




- @weixin_44904816
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
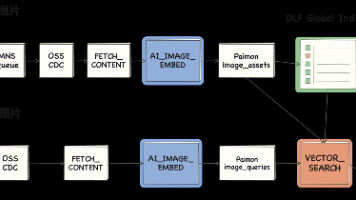
随着商品图、设计素材、工业图片和业务影像持续增长,企业需要解决的已经不只是"图片存在哪里",更重要的是如何持续发现、理解和使用这些非结构化数据。图片进入 OSS 后,可以自动完成发现、向量化和入湖;图片元数据与向量统一保存在 Paimon 表中,减少多套存储之间的数据同步;DLF Global Index 持续维护向量索引,让新增图片逐步进入检索体系;可以直接基于 Paimon 表构建相似商品推荐
本文由潘伟龙(阿里云可观测)、阮孝振(阿里云开放平台)撰写,介绍阿里云OpenAPI网关实时监控体系的构建实践。面对TB级日志、多维分析、秒级告警等挑战,采用Flink+SLS云原生方案,创新分层聚合+Source端谓词下推,实现60+地域、300+产品、200TB/日的高可用实时监控,故障发现从分钟级降至秒级。

Apache Flink Agents 0.2.0发布!该预览版统一流处理与AI智能体,支持Java/Python双API、Exactly-Once一致性、多级记忆(感官/短期/长期)、持久化执行及跨语言资源调用,兼容Flink 1.20–2.2,助力构建高可靠、低延迟的事件驱动AI应用。

Apache Flink 社区很高兴地宣布发布 Apache Flink Agents 0.2 系列的首个缺陷修复版本。此版本包含 3 项缺陷和漏洞修复以及一些对Flink-Agents 0.2的小幅改进。下面列出了所有缺陷修复和改进内容(不包括构建基础设施和构建稳定性方面的改进)。。我们强烈建议所有用户升级到 Flink-Agents 0.2.1。

Apache Flink CDC 3.6.0 正式发布!支持 Flink 1.20.x/2.2.x 与 JDK 11,增强端到端 Schema Evolution(MySQL/PostgreSQL 入湖入流),新增 Oracle Source 与 Hudi Sink 连接器,全面覆盖主流数据湖生态,并优化 Transform 框架、YAML 路由及多连接器能力。(239字)

Apache Flink Agents 是 Apache Flink 新晋子项目,专注构建事件驱动的流式 AI Agent。0.3 版本 roadmap 已公布:支持 Agent Skills 集成、Mem0 长期记忆、跨语言 Action/Events、Python 3.12、日志分级与可观测性增强等,目标打造生产级流式 Agent 框架。

阿里云实时计算 Flink 提供了 AI 助手能力:在控制台右下角点击悬浮按钮,即可打开 AI 助手,用自然语言描述你的同步需求——例如"请生成一个Flink CDC YAML 作业,我需要把MySQL 中 order_db 开头的数据库中的订单分表同步到 DLF Paimon,Paimon 表按日期字段 date_col 分区,数据需要通过 is_deleted 字段过滤已删除的订单,请根据严格
我认为这个案例最值得看的地方,不是“替换了哪些组件”,而是它背后的系统诉求:实时链路越长,状态管理、多流 join、湖仓同步、排障和运维成本都会上升。但从 GitHub 合并记录看,Flink 社区开发并没有放慢,重点仍在基础设施、对象存储、Table / SQL、PyFlink 和 Web UI 这些长期影响生产体验的方向上。这些 PR 合在一起看,Fluss 4 月不是只在做核心引擎,而是在补
当数据形态从单一的结构化表格,拓展至图片、视频、音频及高维向量等多元模态,传统数据架构要如何打破“数据孤岛”,实现跨模态数据的统一存储、实时检索与智能分析?StarRocks × Paimon × Fluss 给出的答案,正在定义 AI 时代数据底座的进化方向——从传统的结构化数据湖,迈向支持全模态、低延迟、高吞吐的“智能湖仓”。StarRocks Core Committer 及阿里云资深技术专
过去很长一段时间里,数据处理系统主要围绕结构化记录展开:订单、日志、点击、交易、指标、维表、事实表。数据被抽象成一行行 schema 清晰的记录,核心任务是清洗、关联、聚合、统计。这类链路支撑了搜索、BI、风控、推荐、广告等大量传统业务,也塑造了我们对数据工程的默认想象:数据处理首先是对结构化字段的加工。在 AI 时代,模型让应用具备了理解文本、图片、音频、视频和向量语义的能力,也让越来越多业务链