- @weixin_68710508
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文探讨了进程、线程和协程的区别,并解释为何Python多线程可能比单线程更慢。进程是资源隔离的独立单位,拥有独立内存空间,创建和切换成本较高;线程共享进程资源,更轻量但存在竞态条件风险。Python受GIL(全局解释器锁)限制,多线程在CPU密集型任务中无法真正并行,仅适用于I/O密集型场景。建议根据任务类型选择并发模型:CPU密集型用多进程(如PyTorch DataLoader),I/O密集
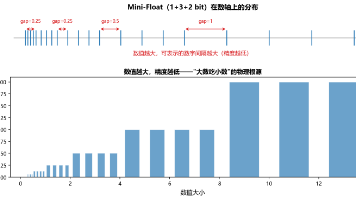
本文解析了AI训练中的数值精度选择问题,重点对比了FP16、BF16和FP32三种浮点格式。主要内容包括: 浮点数原理:采用IEEE 754标准,由符号位、指数位和尾数位组成,数值越大精度越低,会导致"大数吃小数"现象。 精度选择: FP16(5位指数)容易溢出,需Loss Scaling BF16(8位指数)截断FP32,保持动态范围,更适合神经网络训练 FP32精度最高但计
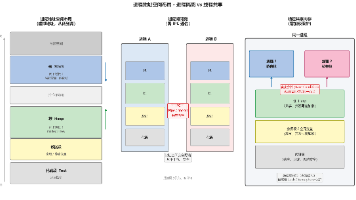
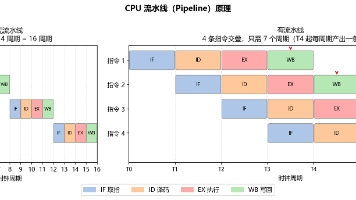
文章摘要: CPU和GPU的设计哲学截然不同:CPU通过复杂控制逻辑(流水线、分支预测)优化单线程性能,而GPU牺牲控制单元换取海量计算核心。GPU采用SIMT执行模型,线程以warp(32线程)为单位同步执行,分支语句会导致warp divergence大幅降低效率。Tensor Core是专为矩阵运算设计的硬件单元,通过TF32格式在保持FP32接口的同时提升计算速度。CPU与GPU通过PCI
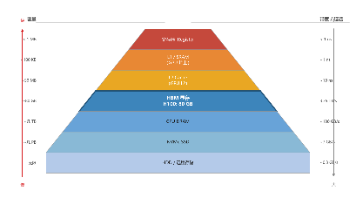
摘要: GPU训练效率低下的核心瓶颈在于数据搬运,而非算力不足。计算机存储呈金字塔结构,从寄存器到HBM显存,速度逐级下降而容量增大。GPU的HBM带宽虽高达3.35TB/s,但相比其算力仍有295倍差距,导致99%时间在等待数据(Memory-Bound)。数据搬运存在两道关口:GPU内部HBM瓶颈和CPU→GPU的PCIe传输瓶颈(仅64GB/s)。算术强度(FLOP/Byte)和Roofli