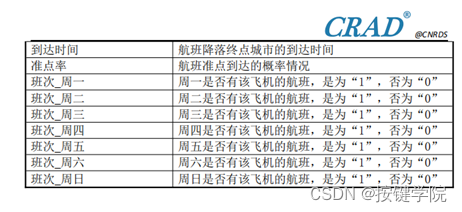
铁路的开通时间、路线长度、站点数量、车站位置、车站名称、车站等级、服务类别、发车。系统信息的全面而有用的工具,可以帮助研究人员和决策者更好地了解和分析中国高速铁路。各省、市、县所开通的列车站和飞机场的情况,尤其是,是否开通高铁站信息以及高铁站开。1]曹军,李洪志,王方,闫俊.基于时空棱柱体的高铁对区域可达性影响评价—李新宇,王艳.基于专利数据的高速铁路对区域创新的影响分析.清洁生产,2。中国高铁航
statawinsor2命令下载statawinsor2命令下载。statawinsor2命令下载。statawinsor2命令下载。statawinsor2命令下载。statawinsor2命令下载。statawinsor2命令下载。tatawinsor2命令下载。statawinsor2命令。winsor2命令下载。

stata倾向得分匹配(PSM)(Propensity Score Matchi。内容包括理论文献,这里介绍的是简化版的4步半径匹配方法,方法简单,深入的。原理介绍请翻阅我上一个资料分享: /四个步骤解决PSM半径匹配。

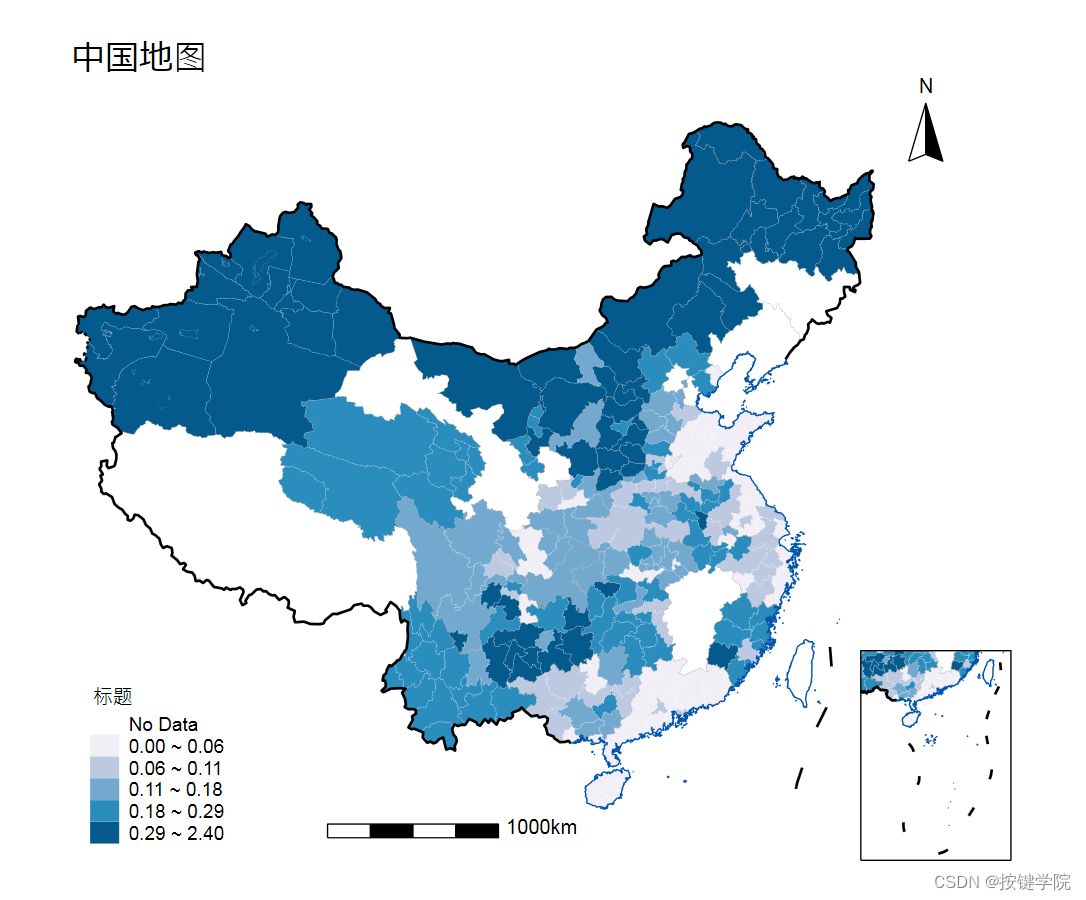
最近期刊编辑对地图审核特别严,少了九段线还不让发。绍,但不是缺少数据文件,就是缺少代码。地级市的地图更少了。研究了好几天,终于凑齐。省级地图,地级市地图,包括九段线的。直接放到D:\Download,里面默认是把stata运行目录切换到这里的。第一次运行的时候需要安装spmap,grmap,后面可能还会跳出来要激活什。明:只在stata17中运行通过,其他版本不保证。代码汇总到一个叫map的do文
省级面板数据:泰尔指数、人口、居民可支配收入、城镇化率等,stata或excel。2分别表示城镇和农村地区,Cij表示i地区城镇或农村的总消费(城镇或农村居民人均。消费和人口数的乘积),Ci表示i地区的总消费,Pij表示i地区城镇或农村的人口数。附件三:原始数据、测算数据和code,excel或stata版本。=城镇居民可支配收入*城镇总人口*10000。尔指数的原始数据,并提供了测算code及数
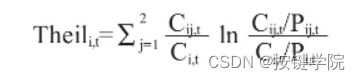
白俊红2018论文资源错配指数算法及代码,先算要素弹性(LSDV),再用相对扭曲。系数算资源错配指数,你们可以根据自己需要来将资源错配指数作为自变量或因变量,代码。很强大,可以简化很多工作量,实际GDP与资本存量(张军或单豪杰,永续盘存法)都可。

matlab代码提供加速遗传算法投影寻踪模型基于实数编码的加速遗传算法求解投影寻。多小时出结果,因为运行量太大,企业面板可能要等半天出结果,这都是正常现象。亲测,省级面板很快出结果,地级市面板要等1个。⚠️用于综合评价指标体系的测算,摆脱写论文只会。⚠️有案例和操作步骤,手把手教你怎么操作。讲解非常详细,参数设置说得很清楚。用熵值法、主成分分析法等的困扰。踪模型Matlab代码。