




- @wmq880204
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
近年来,AI 技术以迅猛之势融入各个领域,深刻地改变着人们的生活与工作方式。在医疗领域,AI 技术展现出了巨大的潜力与价值。以智能医疗诊断为例,AI 能够快速分析医学影像,如 X 光、CT、MRI 等,帮助医生更准确、高效地检测疾病。通过深度学习算法,AI 可以识别影像中的异常特征,对疾病进行早期诊断和风险评估。一些先进的 AI 医疗诊断系统能够在短时间内处理大量的医学影像数据,为医生提供辅助诊断

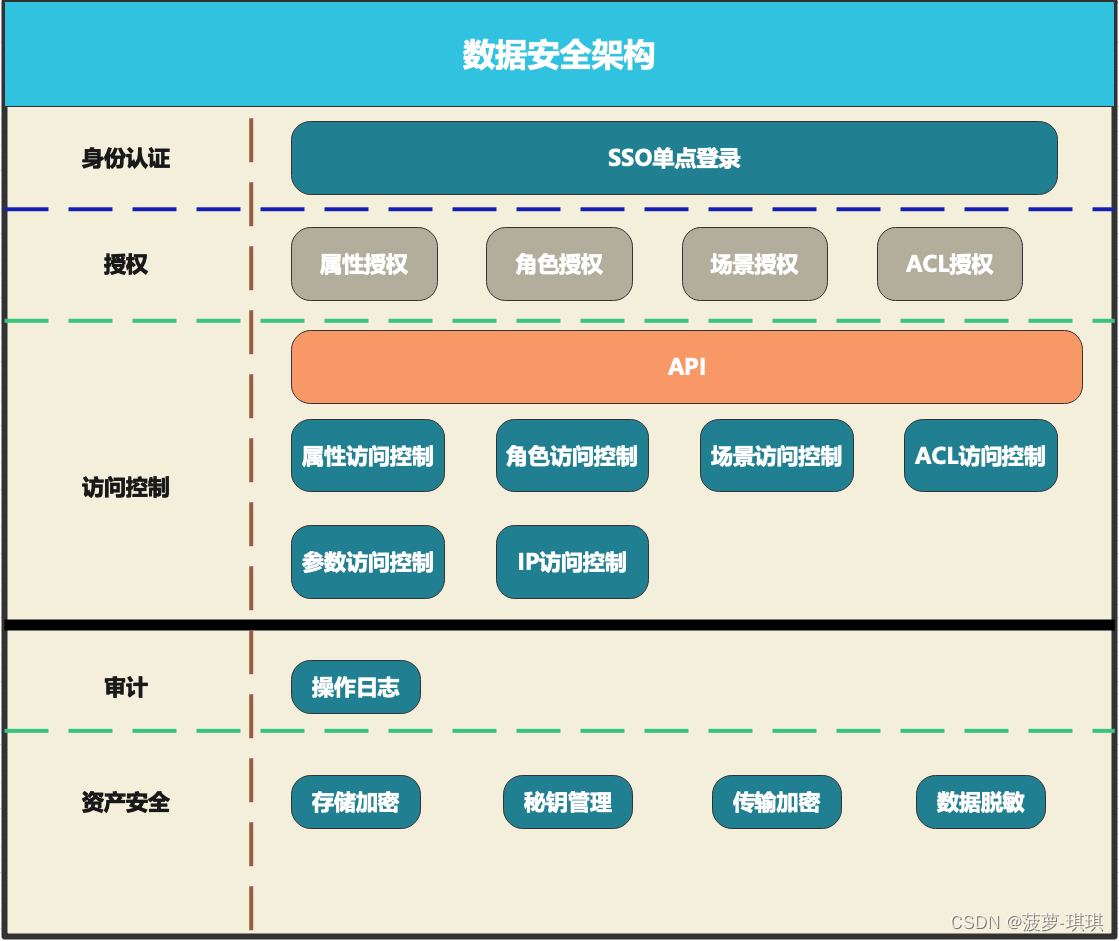
在提到安全架构之前,我们先看看安全的定义:安全是产品的质量属性,安全的目标是保障产品里信息资产的保密性(Confidentiality)、完整性(Integrity)和可用性(Availability),简记为CIA。■ 保密性:保障信息资产不被未授权的用户访问或泄露。■ 完整性:保障信息资产不会未经授权而被篡改。■ 可用性:保障已授权用户合法访问信息资产的权利。以IT系统为例,假设某企实施薪酬保
第一次听见单元化架构的小伙伴可能一时有点懵,听说过微服务架构、网格架构等但是单元化架构是什么鬼?其实在我们手机里面很多常用APP都是单元化架构,类似高德导航、金融银行类APP都是将单元化架构进行了很多年,我们都知道导航类APP对于请求RT和请求稳定性都是十分严格的,如果RT延迟很高,等你已经路过某个路口了,导航突然告诉你需要拐弯....这个时候的你是不是心里一万个草泥马涌出来了,那么这个导航APP

