
写文章




- @weixin_59980799
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
TNT- Target-driveN Trajectory Prediction.论文阅读笔记
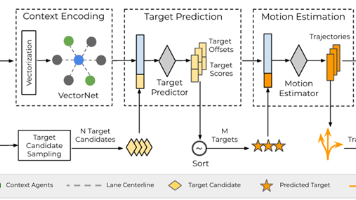
预测移动体的未来行为在真实世界应用中至关重要,但这一任务极具挑战性,因为智能体的意图及其对应的行为是未知的,并且本质上具有多模态特征。我们的核心见解是:在中等时间范围内,未来的多模态轨迹可以通过一组目标状态有效地捕捉。基于这一思路,我们提出了目标驱动的轨迹预测(TNT)框架。TNT 包含三个阶段,并可进行端到端训练:首先,通过编码智能体与环境及其他智能体的交互,预测其在未来 T 步可能的目标状态;
MM-Embed- Universal Multimodal Retrieval with Multimodal LLMs. 论文阅读笔记
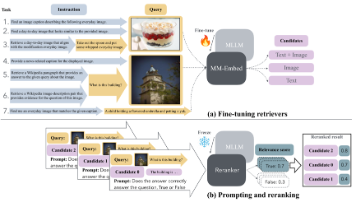
本文提出了一种基于多模态大语言模型(MLLM)的通用多模态检索系统MM-Embed。针对现有检索模型在跨模态任务中的局限性,作者创新性地采用LLaVa-Next等MLLM构建双编码器检索器,并提出模态感知的困难负样本挖掘方法,有效缓解了MLLM的模态偏差问题。通过对比学习训练和指令驱动设计,模型能够处理文本、图像及其组合形式的复杂查询。实验表明,MM-Embed在MBEIR多模态基准上取得SOTA
CogVLM- Visual Expert for Pretrained Language Models. NIPS 2024 CogVLM:预训练语言模型的视觉专家 论文阅读笔记
我们介绍CogVLM,一个强大的开源视觉语言基础模型。与流行的浅层对齐方法不同,后者将图像特征映射到语言模型的输入空间,CogVLM通过在注意力层和全局注意力层中引入可训练的视觉专家模块,弥合了预训练语言模型与图像编码器之间的差距。因此,CogVLM实现了视觉语言特征的深度融合,同时在自然语言处理任务上不牺牲任何性能。
到底了