




- @weixin_46483785
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在ar目录下运行。
注:平台为pycharm。

将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。注意:是链表。

【背景】高熵合金(HEA)因其优异的材料性能和近乎无限的设计空间而吸引了越来越多的研究。开发有效的相组成预测方法对于新型 HEA 设计非常重要。【机器学习作用】机器学习(ML)作为一种有效的数据驱动方法,为 HEA 的相位预测提供了一种可能的方法,【本文目的】但是,缺乏对各种 ML 模型的有效性和差异的澄清。【主要内容】本文收集了800多个HEAs物相数据,总结了16个特征。使用各种机器学习模型来

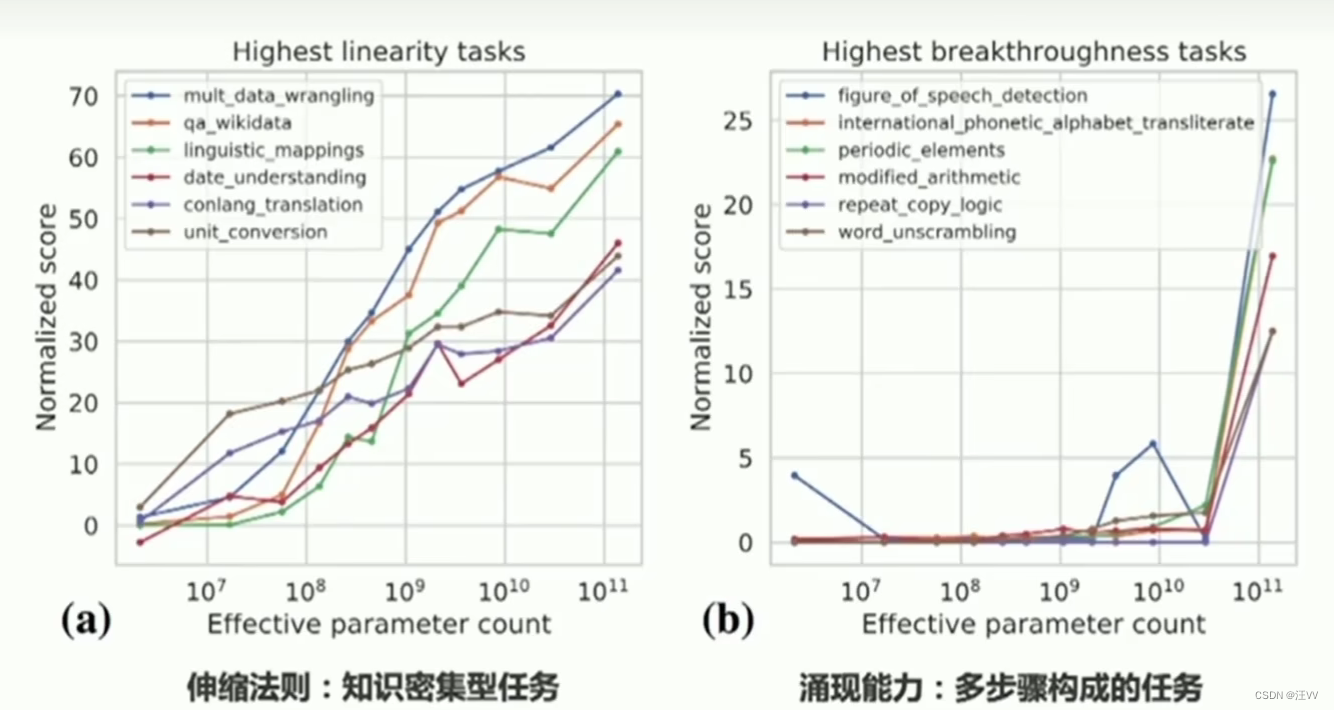
涌现: 许多小实体相互作用产生了大实体,大实体展现了组成它的小实体所不具有的特性大语言模型的规模效应:下游任务表现-伸缩法则&&涌现能力左侧任务:随着参数规模增大,知识的增长,效果越来越好右侧任务:涌现能力的一种体现,在参数规模小的时候体现一种随机性,看不出来有没有效果。大部分是由多步构成的一个复杂任务随着模型推大,效果一开始下降,当规模再增大时会上升,原因未知,但是这类任务加入COT就会转化为伸
注:平台为pycharm。
特点: MOF是一类由无机节点和有机连接器构成的特殊结构材料,此数据集用于分析模型对MOF结构中电子相关性质的预测。数据来源: Catalysis-Hub数据库,包括37,334个结构,涵盖了大约2,000种独特的金属合金表面。特点: 主要集中在纳米尺度,包含不同大小的纳米簇,可用于测试模型对于不同结构-能量映射关系的特征提取能力。数据来源: QMOF数据库,包括18,321个独特结构,既包括实验
然而,如果维度太低,可能会导致过拟合,模型在训练数据上表现良好,但在新数据上表现不佳。在高维数据中,模型可能更容易过拟合训练数据,即在训练数据上表现得很好,但在新数据上表现不佳。在实际应用中,应根据数据集的特点和问题的需求来确定合适的数据维度和样本数量。高维数据会导致计算复杂性的显著增加。例如,计算特征之间的距离、相似性或相关性时,随着维度的增加,计算量呈指数级增加,从而导致效率下降。高维数据中的
