- @weixin_60702646
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2024年AIAgent企业应用现状与趋势 AIAgent加速商业化落地,超60%企业已部署应用,金融(渗透率35%)、科技互联网(28%)、零售电商(22%)三大行业领先。十大高频场景包括智能客服(解决率75%-85%)、文档处理(效率提升8倍)、数据分析(响应速度提升10倍)等,其中金融业以智能客服和风控为核心,制造业预测性维护降低故障率30%。ROI分析显示,典型客服中心人力成本可降40%-
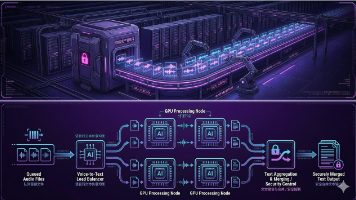
灵声智库政务智能体白皮书摘要 在政务智能化趋势下,灵声智库提出“ASR流式转写+本地LLM+语义RAG”三位一体架构,解决12345热线高并发、低延迟、高准确率的诉求。系统通过容错语义RAG(拼音+语义双向量对齐)提升召回率42%,流式滑动推理将响应时间压缩至600毫秒内,并采用任务感知调度器优化算力分配,确保高并发稳定性。 某直辖市12345热线实测显示,系统端到端响应仅550~720毫秒,工单

针对局域网环境下的语音数据处理刚需,本文复盘了开源语音大模型(如 funasr)在生产环境落地时的 API 并发、硬件显存及业务层缺失等工程踩坑实录。并分享一套开箱即用的「灵声智库」私有化部署方案,提供标准化 RESTful API,支持极低 VRAM 占用下的离线语音转文字与 AI 摘要,助力研发团队低成本快速交付过等保项目。
摘要: 随着AI技术的快速发展,语音识别离线部署成为政务、金融、医疗等敏感行业的首选方案。本文探讨了离线部署的核心优势,包括数据隐私安全、低延迟响应和国产化适配,并介绍了灵声智库的技术方案。其高精度算法、轻量化设计和多端适配能力,为企业构建了安全高效的语音识别系统。结合大模型应用,离线语音识别实现了全链路本地化智能交互,在智慧法院、医疗等领域已有成功案例。未来,离线部署将成为企业数字化转型的必选标
然而,医疗数据的极高敏感性,要求任何 AI 技术的落地都必须在绝对安全的物理边界内完成。## 1. 门诊导诊:从“听得见”到“分得清”在嘈杂的门诊大厅,传统的通用识别引擎往往效果不佳。智慧医疗的未来,不仅在于算法的领先,更在于对安全与隐私的坚守。提供的语音质检方案,能够将护士站的通话记录批量转为文本,并利用大语言模型(LLM)进行合规性分析。的医疗专用 ASR 引擎,医生只需口述内容,系统即可自动
筑牢数据安全护城河:千亿参数 AI 语音识别如何实现 100% 离线深网部署?

开源智能体OpenClaw因能接管PC系统执行复杂任务引发热议,但政企应用面临数据安全、离线环境、算力成本三大痛点。通过结合灵声智库全离线架构,可实现:1)本地大模型替代云端API;2)离线语音转写与智能分析;3)算力买断降低成本。建议企业先夯实数据安全基础,从边界清晰的场景逐步验证,在合规前提下探索AI应用。技术落地需平衡创新与安全,私有化部署是关键。

企业级AI语音识别私有化部署面临开源模型选型难题,Whisper与FunASR各具特点。Whisper虽在多语种识别上表现优异,但其自回归架构导致延迟高、显存需求大,且存在"AI幻觉"风险。相比之下,FunASR采用非自回归架构实现高速推理,专为中文场景优化,提供完整的工业级流水线设计。灵声智库基于FunASR打造的全离线解决方案,在医疗、政务等场景实现了毫秒级响应、高并发处理

文章摘要:随着AI深入企业级应用,云端语音API的局限性日益凸显,包括数据隐私风险、网络瓶颈和运维成本高等问题。本地语音识别部署成为企业核心业务的新选择,但面临显存焦虑、长音频处理和并发调度等技术挑战。灵声智库提供全离线解决方案,包括优化本地推理引擎、ASR+TTS闭环和私有声音克隆技术,帮助企业实现安全高效的语音AI私有化部署。这种"本地语音引擎+私有大模型"的架构正成为行业
企业海量语音转写的工程挑战与离线解决方案 面对万小时级的语音转写需求,云端API存在成本高、限流严、合规风险大等硬伤,而本地开源模型部署常因显存溢出、长音频处理不当导致系统崩溃。灵声智库通过全离线架构实现突破:采用VAD精准切片技术保障长音频处理,动态并发机制最大化算力利用率,集成ITN引擎提升输出质量。该方案在数据安全前提下,以零边际成本完成批量转写,释放企业历史语音数据的商业价值,为构建本地化