




- @weixin_62735356
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提供了在Google Colab上快速搭建大模型的入门指南。使用HuggingFace transformers库和Qwen2.5-7B-Instruct模型,通过4位量化技术解决显存不足问题。详细介绍了从环境配置、模型加载到实现对话交互的全流程,包括单轮问答和多轮对话的实现方法。重点讲解了量化技术、模型生成参数调优以及对话历史管理,帮助新手理解大模型应用的底层逻辑。文章还指出了Colab免费
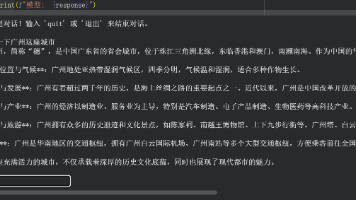
本文提供了在Google Colab上快速搭建大模型的入门指南。使用HuggingFace transformers库和Qwen2.5-7B-Instruct模型,通过4位量化技术解决显存不足问题。详细介绍了从环境配置、模型加载到实现对话交互的全流程,包括单轮问答和多轮对话的实现方法。重点讲解了量化技术、模型生成参数调优以及对话历史管理,帮助新手理解大模型应用的底层逻辑。文章还指出了Colab免费
而早停的操作在于通过监控一个验证指标(如验证集损失、准确率等),当该指标在一定数量的训练周期内不再改善时,提前终止训练。模型在训练集上的性能通常会随着训练的进行而提升,但在验证集上可能会出现先上升后下降的情况,这意味着模型开始过拟合。4. 保存最佳模型:每次有明显改善的时候,就记录model的参数,确保早停时模型能够重新载入最新的最佳的模型参数。2. 设置delta参数:如果指标的改善在delta
而早停的操作在于通过监控一个验证指标(如验证集损失、准确率等),当该指标在一定数量的训练周期内不再改善时,提前终止训练。模型在训练集上的性能通常会随着训练的进行而提升,但在验证集上可能会出现先上升后下降的情况,这意味着模型开始过拟合。4. 保存最佳模型:每次有明显改善的时候,就记录model的参数,确保早停时模型能够重新载入最新的最佳的模型参数。2. 设置delta参数:如果指标的改善在delta
通常做法是引入一个叫做RevIN(Reversible Instance Normalization,可逆实例归一化)的层。

而早停的操作在于通过监控一个验证指标(如验证集损失、准确率等),当该指标在一定数量的训练周期内不再改善时,提前终止训练。模型在训练集上的性能通常会随着训练的进行而提升,但在验证集上可能会出现先上升后下降的情况,这意味着模型开始过拟合。4. 保存最佳模型:每次有明显改善的时候,就记录model的参数,确保早停时模型能够重新载入最新的最佳的模型参数。2. 设置delta参数:如果指标的改善在delta