




- @weixin_58910029
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
GAN(生成对抗网络)是一种深度学习框架,通过两个神经网络的博弈过程实现图像生成任务。其核心设计由生成器和判别器组成,二者以对抗训练的方式相互优化,最终使生成器能够输出高度逼真的图像。这种模型的创新性在于将生成问题转化为动态博弈问题,而非传统的单一损失函数优化。生成器的任务是接收随机噪声或潜在向量作为输入,通过多层非线性变换将其映射到图像空间。初始阶段的生成图像通常质量较低,但随着训练推进,生成器
【代码】基于MindSpore框架实现PWCNet光流估计。
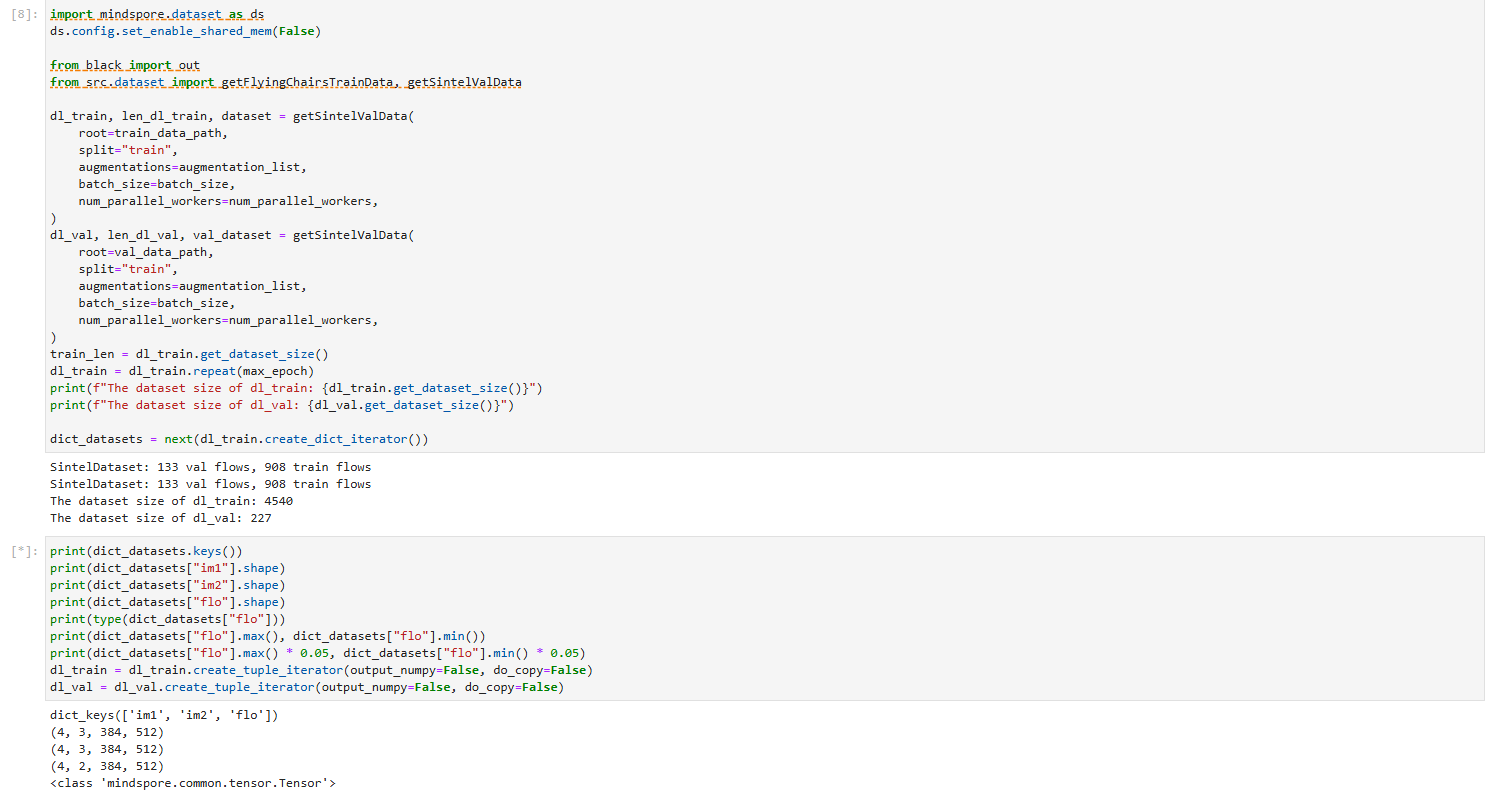
SqueezeNet是2016年由DeepScale联合加州大学伯克利分校和斯坦福大学提出的一种轻量级卷积神经网络,其核心设计理念是通过结构化创新实现模型参数的极致压缩,同时保持与AlexNet相当的图像分类精度。该网络最显著的特点是将模型参数量从AlexNet的240MB压缩至4.8MB,结合深度压缩技术后更可降至0.47MB,这种突破性设计使其成为移动端和嵌入式设备部署的标杆模型。网络架构层面
图像修复技术(ICT)的核心目标是通过算法重建图像中缺失或损坏的部分,使其在视觉上与原始图像保持自然和谐。这一过程结合了传统图像处理与深度学习技术,形成了多层次的实现框架。传统方法如基于扩散的修复,通过分析缺失区域边缘的像素梯度与颜色信息,逐步向内部填充内容。这种方法类似于在画布上从已知区域向未知区域延伸纹理,适用于小面积划痕或斑点修复。而纹理合成技术则通过采样图像其他区域的纹理特征,将相似结构拼
""""Args:""""""""""# 定位损失# 类别损失。
而 MobileNetV2 的倒残差结构则反向操作,先通过 1×1 卷积升维扩展通道数,再通过 3×3 深度可分离卷积高效提取特征,最后通过 1×1 卷积降维。通过深度可分离卷积与倒残差结构的结合,模型在保持低计算复杂度的同时,仍能提取丰富的特征信息,适用于图像分类、目标检测等任务。MobileNetV2 是谷歌于 2018 年提出的轻量化卷积神经网络模型,专为移动端和嵌入式设备设计,通过核心结构
基于MindSpore的SGD优化器实现体验记录
Vision Transformer(ViT)是一种将自然语言处理领域的Transformer架构成功迁移至计算机视觉任务的开创性模型,它突破了传统卷积神经网络(CNN)依赖局部感受野和层级抽象的范式,通过将输入图像分割为非重叠的图像块(patches)并线性嵌入为序列向量,直接模拟自然语言中的“词元”处理方式,再结合Transformer的自注意力机制捕捉全局空间关系,使得模型能够在不依赖卷积操