
AI训练中的混合精度计算技术详解
在大模型训练时代,模型参数规模动辄数百亿甚至上万亿,传统的 FP32 单精度训练 已经无法满足显存和速度的需求。混合精度(Mixed Precision Training)技术通过在保持模型精度的同时使用更低位数的浮点格式(如 FP16、BFLOAT16),有效减少显存占用、提升吞吐量,已经成为深度学习训练的“标配”。
📚AI Infra系列文章
在大模型训练时代,模型参数规模动辄数百亿甚至上万亿,传统的 FP32 单精度训练 已经无法满足显存和速度的需求。混合精度(Mixed Precision Training)技术通过在保持模型精度的同时使用更低位数的浮点格式(如 FP16、BFLOAT16),有效减少显存占用、提升吞吐量,已经成为深度学习训练的“标配”。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
希望大家带着下面的问题来学习,我会在文末给出答案:
- 混合精度计算是如何在不损失模型效果的情况下提升训练速度的?
- FP16 与 BFLOAT16 的区别与适用场景是什么?
- 在 PyTorch / TensorFlow 中如何正确开启混合精度训练?
1. 什么是混合精度计算?
混合精度计算是指在模型训练过程中,同时使用不同精度的浮点数(如 FP16 与 FP32)进行计算,以达到性能与精度的平衡。
- 低精度(FP16/BF16):加速矩阵乘法、卷积等计算,减少显存占用。
- 高精度(FP32):保留在梯度累积、权重更新等对数值精度敏感的环节,防止梯度下溢或损失收敛稳定性。
2. 常见低精度格式
| 格式 | 位数 | 指数位 | 尾数位 | 动态范围 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| FP32 | 32 | 8 | 23 | ~1e-38 ~ 1e+38 | 高精度 | 显存占用大,速度慢 |
| FP16 | 16 | 5 | 10 | ~1e-5 ~ 1e+5 | 显存减半,速度快 | 动态范围小,易下溢 |
| BFLOAT16 | 16 | 8 | 7 | ~1e-38 ~ 1e+38 | 动态范围与 FP32 接近,稳定性好 | 精度比 FP16 低 |
| TF32* | 19 (NVIDIA专用) | 8 | 10 | ~1e-38 ~ 1e+38 | 计算速度快,兼顾精度 | 仅支持 Ampere+ GPU |
其中TF32 是 NVIDIA 在 Ampere 架构上推出的矩阵计算格式。
3. 混合精度训练的原理
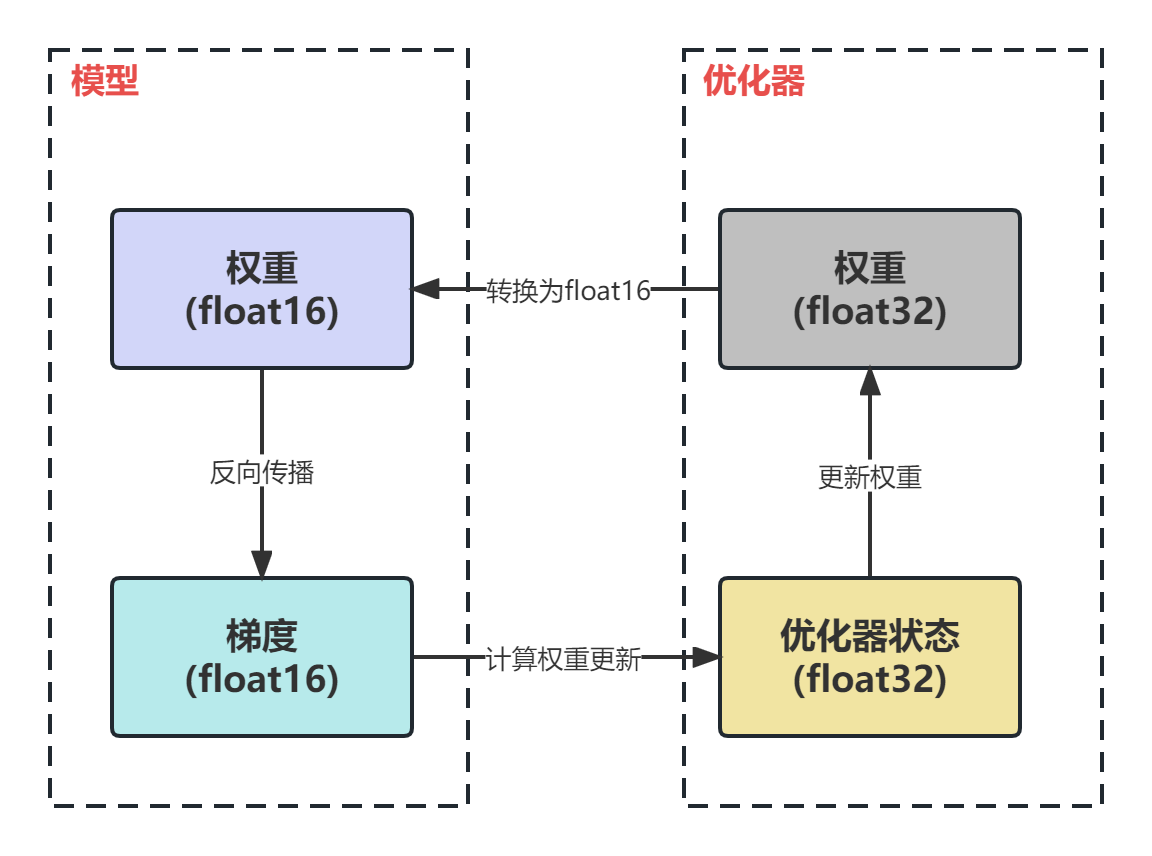
混合精度的核心是 计算与存储的分离:
- 计算阶段:大部分运算(如矩阵乘法、卷积)用 FP16/BF16 在 Tensor Core 上执行,加速显著。
- 存储阶段:模型权重、梯度累积等关键变量保留 FP32 精度,避免数值不稳定。
- 损失缩放(Loss Scaling):通过放大梯度值,减少 FP16 梯度下溢的风险。
