- @weixin_53004531
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
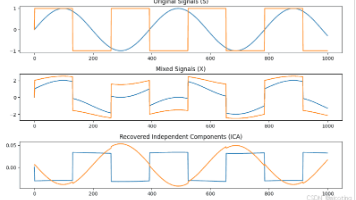
独立成分分析(ICA)是一种无监督降维方法,与PCA不同,ICA追求统计独立性而非相关性,能有效分离混合信号中的潜在独立成分。
特征工程是机器学习中将原始数据转化为有效特征的关键步骤,直接影响模型性能。其核心目标包括提取有效信息、减少冗余噪声、增强表达能力及提高训练效率。主要环节有特征选择、构造和降维。特征降维通过保留主要信息将高维数据映射到低维空间,常用方法包括PCA(主成分分析)、LDA(线性判别分析)、ICA(独立成分分析)以及非线性方法如t-SNE和UMAP。这些方法能降低计算成本、减少过拟合风险并提高模型效率。
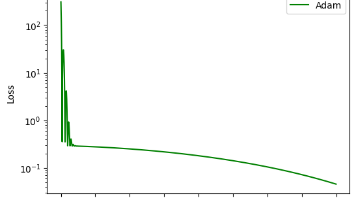
在神经网络的训练过程中,损失函数 ( Loss Function ) 决定了模型优化的方向。没有损失函数,神经网络就不知道该往哪里调整参数,也就无法真正学会任务。损失函数的设计不仅关乎模型能不能收敛,更直接影响最终的性能。
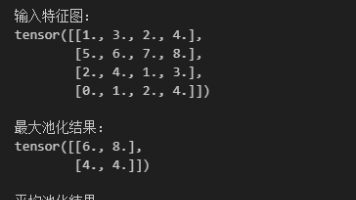
在卷积神经网络(CNN)中,卷积层用于提取图像或特征图的局部模式,而池化(Pooling)是卷积之后常用的一种下采样操作。池化可以降低特征图尺寸、减少计算量,并增强模型对位置和噪声的鲁棒性。下面从几个关键方面来介绍池化。
特征工程是机器学习中将原始数据转换为有效特征的关键步骤,直接影响模型性能。其核心目标包括提取有效信息、减少冗余、增强表达能力及提高训练效率。特征工程包含特征选择、构造和降维三个环节。特征选择方法分为三类:过滤法(基于统计指标)、包裹法(基于模型性能)和嵌入法(模型自带选择)。不同方法各有优劣,需根据数据特性和模型需求选择。特征工程与算法本身同等重要,能显著提升模型效果。

本文介绍了三种重要的概率图模型及其应用。高斯混合模型(GMM)通过多个高斯分布的线性组合实现软聚类和密度估计,适用于图像分割、异常检测等场景。隐马尔可夫模型(HMM)用于建模序列数据,能处理语音识别、基因分析等时序问题。贝叶斯网络则通过有向无环图表示变量间的条件依赖关系,在医疗诊断、风险评估等领域有广泛应用。这些模型结合概率论与图论,为复杂系统的建模和推断提供了有效工具。
这里是一个系统化的机器学习知识库记录我的学习与求职历程,也希望能帮助到更多正在学习或者准备 AI 岗位的同学。

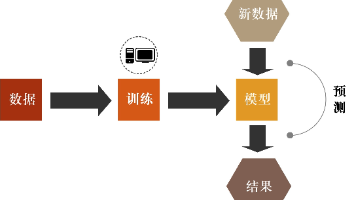
摘要 机器学习是人工智能的核心分支,通过数据驱动方法让计算机自动学习规律,实现预测、分类和决策。主要分为四类:监督学习(利用标注数据训练模型)、无监督学习(挖掘无标注数据的潜在模式)、半监督学习(结合少量标注与大量无标注数据)和强化学习(通过环境交互优化决策策略)。各类方法各有特点,可单独或结合使用解决实际问题,如医疗诊断、推荐系统、自动驾驶等。理解这些基础类型是掌握机器学习的关键。
特征构造是通过已有特征生成新特征以提升模型性能的过程,主要包括数值变换(多项式、对数变换)、类别编码(独热、目标编码)、时间特征(周期统计)、文本特征(词频、情感)和特征组合。合理构造特征能增强信息量、提高准确性,但需避免维度爆炸和过拟合。更多内容可关注公众号aicoting。
在 Linux 或 macOS 上,很多开发者喜欢使用 zsh + oh-my-zsh 来获得强大的命令补全、历史搜索和美化提示。在 Windows 上,我们也可以打造类似体验,利用 PowerShell 7 + Oh My Posh + PSReadLine + posh-git,并让 VS Code 终端完美适配。本文将详细介绍安装与配置步骤。