- @weixin_49657774
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文对比分析了三种主流大模型本地部署方案(Ollama、vLLM、llama.cpp)的核心特点和适用场景。Ollama提供开箱即用的简易体验,适合个人开发者;vLLM专为高性能GPU环境设计,适用于企业级高并发场景;llama.cpp则以极致轻量化见长,能在边缘设备运行。选择指南建议根据用户类型(普通/企业/极客)和硬件条件(高性能GPU/普通PC/嵌入式设备)进行匹配,形成完整的本地部署生态解
DeepSeek-V4的发布,标志着AI真正进入了"平民化时代"。它不再是技术专家的专属玩具,而是每个人都能轻松使用的日常工具。现在就去试试吧!打开浏览器,输入chat.deepseek.com,开启你的AI新体验!本文基于2026年4月24日DeepSeek-V4预览版发布信息整理,内容会随版本更新而调整。官网:https://chat.deepseek.com技术报告:官网可下载社区讨论:各大

AI模型幻觉已成为商业领域重大风险,2024年造成全球674亿美元损失。研究表明: 行业现状严峻:AI生成虚假信息比例一年内翻倍至35%,法律、医疗等专业领域幻觉率高达15-18%,且模型错误时使用自信词汇概率高出34% 技术表现差异:领先AI模型中,Google Gemini系列幻觉率最低(0.7-1.1%),而Claude-3.5达4.6%,任务复杂度每提升一级幻觉率增加3-5倍 成因分析:幻
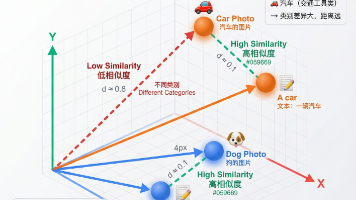
本文介绍了基于LlamaIndex框架的多模态视觉语义检索技术,重点探讨了从传统文档检索到跨模态检索的技术演进。文章分析了传统解决方案(文件名搜索、OCR提取、人工标签)的局限性,提出了多模态RAG的核心思想——统一向量空间,通过CLIP双编码器实现文本和图像在同一语义空间中的比较。技术架构分为四个演进阶段:基础(CLIP+Milvus)、进阶(VLM描述增强)、高级(Qwen3-VL黄金架构)和
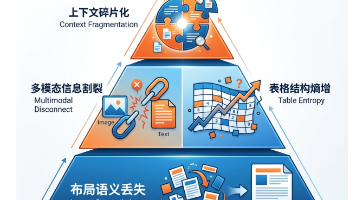
本文深入探讨了如何利用LlamaIndex框架解决图文混排PDF文档检索的难题。文章首先分析了企业数据现状,指出80%高价值信息被锁定在PDF中,并揭示了PDF格式的本质矛盾。随后详细阐述了四大技术挑战:布局语义丢失、多模态信息割裂、表格结构熵增和上下文碎片化。 技术方案部分提供了6步实战技术地图,对比了pypdf、PyMuPDF、LlamaParse和MinerU四种解析工具的优缺点。核心实现包
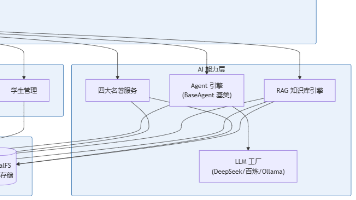
摘要: 某教育集团高中学生管理系统V2.0采用FastAPI+异步SQLAlchemy技术栈,深度融合AI能力,打造智能化管理平台。系统通过AI Agent架构解决传统管理痛点:数据孤岛、评价主观、家校沟通生硬等问题。核心创新包括AI自动评语生成、违纪处理话术教练、学业趋势分析及沉浸式文化学习体验。采用分层解耦设计,支持多模态存储和混合检索,效率较传统方式提升60倍。系统基于国产大模型,通过RBA
深入解析Milvus各种索引类型的区别、应用场景和关键参数调优,帮助您构建高性能的向量检索系统

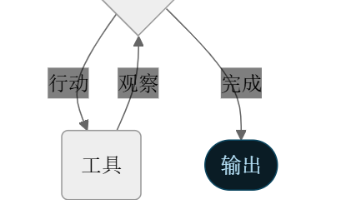
Agent记忆管理技术摘要 Agent记忆管理是AI智能体实现持续学习和个性化交互的核心能力,包含短期记忆和长期记忆两个层级。短期记忆绑定会话生命周期,用于维护对话上下文;长期记忆跨会话持久化,存储用户偏好和关键信息。技术实现上采用分层架构: 短期记忆通过内存缓存和Checkpointer机制实现 长期记忆依赖向量数据库进行语义化存储和检索 跨会话记忆通过BaseStore实现用户级状态管理 关键

本文对比分析了多Agent系统的6种核心通信模式:直接调用(同步RPC)、消息传递(异步队列)、共享状态(读写全局空间)、事件驱动(发布订阅)、黑板模式(知识库交互)和请求响应(同步等待)。通过架构图展示了各模式的工作机制,包括LangGraph、AutoGen等典型框架实现。作者Aipollo专注AI Agent工程化落地,提出不同通信模式适用于同步/异步、紧耦合/松耦合等场景,为构建复杂多Ag
Mem0框架是一个革命性的AI记忆系统,通过创新的双阶段处理流水线和智能记忆层架构,解决了当前AI系统的"记忆危机"。该系统采用持久化记忆存储、智能检索和动态更新机制,显著提升了AI助手的记忆准确性和交互连续性。相比传统方案,Mem0在准确率提升26%的同时降低了91%的延迟,并节省90%以上的token使用量。该框架为构建真正具备长期记忆能力的AI智能体提供了完整解决方案,成