




- @wild_ghosts
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
解决方案我们先观察下真实的开票预览的模板。很明显的一个主子结构。了解了一下iTextPdf的相关api。要实现这个功能,其实我们需要分别生成两部分的发票信息,也就是两个pdf,然后将两个pdf拼接成同一个。对于第一部分的固定信息,我们可以用Acrobat之类的pdf设计工具设计出一个模板,然后在java程序中读取并填充对应的模板值。对于第二部分的商品信息,就需要获取商品数据,动态生成表格,当然iT
map_merged (静态) -> robotX/map (由gmapping发布的map->odom变换) -> robotX/odom (静态) -> robotX/base_footprint -> …静态robot_state_publisher:launch发布base_footprint到base_link,以及base_link到其他各传感器连杆的变换。静态static_trans
剪枝(Pruning)是一种模型压缩技术,旨在通过移除神经网络中不重要的权重或神经元来减少模型的大小和计算复杂度,同时尽量保持模型的性能。
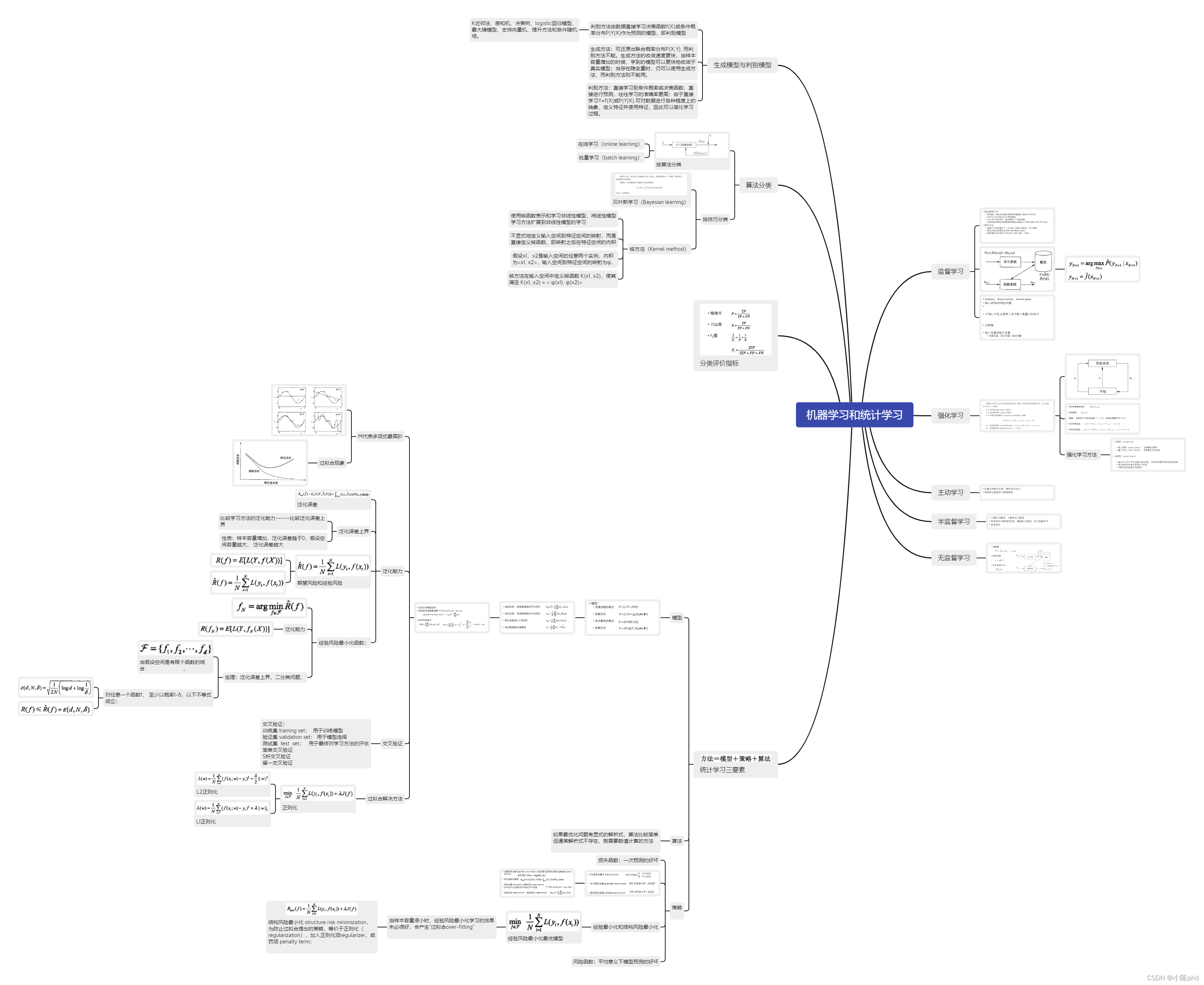
1.统计学习是关于计算机基于数据构建概率统计模型并运用模型对数据进行分析与预测的一门学科。统计学习包括监督学习、非监督学习、半监督学习和强化学习。2.统计学习方法三要素——模型、策略、算法,对理解统计学习方法起到提纲挈领的作用。3.本书主要讨论监督学习,监督学习可以概括如下:从给定有限的训练数据出发, 假设数据是独立同分布...