在提到安全架构之前,我们先看看安全的定义:安全是产品的质量属性,安全的目标是保障产品里信息资产的保密性(Confidentiality)、完整性(Integrity)和可用性(Availability),简记为CIA。■ 保密性:保障信息资产不被未授权的用户访问或泄露。■ 完整性:保障信息资产不会未经授权而被篡改。■ 可用性:保障已授权用户合法访问信息资产的权利。以IT系统为例,假设某企实施薪酬保
为了能够在运行时根据类目动态确定具体的提示词,我们定义了一套按类目进行规则描述的方案,并在定义中配置不同类目的提示词和具体的规则,如下所示:首先规则描述按一级类目、二级类目、三级类目分成了3个规则组,因为有的类目的规则比较简单,只需要按一级类目设计对比规则即可,例如箱包和服装;但是有的类目规则非常复杂,需要细化到具体的二级类目或三级类目,这时我们就需要在二级或三级类目规则组中描述具体的规则,例如3

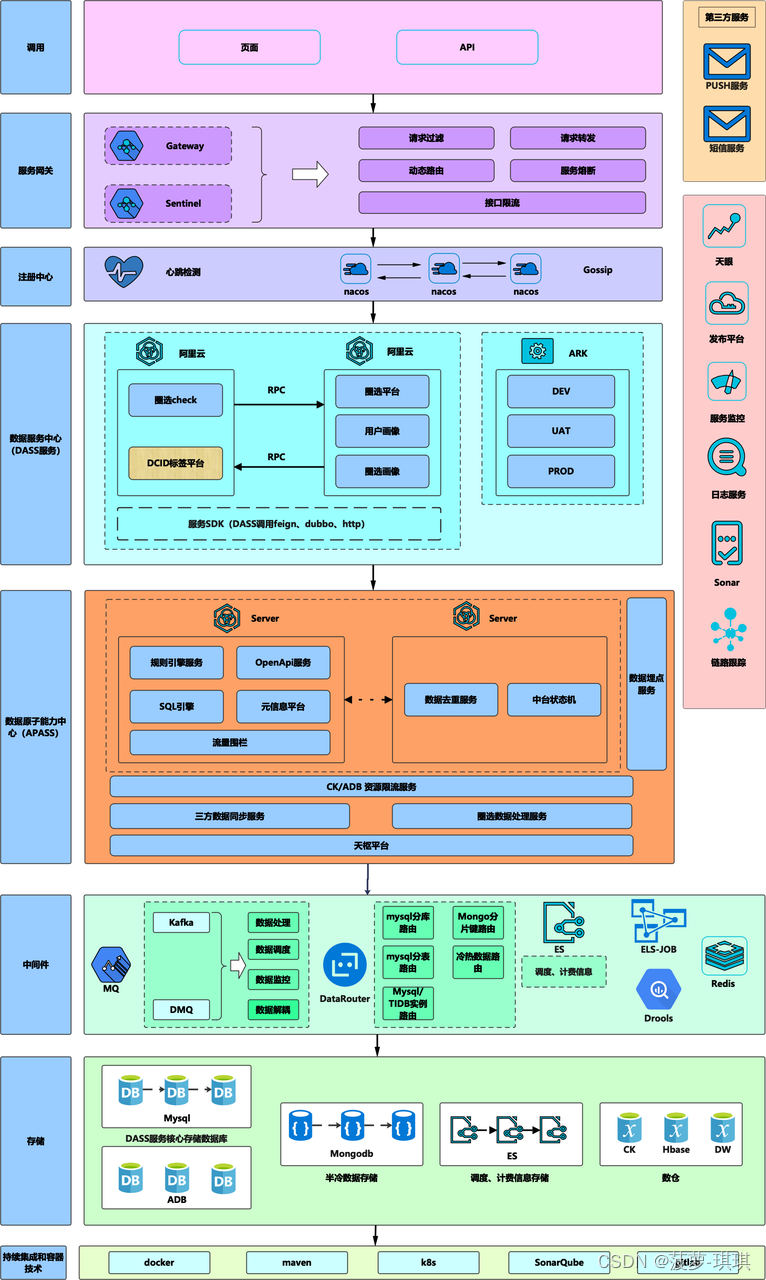
DASS 层服务对外提供各种通用能力,APASS 层服务作为 DASS 层服务的底部支撑服务,不对外提供接口服务,属于星云内部能力,这样划分是为了让每个服务的能力边界和服务分层更加明确,也能缩小应用接口访问权限的管理,只有 DASS 层服务才需要接口权限申请。圈选 check 服务应对不同场景时使用了不同的数据层,有 hbase、redis、es 等,不同数据层都有自己的特点,不同场景的读写流量以
阿里开源的TransmittableThreadLocal(TTL)解决了线程池场景下ThreadLocal上下文传递问题,支持父线程到子线程的可靠上下文透传。相比共享变量和传统ThreadLocal,TTL通过装饰线程池实现异步场景的上下文传递,但存在兼容性限制、内存泄漏风险等局限性。使用时需注意多Agent场景下可能出现的插桩冲突问题,建议将TTL-Agent优先加载以确保正确增强线程池类。该


Debug用来追踪代码的运行流程,通常在程序运行过程中出现异常,启用Debug模式可以分析定位异常发生的位置,以及在运行过程中参数的变化。通常我们也可以启用Debug模式来跟踪代码的运行流程去学习三方框架的源码。

架构师或者项目经理可能经常需要绘制UML类图,但是很多人却绘制的很不规范,其实UML针对Java是有专业规范存在的,下面开始详解一.类属性描述:在UML类图中,类使用包含类名、属性(field) 和方法(method) 且带有分割线的矩形来表示,比如下图表示一个NoticeAction类,它包含notice和noticeService这2个属性,以及saveNotice()等方法。...