4. 混合精度实现
PyTorch AMP(Automatic Mixed Precision)
import torch
from torch.cuda.amp import GradScaler, autocast
model = ...
optimizer = ...
scaler = GradScaler()
for data, target in dataloader:
optimizer.zero_grad()
with autocast(): # FP16 加速
output = model(data)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
TensorFlow Mixed Precision API
import tensorflow as tf
# 开启混合精度
policy = tf.keras.mixed_precision.Policy('mixed_float16')
tf.keras.mixed_precision.set_global_policy(policy)
model = ...
model.compile(optimizer='adam', loss='categorical_crossentropy')
model.fit(dataset, epochs=10)
混合精度的优势十分显著:显存占用减少近一半,训练速度在 Tensor Core 或 TPU 的加持下成倍提升,同时由于内存带宽和功耗压力降低,整体能效也随之提高。但在使用过程中仍需注意几个问题:一是 FP16 容易发生梯度下溢,因此必须搭配 Loss Scaling;二是硬件需要支持相应的计算格式,例如 Volta 及更新架构支持 FP16 Tensor Core,Ampere 及以上才支持 TF32;三是某些算子(如归一化或 softmax)对数值敏感,应保留 FP32 计算。
最后,我们回答一下文章开头提出的问题
- 混合精度计算是如何在不损失模型效果的情况下提升训练速度的?
通过低精度加速计算并减少显存占用,同时在关键步骤保留高精度计算保持数值稳定性。
- FP16 与 BFLOAT16 的区别与适用场景是什么?
FP16 精度更高但动态范围小,适合数值范围可控的任务;BFLOAT16 动态范围大,更稳定,适合超大模型训练。
- 在 PyTorch / TensorFlow 中如何正确开启混合精度训练?
PyTorch 使用 AMP + GradScaler,TensorFlow 使用 mixed_precision.Policy,并确保关键算子保留 FP32。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号 coting!
以上内容部分参考了 NVIDIA、Google 官方文档,非常感谢,如有侵权请联系删除。
更多推荐
 31
31 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)