以plus开头的方法都是属于HTML5+环境调用的方法。plus不能在浏览器环境下使用,它必须在手机APP上才能使用,因为以安卓为例,他是操纵webview的API。在5+中,我们在使用plus之前要监听HTML5+环境是否已经加载完毕,而在uniapp中,则可以直接调用,可以参看uni-app使用plus注意事项。
formdbsetting > formdbinfo:存放包含卡片信息的Info.ets文件,可在Info.ets文件中,添加卡片刷新所需要的具体的数据,后续会读取该文件并将数据存入数据库中。卡片数据交互:触发卡片页面刷新。formhttpsetting > formhttpinfo:存放包含卡片信息的Info.ets文件,可在Info.ets文件中添加获取卡片刷新数据的URL。HarmonyOS
华为开发者空间是华为云为全球开发者打造的专属云上成长空间,空间深度整合了昇腾AI、鸿蒙、鲲鹏等华为根技术。2025HDC大会上,华为开发者空间迎来全面升级,新增AI原生应用引擎、AI Notebook、云开发环境、FunctionGraph云函数、Astro低代码等核心能力,并在算力、模型、平台、应用层实现全方位优化,助力开发者高效完成从编码到调测的全流程,打造智能AI应用开发新体验。华为开发者空
华为开发者空间是为全球开发者打造的专属云上成长空间,深度整合昇腾AI、鸿蒙、鲲鹏等华为根技术。开发者空间在HDC2025上迎来全面升级,新增AI原生应用引擎、AI Notebook、鸿蒙云手机、FunctionGraph云函数、Astro低代码等核心能力,并在算力、模型、平台、应用层实现全方位优化,助力开发者高效完成从编码到调测的全流程,打造智能AI应用开发新体验。智能助手模板是基于AI大模型定制
仓颉编程语言作为一款面向全场景应用开发的现代编程语言,通过现代语言特性的集成、全方位的编译优化和运行时实现、以及开箱即用的 IDE工具链支持,为开发者打造友好开发体验和卓越程序性能。案例结合代码体验,帮助大家更直观的了解仓颉语言中包的定义和导入和异常处理知识。异常不属于程序的正常功能,一旦发生异常,要求程序必须立即处理,即将程序的控制权从正常功能的执行处转移至处理异常的部分。仓颉编程语言提供异常处
最近比较忙,除了工作节奏调整,有重点项目需要跟。业务时间,也因为参加了25年创新大赛,我们网友,组成了鸿蒙超新星研发团队,经过两个月的人员加入和磨合,现已分为三个元服务小组,两个应用小组,正式参加了比赛。团队多来自全国各地的校园开发者,例如上海交大的博士同学。当然为保证项目贴近行业技术前沿,也邀请了来自大厂的开发者加入,帮忙进行项目框架的搭建和前沿鸿蒙技术的调研。其中BONNET小组负责开发的应用