




- @weixin_69558614
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
vim ~/.bashrc,添加 export PATH="/mnt/h/softwore/sratoolkit.3.0.7-ubuntu64/bin/:$PATH" ,保存退出后,source ~/.bashrc,激活。在SRA数据库中可以找到很多的测序数据,可以在网页中搜素,找到自己感兴趣的数据,同时在SRA中搜索数据的方式方法也有很多,大家可以自学一下,最终找到自己感兴趣的数据。在NCBI的
这是这本书,第四章第五节的内容,这一部分是以NGS检测肿瘤基因突变为例,描述了其原理和大概流程,这和以前我分享的病原宏基因组高通量测序性能确认方案可以互相补充,大家可以都看一下,但是想要真正的弄懂,还需要参与具体的项目。

数据库试运行合格后,数据库开发工作基本完成,即可投入正式运行了。但由于应用环境不断变化,数据库运行过程中物理存储也不断变化,对数据库设计进行评价、调整与修改等维护工作是一个长期的任务。在数据库运行阶段,对数据库经常性的维护工作主要是由数据库管理员 DBA 完成的。数据库的维护工作包括4个方面。

使用"ls SRR*"查找以"SRR"开头的文件,然后使用"while read id"逐行读取这些文件名,对每个文件执行以下操作:使用。--localmem=15:指定本地内存的使用量,单位为GB。raw_feature_bc_matrix:原始barcode信息,未过滤的可以用于构建矩阵的文件,可以不看;这是我最近跑的一个流程,说实在的,博大精深,以后我会看一些文献,分享一下,流程好跑,背景知

所以这里大家需要记住一个重点,PCR扩增原本的目的是为了增大微弱DNA序列片段的密度,但由于整个反应都在一个试管中进行,因此其他一些密度并不低的DNA片段也会被同步放大,那么这时在取样去上机测序的时候,这些DNA片段就很可能会被重复取到相同的几条去进行测序,但是由同一个模板分子扩增出来的重复子文库只对应单一模板,在分析过程中应将重复片段予以去除。因此,我们需要先把这一大堆的短序列捋顺,一个个去跟该
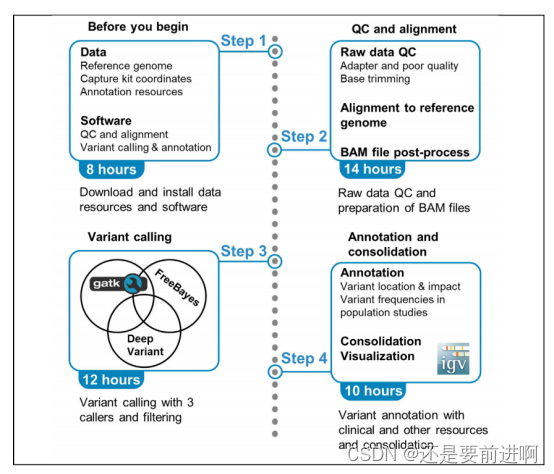
数据库试运行合格后,数据库开发工作基本完成,即可投入正式运行了。但由于应用环境不断变化,数据库运行过程中物理存储也不断变化,对数据库设计进行评价、调整与修改等维护工作是一个长期的任务。在数据库运行阶段,对数据库经常性的维护工作主要是由数据库管理员 DBA 完成的。数据库的维护工作包括4个方面。