




- @weixin_45919853
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
随之而来,使用绝对位置编码存在一个缺陷(以第一种为例):每个token的位置编码都是固定的,这意味着每个词的位置信息是独立的,无法灵活地体现不同“单词”之间的相对距离。每一层的自注意力机制会结合相对位置编码,进而增强模型的上下文理解能力,尤其在处理长序列时,Transformer-XL 可以显著减少计算开销,并提高模型对长距离依赖的建模能力。论文中给出的算法例子如上图所示。位置编码用于在输入序列中
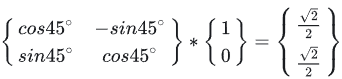
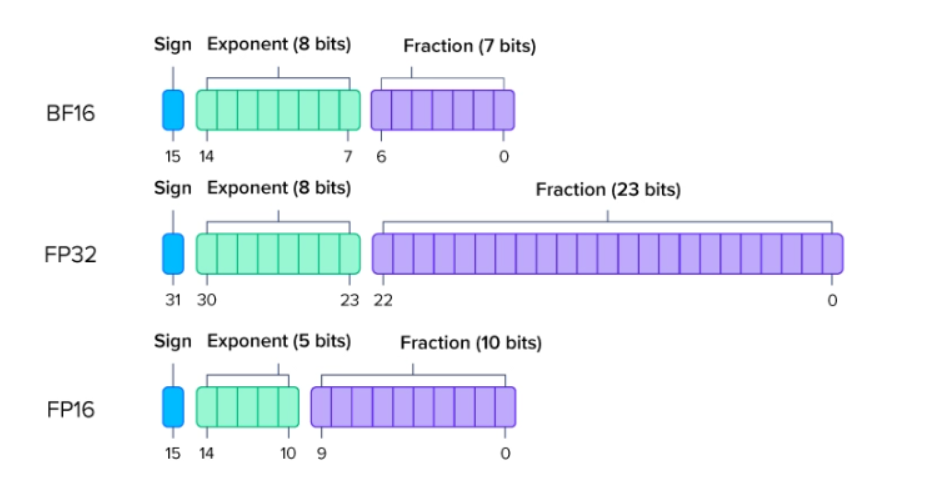
下图展示了 SSD 模型在训练过程中,激活函数梯度的分布情况,容易发现部分梯度值如果用FP16容易导致最后的梯度值变为0,这样就会导致上面提到的溢出问题,那么论文里面的做法就是:在反向传播前将loss增打。)指的是同时使用 FP16/BF16 和 FP32,利用二者的优点。也会导致溢出问题,梯度计算使用FP16,但在权重更新之前,梯度会转换为 FP32 精度进行累积和存储,从而避免因溢出导致的权重
*主要用于处理样本失衡问题(样本里面标签不平衡问题,比如说目标识别,可能会得到很多框,但是可能只要一个框是所需的),其原理也很简单可以直接在原交叉熵基础上补充一个。用于回归任务的损失函数,它结合了均方误差(MSE)和绝对误差(MAE)的优点,可以减少对异常值(outliers)的敏感性,同时保持较好的梯度性质。交叉熵损失用于分类任务,它度量的是预测概率分布与真实标签分布之间的差异。的匹配规则,原理

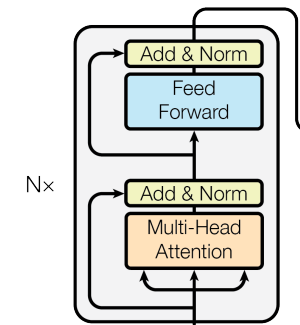
主要介绍Pytorch分布式训练代码以及原理以及一些简易的Demo代码是指将一个模型的不同部分(如层或子模块)分配到不同的设备上运行。它通常用于非常大的模型,这些模型无法完整地放入单个设备的内存中。在模型并行中,数据会顺序通过各个层,即一层处理完所有数据之后再传递给下一层。这意味着,在任何时刻,只有当前正在处理的数据位于相应的设备上。是一种特殊的模型并行形式,它不仅拆分模型的不同层,还将输入数据流

主要介绍Pytorch分布式训练代码以及原理以及一些简易的Demo代码是指将一个模型的不同部分(如层或子模块)分配到不同的设备上运行。它通常用于非常大的模型,这些模型无法完整地放入单个设备的内存中。在模型并行中,数据会顺序通过各个层,即一层处理完所有数据之后再传递给下一层。这意味着,在任何时刻,只有当前正在处理的数据位于相应的设备上。是一种特殊的模型并行形式,它不仅拆分模型的不同层,还将输入数据流
比如说按照上面Prompt要输出(假设只输出这些内容):“fathers brought a car”,一般的套路可能是:比如说:“Four score and seven years ago our xxxxx”(xxx代表预留空间)因为实际不知道到底要输出多少文本,因此会提前预留很长的一部分空间(但是如果只输出4个字符,这预留空间就被浪费了),因此在。因此,当计算每个位置的注意力时,键(key
随之而来,使用绝对位置编码存在一个缺陷(以第一种为例):每个token的位置编码都是固定的,这意味着每个词的位置信息是独立的,无法灵活地体现不同“单词”之间的相对距离。每一层的自注意力机制会结合相对位置编码,进而增强模型的上下文理解能力,尤其在处理长序列时,Transformer-XL 可以显著减少计算开销,并提高模型对长距离依赖的建模能力。论文中给出的算法例子如上图所示。位置编码用于在输入序列中
DeepSpeed。

比如说按照上面Prompt要输出(假设只输出这些内容):“fathers brought a car”,一般的套路可能是:比如说:“Four score and seven years ago our xxxxx”(xxx代表预留空间)因为实际不知道到底要输出多少文本,因此会提前预留很长的一部分空间(但是如果只输出4个字符,这预留空间就被浪费了),因此在。因此,当计算每个位置的注意力时,键(key
主要介绍Pytorch分布式训练代码以及原理以及一些简易的Demo代码是指将一个模型的不同部分(如层或子模块)分配到不同的设备上运行。它通常用于非常大的模型,这些模型无法完整地放入单个设备的内存中。在模型并行中,数据会顺序通过各个层,即一层处理完所有数据之后再传递给下一层。这意味着,在任何时刻,只有当前正在处理的数据位于相应的设备上。是一种特殊的模型并行形式,它不仅拆分模型的不同层,还将输入数据流